1. 파일 시스템
1) 파일시스템의 요소
◎ 파일 시스템의 구성요소
파일 시스템(file system)은 운영체제의 주요 구성요소로서 파일 시스템에는 일반적으로 네 가지 요소가 포함된다.
첫째 : 파일에 저장되어 있는 데이터에 접근하는 방식에 관련되는 액세스 방식(access method)
둘째 : 파일에 저장․참조․공유할 수 있도록 하며 안전하게 보호될 수 있도록 하는 기법을 제공하는 파일 관리(file management)
셋째 : 보조기억장치에 파일을 저장하는데 필요한 공간을 할당하는 일과 관계되는 보조기억장치관리(auxiliary storage management)
넷째 : 파일의 정보가 소실되지 않도록 보장하는 일에 관계되는 파일의 무결성 유지(file integrity mechanism)
파일 시스템은 보조기억장치 중에서 특히 디스크 장치를 관리하는 일과 관계 합니다.
수천 명의 사용자 집단에 의해 사용되는 100대 정도의 동시 사용 가능 터미널을 지원하는 대규모 시분할 시스템을 가정해 봅시다.
STEP 1. 이 시스템은 어떤 상태일까요?
- 각 사용자는 여러 개의 프로젝트에 대한 각 작업 내용을 여러 개의 계정(account)을 가질 수 있으며, 각 계정은 또한 여러 개의 파일을 가질 수 있습니다.
- 파일에는 크고 작은 갖가지 형태의 파일이 있을 수 있습니다.
- 대형 시분할 시스템에서는 한 사용자 계정이 10~100개의 파일을 가질 수 있는 것이 보통입니다. 따라서 수천 명의 사용자가 쓰는 시스템 디스크는 50,000~100,000개 이상의 파일을 가지게 되며, 응답시간을 줄이기 위해 신속한 액세스가 요구됩니다.
STEP 2. 이 가정상황에서는 어떠한 파일 시스템을 구성해야 할까요?
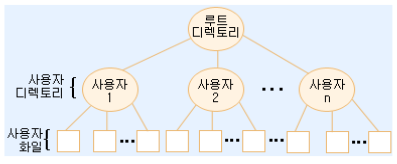
- 2단계 계층구조 파일 시스템이 필요합니다.
- 루트는 디스크의 루트 디렉토리가 시작되는 위치를 가리킵니다.
- 루트 디렉토리는 여러 개의 사용자 디렉토리를 가지며, 각 사용자 디렉토리는 그 사용자의 각 파일당 하나의 항목을 갖고, 각 항목은 디스크상에 파일이 저장되어 있는 실제 위치를 가리킵니다.
- 파일의 이름은 주어진 사용자 디렉토리 내에서만 유일하면 되지만, 한 파일의 시스템 이름은 파일 시스템 내에서 유일해야 합니다.
- 계층구조 파일 시스템(hierarchically structured file system)에서는 파일의 시스템 이름은 일반적으로 루트 디렉토리로 부터 그 파일에 이르는 경로이름(path name)으로 구성됩니다.
2) 파일 시스템의 기능
․일반적인 파일시스템이 담당하는 기능은 다음과 같습니다.
1) 사용자가 파일을 생성하고, 수정하며, 제거할 수 있도록 합니다.
2) 적절한 제어방식을 통해 타인의 파일을 공동으로 사용할 수 있도록 하며, 타인의 작업을 활용할 수 있게 합니다.
3) 파일 시스템의 파일 공유기법은 판독 액세스(read access), 기록 액세스(write access), 수행 액세스(execute access) 또는 이들을 여러 형태로 조합한 것 등 여러 종류의 액세스 제어방법을 제공합니다.
4) 사용자가 각 응용에 적합한 구조로 파일을 구성할 수 있도록 합니다.
5) 사용자가 정보간의 전송명령을 내릴 수 있게 합니다.
6) 물의의 사고로 인한 정보의 손실이나 고의적인 정보의 파괴를 방지하기 위해 예비(backup)과 복구(recovery) 능력을 갖추어야 합니다.
7) 사용자가 물리적인 장치 이름(physical device name)을 사용하는 대신에 기호화된 이름(symbolic name)을 사용하여 자신의 파일을 참조할 수 있도록 합니다.(즉, 장치와의 독립성(device independence)
8) 정보가 안전하게 보호되고 비밀이 보장되어야 하는 상황, 즉 전자 자금 전송 시스템․범죄기록 시스템․의료기록 시스템 등에서 파일시스템은 정보를 암호화(encryption)하고 해동(decryption)할 수 있는 능력을 갖추어야 합니다. 그리하여 암호 해독 키(decryption key)를 소유하고 있는 일정한 사용자만이 그 정보를 이용할 수 있도록 합니다.
9) 파일 시스템이 제공해야 하는 가장 중요한 것은 사용자 편의 인터페이스(user-friendly interface)입니다. 파일 시스템은 이용자의 데이터와 이들 데이터에 대해 수행될 수 있는 작업에 대한 물리적 뷰(physical view)가 아닌 노리적 뷰(logical view)를 제공합니다. 따라서 사용자는 데이터가 저장되어 있는 특정장치, 데이터의 기억형태, 데이터의 전송방식 등에 대해 신경 쓸 필요가 없습니다.
3) 파일시스템의 데이터 계층구조
․일반적인 파일시스템의 데이터 계층구조는 다음과 같습니다.
| 순서 | 명 칭 | 내 용 |
| 1 | 비트(bit) | *컴퓨터에 있어 자료기억의 가장 기본단위는 비트(bit)입니다. *컴퓨터로 자료를 처리할 경우 모든 자료는 2진수 0과 1인 비트로 구성됩니다. *한 비트는 0 또는 1의 값을 가질 수 있으므로 참과 거짓의 두 가지 사항만을 구별할 수 있습니다. *비트를 여러 개 모아서 비트 패턴(bit pattern)을 만들어 컴퓨터 시스템에서 처리할 거의 모든 자료를 표현합니다. *n개의 비트로는 2n개의 비트 패턴을 만들 수 있습니다. |
| 2 | 바이트(byte) or 문자(charactr) | *자료의 계층구조에서, 비트 다음의 상위 계층은 고정 길이의 비트 패턴인 바이트(byte) 또는 문자(character)입니다. *오늘날 대부분의 컴퓨터는 8비트로 한 바이트를 구성하므로 이들 컴퓨터의 문자 세트는 2의 8제곱수인 256의 문자를 표현할 수 있습니다. *각 비트 패턴마다 이들이 나타내는 문자를 지정한 것을 문자 세트(character set)라고 합니다. *요즈음 가장 보편적으로 사용되고 있는 문자 세트는 ASCII와 EBCDIC입니다. *ASCII(American Standard Code for Information Interchange)는 개인용 컴퓨터․마이크로 컴퓨터․미니 컴퓨터․데이터 통신 시스템 등에 많이 사용되며, EBCDIC(Extended Binary Coded Decimal Interchange Code)는 범용 컴퓨터 시스템 내에서 데이터를 표현할 때 주로 쓰이고 있습니다. |
| 3 | 필드(field) | *하나의 필드(field)는 서로 관련 있는 문자들을 모아 놓은 것입니다. |
| 4 | 레코드(record) | *레코드(record)란 그 키가 포함된 레코드를 유일하게 식별하는 데 사용되는 제어 필드(control field)입니다. *예를 들어, 위의 학생의 주소 레코드에서는 학번이 키가 될 수 있을 것입니다. |
| 5 | 파일(file) | *파일(file)이란 서로 연관 있는 레코드의 집단을 말합니다 *예를 들면 대학의 학생 파일은 각 학생마다 하나의 레코드를 가질 수 있습니다. |
| 6 | 데이터 베이스(database) | *데이터 계층구조에서 가장 높은 계층이 데이터 베이스(database)입니다. *데이터 베이스는 서로 관련 있는 파일로 구성됩니다. |
4) 블록킹과 버퍼링
(1) 블록킹
․물리적 레코드(physical record) 혹은 블록(block)은 장치에 출력되거나 장치로부터 입력되는 실제정보의 단위이며, 논리적 레코드(logical record)는 사용자의 관점에서 한 단위로 취급되는 자료의 집단이다.

․고정길이 레코드(fixed-length record)로 구성된 파일에서는 모든 레코드의 길이가 같으며 블록의 크기는 일반적으로 레코드 크기의 정수배이다.
․가변길이 레코드(variable-length record)된 파일에서의 레코드는 길이가 다양하며 최대 크기는 블록의 크기이다.
※일반적인 레코드의 형식

(2) 버퍼링
․버퍼링(buffering)을 이용한 입출력의 병행처리가 가능하다.
․주기억 장치에 파일의 물리적 블록 여러 개를 동시에 저장할 수 있는 기억공간을 다수 마련하여 이들 각각을 버퍼(buffer)라 한다.
․가장 일반적인 기법은 이중 버퍼 사용(double buffering)으로 출력시 아래와 같이 작동한다.
*2개의 버퍼가 있으며, 먼저 현재 수행중인 프로세스가 생성하는 레코드들을 첫째 버퍼가 가들 찰 때까지 넣는다.
*첫째 버퍼가 차면 보조기억장치로 이 버퍼에 기록된 블록의 전송이 시작됩니다.
*이때 프로세스는 계속 레코드를 생성하며 이들 레코드는 비어있는 둘째 버퍼에 기록됩니다.
*이처럼 두 버퍼가 번갈아서 사용함으로써 프로세스가 생성하는 레코드의 입출력과 프로세스의 계산을 병행 처리할 수 있습니다.
2. 파일구조 및 액세스 방식
1) 파일구조
․파일 구조(file organization)는 파일을 구성하는 레코드들이 보조기억장치에 배치되는 방식을 말한다.
◎ 파일구조방식
․요즘 널리 사용되고 있는 파일 구조 방식은 아래와 같다.
| 순차파일 | *순차 파일(sequential file)은 레코드가 물리적 순서에 따라 저장되어 있는 것을 말한다. *‘다음’레코드는 실제로 현재의 레코드 바로 뒤에 저장되어 있는 레코드를 의미하며 이러한 구조는 물리적으로 순차적 성질을 가진 자기 테이프에 가장 많이 이용된다. |
| 인덱스 된 순차파일 | *인덱스 된 순차 파일(indexed sequential file)은 레코드가 각 레코드의 키에 따라서 논리적 순서대로 배열되어 있는 것을 말한다. *시스템은 일부 주요 레코드의 실제 주소가 저장된 인덱스를 관리하며 인덱스 된 순차 레코드는 키 순서에 의해 순차적으로 액세스 될 수도 있고, 시스템에 의해 생성된 인덱스의 검색을 통해 직접 액세스 될 수도 있다. *인덱스 된 순차파일은 보통 디스크에 저장된다. |
| 직접 파일 | *직접 파일(direct file)은 레코드가 직접 액세스 기억장치(DASD:Direct Access Storage Device)의 물리적 주소를 통해 직접 액세스 되는 파일이다. *사용자는 특정 응용에 적합한 순서대로 레코드를 DASD에 기억시팁니다. *파일을 이와 같은 방식으로 구현하려면 사용자는 그 파일을 저장할 DASD의 상세한 물리적 구조에 대한 지식이 있어야 한다. |
| 분할된 파일 | *분할된 파일(partitioned file)은 여러 개의 순차 서브 파일(sequential subfile)로 구성된 파일이다. ※분할된 데이터 집합 혹은 파일  *이 파일을 구성하는 각각의 순차 서브 파일을 멤버(member)라고 한다. *각 멤버의 시작조소는 파일의 디렉토리(directory)에 저장된다. *이러한 구성방식은 프로그램 라이브러리(program library)나 매크로 라이브러리(macro library)를 저장할 때 사용된다. *볼륨(volume)이란 각 보조기억장치에 사용되는 기억매체를 일컫는다. *예)테이프 구동장치에 쓰이는 볼륨을 자기 테이프 릴(reel)이며, 디스크 구동장치에 쓰이는 볼륨은 디스크 팩(disk pack)이다. |
2) 파일 액세스 방식(접근방식)

3. 디스크 공간할당
1) 디스크 공간할당의 문제점
(1) 디스크 공간할당의 문제점
․가변분할 다중 프로그래밍 시스템(variable partition multiprogramming system)에서 주기억장치를 할당하고 회수하는 일과 마찬가지로 자기 디스크의 공간도 할당되고 회수되어야 한다.
․파일을 연속된 디스크 공간에 저장하기 위해서는 그 파일 크기의 공간을 마련해야 하며, 기억공간을 할당하고 회수하는 작업을 거듭함에 따라 디스크 기억공간은 점차 단편화(fragmentation)하므로, 할당을 계속할 경우에는 파일이 널리 퍼져 있는 블록들에 분산 저장된다.
(2) 디스크 공간할당의 해결책

| 파일 시스템 설계에서 고려할 사항 | *파일 시스템을 설계할 때에는 사용자의 수, 각 사용자당 파일의 평균 개수, 컴퓨터에 한 번 연결할 수 끝날 때까지의 평균 1회사용(session)시간, 시스템에서 수행될 응용의 특성 및 기타 여러 요인 등의 이용자 집단에 대한 지식 등을 가지고 이를 면밀히 검토하여 파일의 구조와 디렉토리의 구조를 결정해야 합니다. |
| 기억장치 시스템에서의 국부성 개념 | *가상기억장치 시스템에서 국부성(locality) 개념을 생각하면, 한 파일의 데이터를 연속된 기억공간에 저장하는 것도 바람직할 방법일 수도 있습니다. *정보를 찾기 위해 파일을 탐색하는 사용자는 후속 레코드나 이전의 레코드를 찾기 위해 자주 파일조사(file scan) 명령을 사용하게 도니데, 이러한 조사는 탐색시간을 최소한으로 줄일 수 있습니다. |
| 페이지 시스템 | *페이지 시스템에서는 주기억장치와 보조기억장치 사이의 데이터 전송 최소단위가 페이지이므로 보조기억장치를 페이지와 같은 크기의 블록이나 또는 페이지의 정수배 크기의 블록으로 할당하는 것이 좋습니다. *국부성 개면에 따르면 한 프로세스가 한 번 어느 페이지내의 자료를 참조하면 다음에 참조할 자료는 역시 그 페이지에 있을 연속된 페이지의 데이터를 참조할 확률이 높습니다. *사용자의 가상기억공간에는 논리적으로 연속된 페이지를 보조기억장치에 물리적으로 연속되게 저장하는 것이 바람직합니다. |
2) 연속할당
(1) 연속할당기법
․파일이 보조기억장치의 연속된 공간을 할당 받게 되는 것을 연속할당(contiguous allocation) 기법이라 한다.
․사용자는 만들려는 하는 파일을 저장할 공간의 크기를 미리 정해 주어야 한다.
․만약 보조기억장치의 남아 있는 기억 공간들 중에서 그 크기보다 큰 연속된 기억공간이 없을 경우에는 그 파일은 생성될 수 없다.
(2) 연속할당기법의 장점
․논리적으로 연속된 레코드들이 물리적으로 서로 밀접하게 보조기억장치에 저장되므로, 논리적으로 연속된 레코드들이 전체 디스크에 퍼져 있는 경우보다는 액세스 시간이 훨씬 감소된다.
․디렉토리는 각 파일의 시작주소와 파일의 길이만을 유지하면 되므로 파일의 디렉토리를 구현하기가 수월하다.
(3) 연속할당기법의 단점
․파일이 디스크에서 제거되면 그 파일이 차지하고 있던 기억공간은 회수되어 다른 파일을 저장하는데 사용된다.
․새로 생성되는 파일의 크기가 전에 저장되어 있던 파일의 크기와 같지 않을 경우가 대부분이므로 가변분할 다중 프로그래밍 시스템에서의 단편화와 같은 문제, 즉 보조기억장치내의 인접한 빈 공간을 합병해야 하는 문제가 발생하며 새로운 파일을 넣을 수 있을 만큼 큰 기억장소를 만들기 위해 주기적으로 집약(compaction)을 해야한다.
․파일의 크기가 시간이 지남에 따라 커지거나 작아지는 경우 역시 연속할당이 어렵다.
-사용자는 파일의 크기가 증가할 경우에 대비하여 실제 파일이 필요한 크기보다 훨씬 많은 기억공간을 요구하게 되므로 기억공간이 낭비되는 경우가 많기 때문이다.
-만약 할당한 기억공간보다 파일의 크기가 커지는 경우에는 글 파일을 저장할 수 있는 다른 기억공간으로 옮겨야 하는 불편이 있다.
3) 불연속할당

(1) 연결을 이용한 섹터단위 할당
| 리스트 | *디스크는 각 섹터(sector)의 집합으로 볼 수 있다. *파일은 디스크상에 분산되어 있는 여러 개의 섹터가 모여 구성되며, 동일 파일에 속하는 섹터들은 다른 섹터를 가리키는 포인터를 가지고 있어 파일은 하나의 연결된 리스틀 이룬다. *비어 있는 섹터들은 전부 연결되어 하나의 자유공간 리스트(free space list)를 형성한다. |
| 파일 확장과 축소 | *파일을 더 확장할 필요가 있을 때 프로세스는 자유공간 리스트에 추가의 섹터를 요구하고 파일을 축소할 때에는 섹터를 자유공간 리스트에 되돌려 준다. *따라서 집약(compaction)이 필요 없다. |
| 불연속 할당의 기법의 단점 | *불연속 기억공간 할당기법은 연속할당이 갖고 있는 여러 문제를 해결하긴 하였으나 역시 여러 가지 단점을 안고 있다. *우선 파일이 디스크상에 분산되어 적재되어 있으므로 논리적으로 연속되어 있는 레코드들을 검색할 경우에는 상당히 긴 탐색시간이 필요하다. *연결된 리스트 구조를 관리하기 위한 실행시간중의 추가비용이 필요하며, 링크에 사용되는 포인터가 차지하는 공간에 의해 실제 데이터가 저장될 공간이 감소된다. |
(2) 연속할당
․블록 할당은 보조기억장치를 보다 효율적으로 관리하고 실행기간중의 추가비용을 줄이기 위한 기억장소 할당기법 이다.
․이 기법은 연속 할당과 불연속 할당기법의 절충형이라고 볼 수 있다.
․이 기법에서는 하나하나의 섹터를 할당하는 대신에 연속되는 섹터로 구성된 블록(때로는 extent라고도 함)을 할당한다. 시스템은 현재 파일이 저장되어 있는 블록으로부터 가장 가까운 거리에 있는 블록을 선택하여 그 파일에 추가 할당한다.
․매번 파일을 액세스할 때에는 해당 블록을 결정한 후에 다시 해당 섹터를 결정해야 한다.
(3) 블록할당을 구현하는 방법
블록 체인기법 (block chaining)
․블록 체인기법(block chaining)에서 사용자 디렉토리의 각 항목은 각 파일의 첫째 블록을 가리키는 포인터이며, 파일을 구성하는 고정길이의 각 블록들은 데이터 블록과 다음 블록을 가리키는 포인터를 포함하고 있다.
․할당의 최소단위는 대개 여러 개의 섹터로 구성된 하나의 블록이다.
일반적으로 디스크의 한 트랙 전체를 한 블록의 크기로 정한다.
․특정 레코드를 찾을 때에는 블록 체인을 따라가며 해당 블록을 찾아내고 그 블록 내에서 다시 해당 레코드를 찾아낸다. 체인은 반드시 처음부터 탐색해야 하며 만약 블록이 디스크에 분산되어 있으면(일반적으로 분산되어 있음) 블록 체인을 따라가며 탐색하는 작업은 상당한 탐색시간이 소모되어 속도가 느리다.
․삽입과 삭제는 간단합니다. 이는 앞의 블록에 있는 포인터만 변경하며 되기 때문이다. 어떤 시스템에서는 탐색을 쉽게 하기 위해 블록을 이중 연결 리스트(double-linked list)로 연결함으로써 전후로 탐색할 수 있도록 하고 있다.
인덱스 블록 체인기법 (index block chaining)
․인덱스 블록 체인 기법(index block chaining)에서는 포인터가 별도의 인덱스 블록에 모여 있다. 각 인덱스 블록에는 일정수의 항목이 있으며 각 항목에는 레코드 식별자와 그 레코드를 가리키는 포인터가 들어 있다.
․만약 하나의 인덱스 블록으로 한 파일을 전부 나타낼 수 없을 때는 여러 인덱스 블록을 체인으로 연결하여 사용한다.
․단순한 블록 체인 기법에 비해 이 인덱스 블록 체인 기법이 갖는 큰 장점은 탐색이 인덱스 블록 자체 내에서 이루어진다는 점이다.
․탐색시간을 줄이기 위해 인덱스 블록들을 보조기억내의 인접한 곳에 위치시키는 것이 좋다. 빠른 탐색을 요하는 일부 시스템에서는 인덱스 블록들을 주기억장치 안에 두기도 한다.
․인덱스 블록을 통해 해당 레코드를 찾으면 그 레코드가 포함되어 있는 데이터 블록이 주기억장치로 옮겨지게 된다.
․이 기법의 단점은 삽입하고자 할 때 인덱스 블록을 완전히 재구성해야 하는 데 있다.
․어떤 시스템은 삽입할 경우에 대비하여 인덱스 블록에 여분의 공간을 남겨 두기도 하지만 그 여분의 공간을 다 소비하게 되면 역시 인덱스 블록의 구조를 다시 재구성해야 할 필요가 있다.
블록 지향 파일 사상기법 (block oriented file mapping)
․블록 지향 파일 사상 기법(block-oriented file mapping)에서는 포인터 대신 블록의 번호를 사용한다. 일반적으로 디스크의 구조적 특성에 의해 이 블록 번호는 쉽게 블록의 실제주소로 변환된다.
․디스크의 각 블록에 대해 하나의 항목이 파일 사상표(file map)에 들어 있다.
사용자 디렉토리의 각 항목은 각 파일에 대한 파일 사상표의 첫째 항목을 가리키고 있으며, 파일 사상표의 각 항목에는 그 파일에 속한 다음 블록의 블록 번호가 기록되어 있다. 그러므로 한 파일의 모든 블록은 파일 사상표의 항목들을 따라가며 찾을 수 있다.
․파일 사상표의 항목 중 특정파일의 마지막에 해당하는 항목은 파일의 마지막에 도달했음을 알리기 위해 nil'과 같은 값으로 채운다. 파일 사상표의 어떤 항목은 해당 블록이 할당 가능한 비어 있는 블록임을 표시하기 위해 비었음이라고 기록되어 있다.
․시스템은 비어 있는 블록(free block)을 찾아내기 위해 파일 사상표를 차례로 탐색하는 방법을 쓰기도 하고 따로 비어 있는 블록 리스트(free block list)를 만들기도 한다.
․파일 사상표에 레코드 식별자를 포함시켜 탐색이 대부분의 경우 사상표에 한정되게 할 수도 있다. 이 기법이 갖는 진정한 장점은 디스크로 물리적 인접성을 그대로 파일 사상표에 반영할 수 있다는 점이다.
․새로운 블록을 찾아내는 거도 용이하며, 삽입과 삭제 역시 간단히 이루어질 수 있다.
※ 구현 모형



4) 피일서술자

(1) 파일 제어 블록
․파일 제어 블록은 보조기억장치에 두고, 파일이 개발될 때 주기억장치로 옮기는 것이 일반적이다.
․파일제어블록은 파일 시스템이 관리하므로 사용자가 직접 참조할 수는 없다.
(2) 파일 제어 블록에 포함되는 내용

4. 접근 제어
1) 접근 제어 행렬
․ 접근제어 행렬(access control matrix): 파일의 접근을 제어하는 한 기법으로 이용되고 있다.

(2) 접근제어 행렬의 특징
․행렬에는 시스템내의 모든 이용자와 모든 파일이 나열되어 있으며 행렬의 원소 Aij가 1이면 이는 사용자 i는 파일j를 액세스 할 수 있음을 뜻하고, 0이면 액세스할 수 없음을 의미한다.
․많은 사용자와 많은 파일을 가진 큰 시스템에서는 제어행렬의 크기가 매우 커지고 희소행렬(Sparse Matrix)이 될 가능성이 커진다. 한 사용자의 파일을 타인이 액세스하는 일은 드물기 때문이다.
․이러한 행렬개념을 유용하게 쓰려면 판독만 가능 (read-only), '기록만 가능(write-only), '실행만 가능(execute-only), '판독/기록 (read/write)등의 여러 종류의 접근을 나타내는 코드를 사용해야 한다.
2) 사용자 집단별 접근제어
(1) 사용자 집단별 접근제어의 필요성
․접근 제어행렬은 실제 관리하기 힘들 정도로 행렬의 크기가 커지기 쉽다.
․따라서 기억장소를 훨씬 덜 차지하는 기법으로는 사용자 집단별 접근 제어 기법 (access control by user classes)등이 사용된다.
(2) 사용자 집단을 구분하는 기준
․일반적으로 사용자 집단을 구분하는 기준은 다음과 같다.
첫째 : 파일을 만든 사람이 파일의 소유자(owner)
둘째 : 소유자가 자신의 파일을 사용해도 좋다고 명시한 지정된 사용자(specified user)
셋째 : 특정 프로젝트에 참여하는 구성원일 경우가 많으므로 이들 구성원 모두에게 그 프로젝트에 관계된 다른 구성원의 파일을 참조할 수 있도록 하는 집단(group)
넷째 : 대부분의 시스템에서는 파일을 공용으로 선언하여 시스템의 모든 사용자가 단지 판독과 실행만을 할 수 있도록 하는 공용(public)
5. 백업과 복구
1) 백업의 필요성
․디스크가 파손되거나 번개가 치거나 전원이 동요되거나 화재․홍수 등의 천재지변 또는 도둑의 침입 또는 고의적인 파괴행위 등으로 말미암아 정보가 손실되고 파괴될 수 있다.
․정보의 손실은 고의적이든 아니든 발생 가능성이 있으므로 일반적으로 운영체제나 특히 파일 시스템은 이러한 불의의 사고에 대처하기 위해 정보의 백업(backup)이 요구된다.
․컴퓨터실의 불법 접근을 통제하고, 전원의 동요를 방지하고 화재 시에 소화장치를 작동시키는 일은 물리적 안전장치를 이용하여 해결할 수 있으나 판독/기록 헤드가 디스크면에 닿아 디스크를 긁어서 발생하는 디스크 헤드 파괴(disk head crash)로 인해 디스크 팩을 망가뜨릴 수도 있다.
2) 데이터를 유용하게 보존하는 기법
(1) 데이터를 유용하게 보존하는 기법
․주기적 백업(periodic backup)
-주기적으로 시스템의 파일을 하나 이상 복사하여 안전한 곳에 보관하는 주기적 백업은 이러한 위험을 방지하는 가장 일반적인 기법이다.
-그러나 주기적으로 백업을 한다 하여도 최종 백업 후에 이루어진 파일의 갱신 내용은 잃게 된다.
․다른 디스크에 한 파일에 대한 모든 트랜잭션을 기록(log all transaction)하여 저장하는 방법
-중복성(redundancy)은 상당한 비용이 소요되지만 데이터가 손실․파괴될 경우에는 현재까지 수행한 작업을 재건할 수 있다.
-물론 작업 기록용 디스크(logging disk)는 파괴되지 않음을 가정해야 한다.
(2) 파일의 안정성을 보장하기 위해 설계자가 할 일
․파일의 절대적 안전을 보장할 수 없으므로 설계자는 시스템의 성능을 감소시키지 않으면서, 감당할 만한 비용으로 파일을 보호할 수 있는 백업 기능을 마련해야 한다.
․데이터의 온전성이 고도로 신뢰할 수 있을 정도로 보장되어야 하는 상황에서는 설계자는 비용과 시간의 소모가 상당한 백업 프로시저를 마련해야 한다.
․최악의 경우에 사용자는 마지막 백업 이후의 모든 처리내용을 다시 작성해야 한다.
3) 주기적 백업
(1) 주기적 백업의 단점
․백업 작업 시에 시스템은 다른 작업을 중단해야 하며, 파일 시스템은 매우 클 수도 있으므로 이 경우 전체 백업은 상당히 많은 시간을 소모하게 되고, 잘못(failure)이 발생한 경우 최종 백업으로부터의 회복은 상당한 시간을 요하는 작업으로서 회복이 끝난 후의 데이터는 최종 백업 당시의 데이터이며 그 후의 트랜잭션(transaction)은 손실된다는 점이다.
(2) 주기적 백업을 통해 얻는 이점
․주기적 백업을 하는 동안에 디스크 전체에 널리 산재해 있는 사용자 파일들을 연속된 공간에 배치하여 다시 재구성할 수 있기 때문에 시스템이 다시 작업을 시작한 후 이용자 파일에 대한 액세스가 매우 빠른 속도로 처리될 수 있다는 것이다.
4) 증가식 백업
◎증가식 백업의 특징
․신속하고 가장 최근의 작업까지 회복해야 하는 시스템에서 파일 시스템 전체를 주기적으로 백업하는 것으로는 충분하지 않다.
․보다 적절한 방법은 증가식 백업(incremental backup) 이다.
․이는 터미널 작업을 하는 도중에 갱신된 파일을 전부 표시해 두었다가 사용자가 터미널 작업을 끝냈을 때 이들의 리스트를 시스템 프로세스로 보내어 시스템 프로세스가 이 갱신된 파일을 전부 백업하는 방법이다.
5) 갱신된 파일을 자주 덤프 하는 방법
․사용자 터미널의 작업시간이 긴 경우에는 작업 도중에 시스템 고장(system crash)이 발생할 수도 있으므로 증가식 백업이 널리 이용되지는 않는다.
․이를 보완하는 방법으로는 사용자가 터미널 작업을 하는 도중에도 파일 디렉토리를 검색하여 갱신된 파일을 보다 자주 덤프 하는 방법이 있다.
6) 트랜잭션 로깅 기법
․작업내용에 대한 어떠한 손실도 용납할 수 없는 시스템에서는 트랜잭션 로깅(transaction logging)기법이 적합하다. 이 기법에서는 모든 트랜잭션이 발생함과 동시에 백업된다.
․이러한 고도의 백업 수준은 작업자에 의한 비교적 늦은 응답시간으로 인해 활동내용이 한정되는 대화형 시스템에서 다소 쉽게 사용할 수 있다.
․수백 명의 온라인 대화형 사용자를 지원하는 시스템이라 해도 터미널에서 입력되는 하나하나의 행을 기록할 수 있으며 따라서 이러한 시스템은 가장 최신의 작업내용까지를 백업할 수 있다.
․대화형 명령이 입력될 때마다 백업을 해야 하므로 처리하는 데 많은 양의 작업을 수행해야 하며 필요한 복구작업을 위해서는 장시간의 재구성 시간이 필요할 것이다.
6. 파일서버와 분산 파일 시스템
․컴퓨터 네트워크에서 비국부적인 파일 참조들을 다루기 위한 한가지 방식은 그러한 요구들을 모두 파일서버(file server; 컴퓨터 상호간의 파일 참조를 해결하기 위해 만들어진 컴퓨터 시스템)에 맡기는 것입니다.
․이 방식은 이러한 참조들에 대한 제어를 집중화 시키지만 모든 클라이언트(client) 컴퓨터들이 파일서버에게 모든 요구를 하게 되어 파일서버가 쉽게 병목현상(bottle neck)에 이르게 됩니다.
․이보다 더 좋은 방법은 각각의 컴퓨터들이 서로 직접 통신할 수 있게 하는 것입니다. 이러한 방법은 Sun사의 NFS(Network File System)에서 사용되었습니다. 이 시스템 하에서는 각각의 컴퓨터들이 서버/클라이언트(Server/client) 처럼 행동하게 됩니다.
․한편으로 1970년대까지만 해도 파일 시스템들을 주로 단일 컴퓨터 시스템의 파일들을 저장하고 관리했으면, 다중 사용자 시분할 시스템에서는 모든 사용자의 파일들은 중앙 파일 시스템의 제어 하에 있었습니다.
․오늘날의 경향은 컴퓨터 네트워크를 통한 분산 파일 시스템(distributed file system)을 지향하고 있습니다. 여기에 따르는 실제적인 어려움은 네트워크가 여러 가지 다양한 컴퓨터 시스템, 특히 서로 다른 운영체제 및 파일 시스템들은 갖는 시스템으로 확장 연결되어 가고 있다는 데 있습니다.
․분산 파일 시스템은 사용자로 하여금 컴퓨터 네트워크상에 있는 멀리 떨어진 파일들을 마치 국부적인 파일들처럼 사용할 수 있도록 해줍니다.
7. 데이터 베이스 시스템
1) 데이터베이스 시스템의 특징
(1) 데이터베이스 시스템
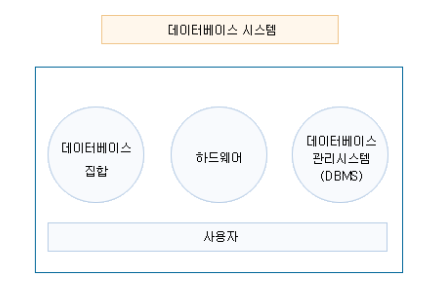
․데이터베이스(database)는 중앙에서 통제되는 데이터베이스의 집합을 말하며, 데이터베이스 이외에 그 데이터가 저장될 하드웨어, 데이터의 저장과 검색을 통제하는 소프트웨어인 데이터베이스 관리시스템(DBMS : Data Base Management System) 그리고 사용자를 통틀어 데이터베이스 시스템 이라고 한다.
(2) 데이터베이스 시스템의 장점과 특성
․데이터베이스 시스템은 일반적인 파일 시스템과 달리 많은 장점과 특성을 갖고 있는데, Date가 열거한 데이터베이스 시스템의 중요한 장점은 다음과 같다.
① 데이터의 중복(redundancey)을 감소시킬 수 있습니다.
*일반적으로 데이터베이스를 사용하지 않는 시스템에서는 각 응용마다 그 응용에 필요한 파일을 별도로 제작하여 사용한다.
*이 파일들 중에는 서로 중복되는 데이터가 많을 뿐 아니라 실제 양식도 다양하다.
*데이터베이스 시스템은 이러한 각 파일들을 종합하여 하나의 데이터베이스로 구성함으로써 중복성을 감소시킨다.
② 데이터의 모순성(inconsistency)을 피할 수 있습니다.
*데이터의 중복이 감소됨에 따라 동일 데이터를 여러 곳에 둠으로써 필연적으로 발생하는 데이터의 모순성을 감소시키거나 피할 수 있다.
*두 항목이 서로 다를 확률이 줄어든다.
③ 데이터의 공유(share)가 가능합니다.
*데이터를 공유할 수 있다는 점이 데이터베이스 시스템의 가장 큰 장점 중의 하나이다.
*기존의 각 응용들은 동일한 데이터를 참조할 수 있으며, 새로운 응용은 기존의 데이터를 사용할 수 있다.
④ 표준화를 강화할 수 있습니다.
*중앙통제에 의해 데이터의 표준화를 보다 엄격히 적용할 수 있다.
*이 점은 시스템 사이에 데이터의 이동(data migration)이 발생하는 컴퓨터 네트워크 시스템에서 특히 중요시된다.
⑤ 보안에 대한 제약(security restriction)을 적용할 수 있습니다.
*보안유지는 데이터베이스 시스템에서 이루어져야 하는 중요한 문제이다.
*데이터가 물리적으로 여러 곳에 분산되어 있을 때보다 중앙에 위치하여 있으므로 위험이 더욱 가중된다.
*이를 방지하기 위해 데이터베이스 시스템은 정교한 통제 하에 설계되어야 한다.
⑥ 데이터의 무결성(integrity)을 유지할 수 있습니다.
*데이터의 보존성은 데이터베이스 시스템 하에서 더욱 잘 지켜질 수 있으며 또한 반드시 지켜져야 한다.
*데이터를 공동으로 사용하므로 부정확하고 불완전한 데이터는 사용자 조직 내에 빠르게 전파되기 때문이다.
⑦ 데이터에 대한 모순되는 요구를 조절할 수 있습니다.
*데이터베이스 기법에 필연적인 중앙통제는 모순된 욕구를 균형 있게 처리 할 수 있게 한다.
*데이터베이스는 조직 내의 모든 요구를 만족시킬 수 있도록 구성되므로 만일 서로 응용으로부터 모순된 요구가 들어왔을 경우에는 전체 데이터베이스 시스템의 내용에 따라 이들을 처리할 수 있다.
(3) 데이터의 독립성
․데이터베이스 시스템에서 가장 중요한 특성 중 하나는 데이터 독립성(data independence) 이다.
․각 응용은 데이터의 물리적 저장방식이나 액세스 방법에는 관여할 필요가 없다.
․응용이 데이터에 의존적(data-dependent)이라 함은 기억장소의 구조와 액세스 기법을 변화시켜 그 응용에 상당히 큰 영향을 주게 됨을 의미한다.
․데이터 독립성은 여러 응용에 대해 동일한 데이터에 대한 각각 다른 뷰(view)를 가질 수 있게 한다.
․시스템의 입장에서도 응용의 기능에 전혀 영향을 주지 않고, 기억장치의 구조와 액세스 기법을 변화하는 요구에 부응하여 변경시킬 수 있다.
2) 데이터베이스 언어
․사용자는 일종의 데이터베이스 언어(database language)를 사용하여 데이터베이스에 접근한다.
․응용 프로그램은 COBOL, PL/I, PASCAL과 같은 통상적인 프로시저 중심의 고급언어를 사용하며 터미널 사용자는 특별히 고안된 질의어(query language)를 사용한다.
․질의어(일반적으로 간단한 영어형태)는 특정 응용에 따라 그 요구를 쉽게 표현할 수 있도록 만들어져 있다. 그러한 언어는 호스트 언어(host language)라고 부른다.
․일반적으로 각 호스트 언어에는 특정 데이터베이스 객체와 조작의 특성에 관련된 데이터 서브 언어(DSL : Data Sub Language)가 포함된다.
․각 데이터 서브 언어는 일반적으로 데이터베이스 객체(database object)를 정의하는 데 쓰이는 데이터 정의어(DDL:Data Definition Language)와 데이터베이스 객체에 대한 수행 가능한 처리내용을 명시하는 기능을 제공하는 데이터 조작어(DML : Data Manipulation Language)로 구성된다.
3) 분산 데이터베이스
(1) 분산 데이터베이스
․네트워크를 통해 데이터가 컴퓨터 시스템 전체에 분산되어 있는 데이터베이스의 형태를 분산 데이터 베이스라고 한다.
․일반적으로 이러한 시스템에서는 각 데이터 항목은 그 데이터가 가장 자주 쓰이는 곳에 위치하며, 다른 곳의 사용자는 네트워크를 통해 액세스가 가능하다.
| 장점 | 단점 |
| 분산 시스템은 국부처리의 통제성과 경제성을 제공함과 동시에 지리적으로 분산된 조직에 대한 정보를 접근할 수 있는 장점을 제공한다. | 이 방법을 구현하고 운영하는 데에는 상당한 경비가 들 뿐 아니라 보안이 침해될 가능성이 증대되는 난점이 있다. |
4) 데이터베이스 모델
(1) 계층 데이터베이스 모델
․계층 데이터베이스 모델(hierarchical database model)에서의 데이터 항목들은 부자관계(parent/child relationship)를 갖는다.

․각 부모는 여러 자식을 가질 수 있으나 한 자식이 여러 개의 부모를 가질 수는 없다.
․한 자식이 여러 부모와의 상호관계가 있는 경우에는 그 관계를 표현하기가 힘들다. 이러한 불편함이 여러 설계자로 하여금 다른 모델을 선택하게 하였다.
․데이터 사이의 관계가 참으로 계층구조에 해당하는 경우에는 이 계층 구조 데이터베이스로 구성하면 구현․수정․탐색 등이 쉽다.
(2) 네트워크 데이터베이스 모델
․네트워크 데이터베이스 모델(network database model)은 계층구조 모델보다 융통성이 크다.
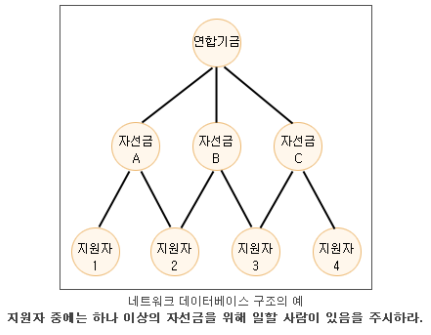
․자식이 여러 부모를 가질 수 있을 뿐만 아니라 일반적 상호관계를 향할 수 있기 때문에 구조가 복잡해지기 쉽다.
․시스템을 이해하거나 수정하기가 어렵고 시스템에 오류가 발생했을 때는 재구성이 힘들다.
․네트워크 구조는 비교적 안정된 환경에서 데이터베이스가 확장될 가능성이 있다거나 새로운 특성 또는 관계가 첨가될 가능성이 있을 때는 네트워크 구조를 피하는 것이 바람직하다.
(3) 관계 데이터베이스 모델
․관계 데이터베이스 모델(relational database model)은 E. F. Codd가 제안한 모델로 최근 들어 대단히 각광을 받고 있다. 관계 모델은 계층구조 모델이나 네트워크 모델보다 많은 장점을 제공한다.
․관계 모델은 물리적 구조라기보다는 논리적 구조이다.
․관계데이터베이스의 관리원칙은 데이터 구조의 물리적 구현을 고려하지 않고서도 편리하게 고찰하여 볼 수 있다.
․관계 데이터베이스는 관계(relation)들로 구성된다.
․각 사용자는 서로 다른 데이터 항목 및 이들 데이터 항목 사이의 서로 다른 관계에 대해 흥미를 갖는다.
․관계를 나타내는 테이블의 전체 열의 한 부분집합만을 원하는 사용자가 있는가 하면 여러 개의 테이블을 조합하여 더욱 다양하고 복잡한 관계를 구성해 보려는 사용자도 있다
․Codd는 부분집합작업을 ‘프로젝션’(projefction), 조합작업을 ‘조인’(join)이라 정의하고 있다.
․앞 그림의 관계를 바탕으로 프로젝션 작업을 적용하여 부서의 위치를 나타내는 새로운 관계부서-소재지(DEPARTMENT-LOCATOR)를 만들 수 있다.

․계층구조와 네트워크 구조를 비교해 볼 때 관계 데이터베이스 구조가 갖는 장점은 다음과 같다.

※ 관계 데이터베이스 구조 이해
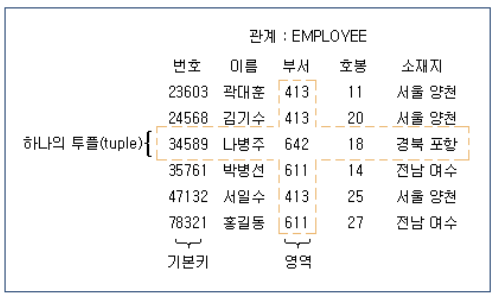
*이 그림은 인사시스템(personal system)에서 사용 가능한 관계들의 예를 보여준다.
*관계의 이름은 EMPLOYEE이다.
*관계를 설정한 목적은 각 고용원의 속성(attribute)과 그 고용원과의 관계(relationship)를 나타내기 위한 것이다.
*관계를 나타내는 한 특정 행(row)을 튜플(tuple)이라고 한다.
*이 그림에서는 하나의 관계가 6개의 튜플로 구성되어 있다. 각 튜플의 첫째 필드(field)는 고용원의 번호이며 이는 이 관계내의 데이터를 참조할 때 기본 키(primary key)로 사용된다.
*이 관계내의 튜플은 기본 키의순으로 정리되어 있다.
*관계의 각 열(column)은 서로 다른 정의역 (domain)을 나타낸다.
*한 관계내의 튜플은 기본 키에 의해 유일하게 결정되나, 특정 정의역의 값은 튜플 간에 중복될 수 있다. 예를 들면, 위의 예에서 3개의 튜플의 각 부서번호는 모두 413이다.
*한 관계의 정의역의 개수가 그 관계의 차수(degree of the relation)를 나타낸다. 차수가 2인 관계를 이진관계(binary relation)이고 차수가 3인 관계를 삼진관계(ternary relation)라 하며, 차수가 n인 관계를 'n-진 관계 (n-ary relation)라고 한다.

'정보과학 > 운영체제특론' 카테고리의 다른 글
| 병렬처리 (0) | 2023.12.09 |
|---|---|
| 네트워크와 분산처리 (1) | 2023.12.09 |
| 입출력관리와 디스크 스케줄링 (1) | 2023.12.03 |
| 가상기억장치의 주소변환과 관리기법 (1) | 2023.12.02 |
| 병행프로세스 (2) | 2023.12.02 |



