1. 컴퓨터 구조의 분류
․Flynn은 자료 흐름(data stream)과 명령어 흐름(instruction stream)을 사용하여 아래와 같이 컴퓨터 구조를 분류하였습니다.
․병렬처리의 개념을 살펴보기에 앞서 컴퓨터 구조에 대해서 살펴보겠습니다.

| SISD | *현재 사용되는 가장 일반적인 구조는 SISD(Single Instruction stream, Single Data stream) 컴퓨터로서 폰 노이만(von Neuman) 방식이다. *한 번에 하나의 명령어만을 수행하는 단일 프로세서 컴퓨터로서 단일 자료 흐름으로부터 자료를 처리한다. |
| SIMD | *SIMD(Single Instruction stream, Multiple Data stream) 컴퓨터는 배열처리기(array processor)라고도 하는데 배열의 각 항목에 대해서 동시에 같은 연산을 수행한다. *때때로 벡터 처리기(vector processor)와 파이프라인 프로세서 (pipeline processor)도 이 범주에 속한다. |
| MISD | *MISD(Multiple Instruction stream, Single Data stream) 컴퓨터는 응용되지 않고 있다. |
| MIMD | *MIMD(Multiple Instruction stream, Multiple Data stream) 컴퓨터는 진정한 의미에 있어서 병렬 프로세서(parallel processor)로서 멀티프로세서(multiprocessor)라고도 불린다. |
2. 병렬처리의 종류
․병렬처리를 위해서는 파이프라인 기법, 백터처리, 배열처리기, 데이터 흐름 컴퓨터, 다중처리기 등이 활용됩니다.
․병렬처리의 종류를 살펴보고 결함허용과 계산 복잡도에 대해서 살펴보겠습니다.
1) 파이프라인 기법
(1) 파이프라인 기법의 개념
․파이프라인 기법(pipelining)은 한 번에 여러 기계어 명령어가 실행단계에 있을 수 있도록 해서 성능을 향상시키는 방법이다.
(2) 파이프라인 기법의 특징
․다단계 파이프라인은 자동차 공장의 조립 라인과 같아서, 명령어 파이프라인의 각 지점에서는 한 명령어에 대해 각각 다른 연산을 수행한다.
․모든 지점은 병렬적으로 수행하므로 파이프라인 기법은 실행의 각각 다른 단계에서 많은 명령어들이 동시에 수행되도록 합니다. 이러한 단계는 전형적으로 명령어 인출(instruction fetch), 피연산자 인출(operand fetch), 명령어 해독(instruction decode), 명령어 실행(instruction execution)등을 포함합니다.
․초기의 컴퓨터는 한번에 하나의 기계어 명령만을 수행했으나 오늘날 파이프라인화된 시스템은 현재 명령어가 실행 중에 다음 명령어가 시작되고 그 명령어가 실행중에 또 다른 명령어가 시작되게 함으로써 여러 명령어들의 수행이 가능하도록 하고 있습니다.
2) 벡터 처리
․파이프라인 기법과 벡터 처리(vector processing)라는 용어의 사용에는 많은 혼란이 있습니다.
◎ 벡터 처리의 특징
․벡터 처리는 기계어에서 특히 벡터 명령어를 요구하며 파이프라인화된 하드웨어를 요구하나 하드웨어가 파이프라인화 되었다고해서 벡터 처리를 하는 것은 아니다.
․벡터 명령어는 수행될 연산을 지시하고 그에 해당하는 피연산자(벡녀라고도 함)의 리스트를 상술한다.
․벡터 명령어가 실행되었을 때 벡터의 각 항복들은 하나씩 적절한 파이프라인에 나뉘어져 파이프라인의 한 단계가 완성되는 동안 연기된다.
․컴파일러는 벡터 처리기가 효율적으로 수행될 수 있도록 프로그램을 벡터화한다.
․Cray-1 벡터 처리기는 병렬적으로 수행하는 13개의 파이프라인을 갖고 있으며 이들은 실수 덧셈, 실수 곱셈, 역수 계산 등을 수행한다.
3) 배열 처리기
(1) 배열 처리기의 개념
․배열 처리기(array processor)는 SIMD 컴퓨터로서 한 배열의 각 항목에 동시에 같은 명령어를 수행하는데, 여러 독립적인 태스크들을 수행해야 하는 환경에서는 사용되지 않는다.
(2) 배열 처리기의 특징
․MPP(Massive Parallel Processor)는 16,384개의 프로세서로 구성된 SIMD 컴퓨터로서 ?초당 60억개 이상의 8비트연산을 수행할 수 있다.
․배열 처리기는 65,536개의 프로세서를 연결한 CM(Connection Machine)으로 까지 발전되었다.
4) 데이터 흐름 컴퓨터
․순차 프로세서에서 한 명령어가 수행된 후에는 프로그램 계수기는 일반적으로 다음에 실행될 명령어를 가리키고 있습니다.
(1) 데이터 흐름 컴퓨터의 개념
․데이터 흐름 컴퓨터(data flow computer)는 많은 연산을 병렬적으로 수행하는데, 요구되는 데이터가 이용 가능한 명령어를 실행하기 때문에 데이터 구동 방식(data driven)이라고 말한다.
․이는 상업적으로 아직 구현되지 않았지만 이미 컴파일러에 도입되어 있으며, 병렬구조에서 최적 실행을 할 수 있도록 프로그램을 준비해 준다.
(2) 데이터 흐름 컴퓨터와 순차 컴퓨터의 비교
․데이터 흐름 컴퓨터가 순차 컴퓨터에 비해 얼마나 수행능력이 우수한가에 대한 예가 다음 그림을 통해 확인할 수 있다.

- 순차 프로세서에서는 7단계 연산이 순차적으로 수행되어야 하는데, 이중 3단계는 곱셈, 나눗셈과 같은 수행시간이 더 많이 걸리는 연산을 포함한다.
- 병렬 데이터 흐름 컴퓨터에서는 단지 3개의 계산과정이 수행되며 그 중 2단계에서만 곱셈과 나눗셈이 수행된다.
5) 다중처리기
․다중처리기(multiprocessor) 시스템이 갖는 장점의 하나는 일부 프로세서가 고장(failure) 날 때 나머지 프로세서들은 계속 가동할 수 있다는 점입니다.
◎ 다중처리기의 특징
․고장난 프로세서는 다른 프로세서들에게 자신이 수행하던 프로세스들을 떠 맡도록 알려야 한다.
․정상 가동중인 프로세서들은 고장난 프로세서를 알아낼 수 있어야 하고 운영체제는 ?어떤 프로세서가 고장이 났으며 더 이상 실행이 불가능한지를 알고 있어야 한다.
․오늘날의 입장에서는 2개 또는 수개의 프로세서들의 다중처리가 보다 현실적이긴 하지만 대량 병렬성(massive parallelism)을 논하는 것이 일반적이다.
․이 분야의 중요한 이론적인 문제로는 대량의 병렬 실행을 할 수 있는 기계가 주어졌을 때 어떤 특별한 알고리즘을 실행시키기 위해서 걸리는 최소 시간은 얼마인가?라는 문제가 있다.
․많은 중앙처리장치를 사용함으로써 시스템은 아래와 같은 목적을 달성 할 수 있다.
*여러 프로세서들의 처리능력을 결합시킴으로써 컴퓨터 능력의 증대가 가능해진다.
*하드웨어 비용의 하락으로 여러 개의 마이크로 프로세서를 연결시켜 다중처리기를 만드는 것도 크게 보편화되었는데, 이러한 방법으로 비싼 초고속 프로세서를 사용하지 않고도 대형컴퓨터에 접근하는 능력을 얻을 수 있다.
6) 경함험용과 계산 복잡도
․계산 복잡도(computational complexity) 분야에서의 연구자들은 병렬 알고리즘에 많은 관심을 보이고 있습니다. 만약 효율적인 병렬 알고리즘이 기존의 순차 알고리즘을 대체할 수 있다면 병렬 구조는 문제의 해결을 가속화할 수 있습니다.
(1) 결함 허용
․다중처리기 운영체제의 가장 중요한 능력 중의 하나는 개개의 프로세서의 고장을 허용하고 수행중인 연산을 계속하는 능력이다. 이를 결함허용(fault tolerance)이라고 한다.
․결함 허용 시스템은 시스템의 일부가 고장일 때도 작동을 계속할 수 있다.
․결함 허용 설계는 특히 문제 해결에 사람이 관여할 수 없는 심층 공간 (deep space) 탐색, 우주선 등의 분야에서 중요하다.
․결함 허용 한계의 구현에는 다음과 같은 방법들이 있다.
1) 시스템과 여러 프로세스들을 위한 임계 데이터의 복제를 분리된 기억장소에 위치시켜 시스템의 개개 요소에서의 고장이 데이터를 파고하지 못하도록 합니다.
2) 하드웨어의 구성을 최대화 할 수 있도록 운영체제를 만들어 고장 발생시 일부 하드웨어만으로 실행이 가능하도록 합니다.
3) 하드웨어 오류탐지와 수정으로 시스템의 작동을 중지시키는 일없이 검증을 수행할 수 있어야 합니다.
4) 유휴 프로세서가 발생 가능한 잠재력 오류를 찾는데 이용될 수 있게 합니다.
(2) 병렬처리를 통한 해결
․병렬 처리기의 가용선은 이론적 관점에서 그 문제가 해결 가능한가(solvable)에 있는 것이 아니라 해결 가능한 문제를 더 빨리 해결 할 수 있도록 하는 것이다.
이는 해결 가능한 문제의 부류를 보다 효율적으로 공략할 수 있도록 하며 병렬 슈퍼컴퓨터 분야의 과학자들이 현재 한 달 동안 수행하는 연산을 한 시간에 수행하기를 원한다고 말하는 것은 조금도 이상한 일이 아니다.
․병렬 처리기를 사용해 효율적으로 이용될 수 있는 많은 문제가 있는데 이들 문제를 다루는 데에 적절한 컴퓨터 시스템을 구축하는 것은 쉬운 일이 아니다.
예> 크기 n인 한 문제를 풀기 위한 계산 복잡도가 2n 프로세서 사이클일 때 크기가 100이라면, 이 문제의 복잡도는 천문학적인 숫자이다.
․대량 병렬성(massive parallelism)의 정도에는 상관없이 이러한 문제의 범위는 확장될 수 있다.
※ NP-complete 문제
․NP-complete(Nondeterministic Polynomial complete) 문제는 계산시간이 문제 크기의 지수적 함수인 알고리즘을 갖는데, 이런 경우에 병렬 처리기는 잘 쓰이지 않으며 'intractable'한 문제라고 한다.
․계산시간이 문제 크기에 대해 다항함수 (polynomial function)인 알고리즘은 대량병렬성의 응용에 의해 보다 직접적인 효과를 볼 수 있다. 이 경우를 'tractable' 문제라고 한다.
3. 병행성의 검출
․프로그래밍에 의해서나 또는 언어 번역기, 하드웨어, 운영체제에 의하여 병행성을 탐지하는 것을 오늘날 관심이 집중되어 있는 분야입니다.
․병행성이 어떻게 탐지되는지에 관계없이 다중처리기는 병행 수행이 가능한 부분을 동시에 실행시킴으로써 병행성을 이용할 수 있도록 합니다.
1) 명시적 병행성
(1) 병행성의 개념
․명시적 병행성(explicit parallelism)은 다음과 같이 cobegin/coend 등의 병행 구문(concurrency construct)을 사용하여 프로그래머가 직접 지정하는 것이다.

․병행성을 이용할 수 있도록 설계된 다중처리 시스템에서는 서로 다른 프로세서들이 각 문장을 동시에 실행할 수 있도록 되어 있으며 따라서 실행속도는 순차실행의 경우보다 빠르게 된다.
(2) 명시적 병행성의 특성
․병행성의 명시적 표현은 시간을 소모하는 결과를 초래하며, 또 프로그래머가 실제로 병행수행 되어서는 안될 연산을 잘못하여 병행 수행되도록 지정할 가능성도 있다. 또 병행성이라는 것은 통상 알고리즘에서 수작업으로 찾기가 힘들어서 그냥 지나치기가 쉽다.
․명시적 병행성을 가진 프로그램을 수정하는 것은 버그(bug)를 유도하기 쉽습니다. 그러므로 암시적 병행성(implicit parallelism)을 자동 검출하는 것이 가장 바람직하다.
․암시적 병행성을 이용하기 위해 검출 메커니즘은 컴파일러, 운영체제, 컴퓨터 하드웨어 등에 포함되는 것이 보통이다. 프로그램의 암시적 병행성을 찾기 위한 기법 중에는 컴파일러에 의한 두 가지 방법, 즉, 루프 분배(loop distribution)와 트리 높이 단축(tree height reduction)이 있다.
2) 루프 분배
․어떤 경우 루프 몸체(loop body)내의 무장들이 병행하여 수행될 수 있도록 구성될 수 있습니다. 배열 b와 c의 해당 원소를 각각 더하여 그 합을 배열 a에 저장하는 다음 경우를 생각해 보자.

․이 루프는 순차 프로세서가 4번의 반복을 순차적으로 수행하도록 하는데, 이러한 반복은 서로 독립적이어서 다중처리기 시스템에서 4개의 프로세서에 의해 병행적으로 수행될 수 있다. 컴파일러는 위의 for 루프를 다음과 같은 병행실행구조로 바꿀 수 있다. 이러한 기법을 루프분배라고 한다.

3) 트리 높이 단축
(1) 트리높이 단축의 개념
․컴파일러는 대수적 수식의 암시적 병행성을 찾아낼 수 있으며 다중처리기들에게 ? 목적 코드(object code)를 만들어 줄 때 동시에 실행될 수 있는 부분을 제시할 수 있다.
․컴파일러는 연산자 선행 규칙에 따라 연산을 수행해 해당 기계 코드를 만들게 된다. 하지만 꼭 연산이 이렇게 순차적으로만 되지 않아도 될 경우가 종종 있다.

(2) 트리 높이 단축의 유형
결합법칙에 의한 트리 높이 단축
*아래 그림 은 대수적 수식이 현행 일반적 컴파일러에 의해 번역되는 경우와 암시적 병행성을 발견할 수 있도록 설계된 컴파일러에 의해 번역된 경우를 보여준다.
*아래 그림은 컴파일러가 주어진 연산을 수행하기 위하여 코드를 발생시키는 과정을 보여주는 트리 구조이다.
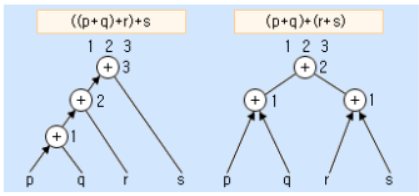
*1, 2, 3으로 붙여진 수는 각 연산들이 수행되는 순서를 나타내는데 사용됩니다. 덧셈의 결합법칙을 사용함으로써 다음 수식을 변환시켰다.
((p+q)+r)+s → (p+q)+(r+s)<병행수행에 알맞은 수식이 됨>
*이 트리 구조에서 첫 번째 수식은 3단계를 필요로 하지만 두 번째 수식은 2단계만을 필요로 하며 따라서 멀티프로세서에 의하여 더 빨리 수행될 수 있게 된다.
교환법칙에 의한 트리 높이 단축
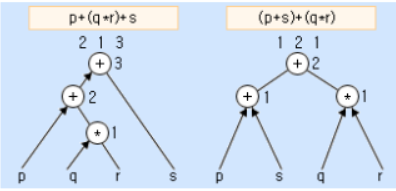
*아래 그림은 트리 구조에 3단계를 갖는 순차연산을 2단계만 갖는 병행연산으로 바꾸는 데에 덧셈의 교환법칙이 어떻게 사용되는지를 보여준다.
분배법칙에 의한 트리 높이 단축
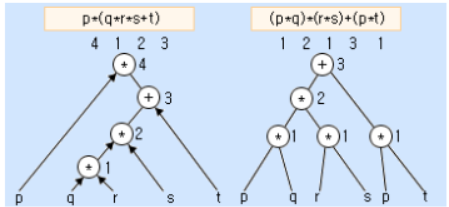
*아래 그림은 트리 구조의 깊이를 4에서 3으로 줄일 때 덧셈에 대한 곱셈의 분배법칙이 어떻게 사용되는지를 보여준다.
4) 대기 불허용 법칙
․대기 불허용 법칙(Never Wait Rule)은 주어진 어떤 프로세서를 쉬게 하는 것보다 사용될 가능성이 보이는 작업 부분을 그 프로세서에 배당하는 것이 더욱 바람직하다는 것을 뜻합니다. 결국에 가서 그 작업 결과가 추후 필요해지면 주어진 계산의 실행속도는 빨라질 수 있을 것입니다.
(1) 대기 불허용 법칙의 예
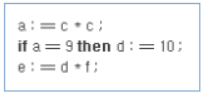
․첫 번째 문장의 결과에 따라 두 번째 문장은 d의 값을 바꿀 수도 있고 그대로 유지할 수도 있다.
․만일 d의 값이 변하지 않는다면 세 번째 문장은 첫 번째 문장과 병행하여 수행될 수 있다.
․만일 d의 값이 바뀐다면 세 번째 문장은 d의 새로운 값을 사용해야 한다.

4. 다중처리기 구조
․다중처리기 시스템의 설계에서 중요한 문제 중의 하나는 여러 개의 프로세서들과 입출력 프로세서들을 기억장치에 연결시키는 방법입니다.
․이에 대해 여러 기법이 사용되고 있는데 여기에서 다루는 다중처리기는 거의 비슷한 능력을 갖는 2개 이상의 프로세서 포함하며, 같은 기억장치를 공동으로 사용하고 또한 입출력 채널, 제어장치 및 그 외의 장치들을 공동으로 사용하며, 전체 시스템이 하나의 운영체제에 의하여 운영되는 특성을 갖는 다중처리기에 관해서만 다루기로 하겠습니다.
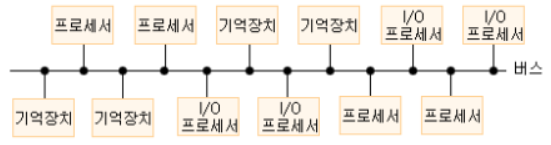
1) 공유버스
(1) 공유버스 다중 처리기 구조
․공유 버스(shared bus)는 다음 그림과 같이 프로세서, 기억장치, 입출력 장치 등 각종 장치들 간에 하나의 교신으로만 제공한다.
(2) 공유버스 가중처리기의 작동원리
․공유 버스는 본질적으로 수동적 장치(passive unit)이며, 즉 각종 장치들간의 정보전송은 그 장치들 자신의 버스 인터페이스(bus interface)에 의하여 제어된다. Ethernet LAN은 공유 버스를 이용한다.
․데이터의 전송을 원하는 프로세서 또는 입출력 프로세서는 우선, 버스와 상대방의 장치를 사용할 수 있는지를 검사해야 하며 상대방 장치에 그 자료의 처리방법을 알린 다음 실제 데이터를 전송해야 한다.
․데이터를 전송 받는 장치는 버스에 실린 메시지들이 자신에게 오는 정보임을 알 수 있어야 하며 전송장치로부터 제어 신호들을 인식하고 그에 따를 수 있어야 한다.
(3) 공유버스 가중처리기의 특성
․공유 버스 구조에서는 새로운 장치들을 손쉽게 버스에 직접 연결시킴으로써 추가시킬 수 있다.
․장기간의 교신을 하기 위해서 각 장치들은 어떤 다른 장치가 버스에 연결되어 있는지를 알아야 하며 이것은 보통 소프트웨어에 의하여 처리된다.
․하나의 교신로만을 가짐으로써 발생되는 가장 심각한 단점은 한 번에 한 가지 전송밖에 할 수 없고, 버스에 이상이 생기면 전체 시스템이 가동할 수 없게 되며(catastrophic failure), 시스템이 전체 교신량이 버스의 전송률에 제한을 받는 것이다.
․시스템이 바빠지면 버스의 사용을 위한 경쟁(contention)이 효율성의 심각한 저하를 초래한다.
․이 시스템은 경제적이고 간단하며 융통성이 있지만 공유 버스의 한계로 인하여 규모가 작은 다중처리 시스템 외에는 그 사용이 제한된다.
2) 크로스바 교환행렬 구조
(1) 크로스바 교환행렬 구조
․공유 버스 시스템에서의 버스의 수를 기억장치의 수만큼 증가시킨 것이 크로스바 교환행렬(crossbar-switch matrix)이라고 불리는 다중처리기 구조이며 이 구조에서는 각 기억장치마다 다른 회선이 존재하게 된다.
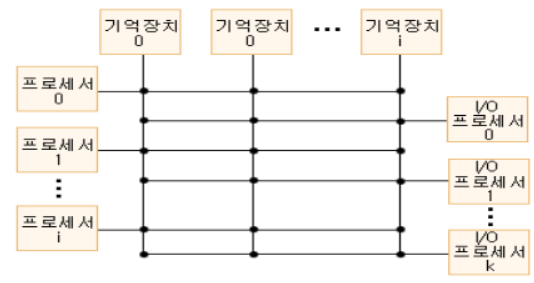
(2) 크로스바 교환행렬의 작동원리
․이 기법에서는 2개의 서로 다른 기억장치를 동시에 참조할 수 있으며 서로가 상충되는 일이 없다.
․사실상 크로스바 교환행렬 시스템은 모든 기억장치에의 동시전송이 가능하다. 따라서 크로스바 교환은 상호연결기법을 수행하는 데는 최적이다.
․크로스바 교환을 구축하기 위해 요구되는 하드웨어는 매우 복잡해질 수 있다.
3) 하이퍼큐브
(1) 하이퍼큐브 구조
․하이퍼큐브 연결 네트워크(hypercube interconnection network)는 비교적 경제적인 방법으로 많은 프로세서들을 연결하는 방법을 제공한다.
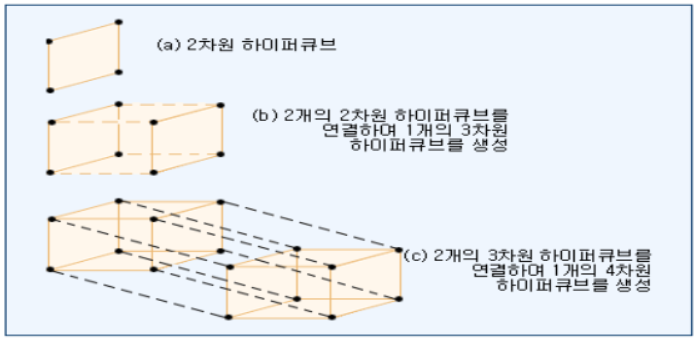
(2) 하이퍼큐브의 특성
․2차원 하이퍼큐브는 단순히 사각형이다. 3차원 하이퍼큐브는 2개의 2차원 하이퍼큐브의 대응 요소들을 각각 연결하는 것에 의하여 형성되고 4차원 하이퍼큐브는 2개의 3차원 하이퍼큐브의 대응 요소들을 연결시켜 만들어진다.
․CM(Connection Machine)은 65,536개의 프로세스를 연결하기 위하여 16 차원 하이퍼큐브를 사용한다.
4) 다단계 네트워크
(1) 다단계 네트워크
․크로스바 교환행렬구조의 주된 단점은 많은 노드가 연결될 경우 급속도로 증가한다.

(2) 다단계 네트워크
․다단계 네트워크(multistage network)는 한 노드가 어떠한 다른 노드에 라도 연결될 수 있도록 하며 많은 수의 프로세서의 연결을 쉽게 한다.
․다단계라는 용어는 메시지가 목적지에 도달하기 위해서는 여러 번의 교환과정을 통과해야만 한다는 뜻이다.
․메시지가 각 구간을 통과하는데 걸리는 연장시간은 이 시스템을 크로스바 교환구조보다 더 오래 걸리게 하나 교환기의 수는 훨씬 작으며 연결되는 프로세스의 수가 많은 때에는 더욱 자주 발생한다.
․이 구조는 전체 네트워크의 단일 경로를 제공하나 다양한 연결이 가능하다.
․몇몇 시스템에서는 메시지 전달시 충돌이 일어났을 때에 메시지를 교환기에 잠시 머무르게 하였다가 충돌 위험이 없어지면 메시지를 다시 내보내는데 이는 교환네트워크의 비용을 증가시키게 된다.
․다른 시스템에서는 각 교환기는 오직 하나의 메시지만 받아들여 처리할 수 있어서 충돌이 일어났을 때 전송된 다른 메시지들을 모두 돌려보낸다.
5. 연식결합 시스템과 경식결합 시스템
․다중처리기의 구조를 연식결합시스템과 경식결합시스템으로 구분해 볼 수 있습니다.
․두 시스템의 특성을 비교하면서 살펴보시기 바랍니다.
1) 연식결함 다중처리 시스템
․연식결합 다중처리(loosely-coupled multiprocessing) 시스템에서는 2개 이상의 독립된 컴퓨터 시스템들을 통신선을 통하여 연결시킨다.
․각 시스템은 자신의 운영체제와 기억장치를 잦고 있으며 독립적으로 운영되고 필요할 때 통신을 한다.
․이 시스템들은 통신선들을 통하여 서로 다른 시스템의 파일들을 참조할 수도 있으며 어떤 경우에는 각 시스템의 부하를 조절하기 위하여 부하가 적은 프로세서에게 작업을 보낼 수도 있다.
․프로세서들간의 통신은 메시지 전달(message passing)이나 원거리 프로시저 호출방식(remote procedure calls)을 사용한다.
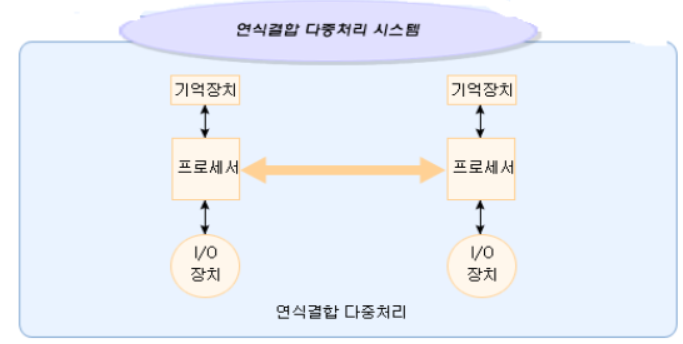
2) 경식결함 다중처리 시스템
․경식결함 다중처리(tightly-coupled multiprocessing) 시스템에서는 여러 프로세들 간에 하나의 기억장를 공유하며 하나의 운영체제가 모든 프로세서들과 시스템 하드웨어를 제어한다.
․통신 공유기억장치(shared memory)에서 일어나며 BBN Butterfly와 IMB 3090이 그 예이다.
․경식결합 시스템에서 주요 관심사는 공유기억장치에서의 경쟁(contention)입니다. 이러한 경쟁을 최소화하기 위해 많은 연구가 행해지고 있는데, 하드웨어적인 한 접근방법인 교환결합(combining switch) 방식은 기억장소에 오직 하나의 액세스만을 받아들임으로써 한 기억장소에 대한 다중 참조를 처리한다.

6. Fetch-And-Add
․단일 프로세서 시스템에서는 분명히 한 프로세서만 test-and-set 명령을 시도할 것입니다. lock 변수가 사용될 경우 실행되는 다음 프로세스가 lock을 갖습니다.
․다중 프로세서 시스템에서는 여러 프로세서들이 동시에 test-and-set 명령을 실행할 수 있으므로 문제는 더욱 복잡해져 시스템은 이 요청들을 잘 중재해야 합니다.
1) Test-And-Set 명령의 문제점
․Test-and-set 명령의 기존 방식이 어떤 문제점이 있는지 살펴봅시다.
※ 여러분은 어떤 문제점을 발견하였습니까?
․test-and-set 명령어는 또 다른 취약점을 갖고 있는데, 실행중인 연산들 각각은 분리된 기억장치 액세스를 요구하며 이들은 순차적으로 실행됩니다. 더욱 나쁜 것은 실제로 오직 하나의 프로세서만이 lock을 취할 수 있고, 다른 프로세서들은 가질 수 없다는 것입니다. 이것은 수행상태 대기(busy waiting)를 발생시킵니다.
․기억장소 경쟁은 단일 프로세서 시스템에서도 발생할 수 있는데 입출력과 처리가 병렬적으로 수행될 때 발생합니다. 그러나 이는 다중처리기, 더 나아가 대량 병렬처리기에 비교해 볼 때 아주 사소한 것이며 이러한 경쟁은 시스템 전체에 급속도로 퍼져 중대한 문제를 발생시킵니다
2) Fetch-And-Add
․다중처리 시스템이 프로세서의 풀(pool)에서 이용 가능한 프로세서를 대기 리스트의 헤드(head)에 있는 대기 프로세스에게 할당된다고 가정해 보자.
(1) Fetch-And-Add의 특징
․공동 큐(queue) 구조로 그러한 대기 큐를 유지할 때 fetchandadd 명령어는 액세스를 순차적으로 만듦으로써 큐의 사용을 더욱 효율적으로 만들어 준다.
또 다른 fetchandadd의 사용은 순환 부분(loop)의 각 반복 시행을 각기 다른 프로세서에게 할당해 병렬적으로 수행할 때 이용될 수 있다.
(2) 순차 Pascal에서의 작동
․순차 Pascal에서 다음과 같은 문이 있을 때
․Fetch-And-Add의 적용
반복구문
*배정문이 각각 서로 독립적이기 때문에 루프의 50회 반복은 병렬적으로 수행되어 질 수 있습니다. 그래서 위의 루프는 다음과 같이 각각의 반복구문을 서로 다른 프로세서들에게 할당하는 명령문으로 대치될 수 있다.
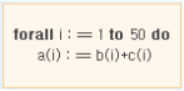
프로세스 구문
공유변수 i는 1로 초기화되어 있고 각 프로세스의 코드는 다음과 같다.

코드의 장점
*이용 가능한 프로세서의 수에 구애 받지 않는다는 것이 이 코드의 장점이다.
*이용될 수 있는 프로세서는 그들이 취급할 수 있는 만큼의 작업을 수행한다.
만약 50개 이하의 프로세서가 이용 가능하다면 이용 가능한 프로세서에서 수행되는 while/do 루프는 배열 a의 50항목의 연산이 끝날 때까지 더 많은 일을 요청할 수 있다.
*분명히 fetchandadd 결합 메커니즘의 구축은 많은 비용이 드나 병렬연산에서 성능은 우수하다.
7. 다중처리기의 운영체제 구조
․다중처리기 운영체제의 구조는 Master/Slave, 각 프로세서에 대한 서로 다른 운영체제에 의한 분리 실행, 모든 프로세서들의 대칭성 등을 통해 살펴볼 수 있습니다
1) 다중처리기 운영체제
(1) 다중처리기 운영체제의 특징
․하드웨어와 프로그램에서 병렬성을 이용하는 것이 다중처리 시스템의 핵심이며 프로세서의 수를 증가시킴으로써 기억장치와 입출력장치 간의 복잡한 연결이 필요하게 되며 이것은 하드웨어에 많은 추가비용을 필요로 한다.
․다중처리기 운영체제와 단일처리기 운영체제간의 주된 차이점은 다중처리기를 토대로 한 운영체제의 구성과 그 구조에 있다.
․다중처리기를 위한 세 가지 기본적인 운영체제 구성방법은 Master/Slave, 각 프로세서에 대한 서로 다른 운영체제에 의한 분리실행, 모든 프로세서들의 대칭성 등이다.
(2) 다중처리기 운영체제의 구분
․다중처리를 위한 세 가지 기본적인 운영체제 구성방법은 아래와 같다.
2) Master/Slave 구조
․Master/Slave 다중처리기 구조에서는 하나의 프로세서가 Master로 지정되고 나머지들은 Slave로 지정됩니다.
․Master는 범용 프로세서로서 연산뿐만 아니라 입출력도 담당합니다. 반면에 Slave는 연산만을 담당하게 됩니다.
(1) Master/Slave 구조의 형태
․Master/Slave 다중처리기 구조에서는 하나의 프로세서가 Master로 지정되고 나머지들은 Slave로 지정된다.

(2) Master/Slave 구조의 특징
․Slave들은 연산 위주의 작업을 효과적으로 처리할 수는 있지만 입출력 위주의 작업들은 Master를 통해서 해야 하므로 비효과적이다.
․신뢰성의 입장에서 볼 때 Slave가 고장 나면 어느 정도 계산능력은 감소되지만 시스템은 계속 작동할 수 있다. 그러나 Master가 고장 나는 경우에는 이 시스템은 입출력을 전혀 할 수 없게 된다.
(3) Master/Slave 구조의 가장 큰 문제점
․Master/Slave 다중처리의 가장 큰 문제점은 하드웨어의 비 대칭성(asymmetry)이다.
․Master 프로세서가 운영체제를 실행할 수 있는데 비해 Slave 프로세서는 사용자 프로그램만을 수행할 수 있다.
․Slave에서 실행되는 프로세서가 운영체제의 서비스를 받고자 할 때 Slave는 인터럽트를 발생시키고 Master가 그 인터럽트를 처리할 때까지 기다린다.
․재미있는 사실은 운영체제가 한 순간에 한 프로세서에 의해서만 사용되며, 또한 순간에 한 사람의 사용자에게만 서비스를 하므로 운영체제는 재진입이 가능(reentrant)하게 만들어질 필요가 없다는 사실이다.
3) 분리실행 구조
(1) 분리실행구조의 도입
․분리실행(separate executives) 구조에서는 각 프로세서가 나름대로 운영체제를 갖고 있으며 각 프로세서에서 발생하는 인터럽트도 해당 프로세서에서 해결이 된다.
․몇몇의 전체 시스템에서 사용되는 정보(예로 시스템내의 프로세서들의 리스트)를 저장하는 테이블에의 액세스는 상호배제기법을 사용하여 신중하게 조정되어야 한다.
․분리실행 구조에서는 한 프로세서의 고장이 치명적인 시스템의 고장을 유발하지는 않으므로 Master/Slave 구조보다 신뢰도가 높다.
(2) 분리실행구조의 특징
․각 프로세서에 의한 입출력 요구는 그 프로세서가 배당된 프로세서에 의하여 직접 수행되며, 입출력 인터럽트는 직접 입출력을 시작하게 한 프로세서에 전달된다.
․시스템상에서 입출력장치의 재구성은 서로 다른 운영체제를 갖는 다른 프로세서들 사이에서 장치는 교환하는 것이다.
․운영체제의 기능도 각 프로세서에서 비교적 독자적으로 수행되므로 운영체제의 공동 테이블에 대한 경쟁도 적고 테이블도 가능한 한 각 운영체제에 분산 수용된다.
․프로세서들은 개개의 프로세스의 실행을 위해 서로 도울 필요가 없으므로 어떤 프로세서가 일이 밀려 바쁘더라도 다른 프로세서는 유휴상태로 있을 수가 있다.
4) 대칭구조
◎ 대칭구조의 특징
대칭적 다중처리 (symmetrical multiprocessing)
*대칭적 다중처리(symmetrical multiprocessing)는 가장 복잡한 구조를 갖고 있으나 가장 강력한 시스템이다.
*모든 프로세서들이 동등한 입장에 있으며 운영체제는 어느 프로세서나 모든 입출력장치와 기억장치를 사용할 수 있도록 관리합니다.
*여러 프로세서들이 한 운영체제를 동시에 수행할 수 있게 하엿으므로 재진입 코드(reentrant code)와 상호배제(mutual exclusion)가 필요하게 됩니다. 이 기법은 대칭적이므로 다른 기법에서보다 작업 부하(work load)를 더욱 효과적으로 분산시킬 수가 있습니다.
다중처리 시스템에세의 대립문제 해결
*다중처리 시스템에서는 여러 프로세스가 동시에 한가지 일을 하려고 할 때 생기는 대립의 해결을 위해 하드웨어와 소프트웨어가 중요합니다.
*동시에 같은 기억장소를 액세스하려는 프로세서들 사이의 대립은 보통 하드웨어로 해결되며 시스템 테이블에의 액세스 대립은 소프트웨어로 해결하는 것이 보통입니다.
*대칭적 다중처리 시스템은 일반적으로 신뢰성이 가장 높습니다. 즉, 한 프로세서가 고장인 경우 운영체제는 프로세서를 제거하고 이 사실을 오퍼레이터에게 알린다. 고장 난 프로세스를 수리하고 있는 동안 시스템은 약간 능력이 떨어진 상태(즉, graceful degradation)에서 계속 작동할 수가 있습니다.
대칭적 다중처리기에서 실행되는 프로세스
*대칭적 다중 처리기에서 실행되는 프로세스는 다른 프로세서로 옮겨서 계속 수행될 수 있으며 어떤 프로세스를 실행하기 위하여 모든 협력할 수도 있습니다.
*운영체제는 여러 프로세서로 옮겨지며 실행되는데 어느 시점에서 시스템 테이블과 시스템 기능에 책임을 갖고 있는 프로세서를 실행 프로세서(executive processor)라고 합니다.
*한 순간에는 하나의 프로세서만이 관리 프로세서일 수 있으며 이렇게 함으로써 시스템의 전반적인 정보를 통일적이고 일관성 있게 운영할 수 있습니다.
다중처리 시스템에서의 대립문제
*대립문제는 동시에 여러 프로세서들이 운영체제 상태에 있을 수 있기 때문에 심각해질 수 있습니다. 따라서 지나친 폐쇄(lockout)를 방지하기 위하여 시스템 테이블은 주의 깊게 설계되어야 합니다. 이러한 대립을 최소화하는 방법 중의 한 가지는 시스템 데이터를 여러 독립적인 프로세서들에 분산 수용하고 개별적으로 폐쇄될 수 있게 하는 것입니다.
완전한 대칭적 다중처리 시스템
*완전한 대칭적 다중처리 시스템에서도 프로세서의 수만큼 전 시스템의 성능이 비교적 향상되지 못하는데 그 이유는 운영체제의 오버헤드 증가, 시스템 자원들에 대한 대립증가, 증가된 자원들의 정보교환이나 정보전송로에 있어서의 하드웨어의 지연 등입니다.
*지금까지 다중처리기의 성능에 대한 많은 연구가 있어 왔는데, 한 실험에서는 256개의 프로세서를 갖는 초기의 Butterflytltmxpa이 단일 프로세서 시스템보다 230배의 성능으로 작동한다는 것이 입증되었습니다.
정리하기
1. 다중처리는 연산의 각 부분이 동시에 실행되도록 여러 개의 프로세서들을 사용하는데 대체로 프로세서들 간에 기억장치를 공유하고 단일 운영체제의 통제를 받고 있다.
2. SISD(Single Instruction Stream Single Data Stream) 구조는 한 번에 하나의 명령어만을 수행하는 단일 프로세서 컴퓨터로서 폰 노이만 방식이다.
3. SIMD(Single Instruction Stream Multiple Data Stream) 구조는 배열처리기라고도 하는데 배열의 각 항목에 대해서 동시에 같은 연산을 수행하며 때때로 벡터 처리기와 파이프라인 처리기가 이 범주에 속한다.
4. MISD(Multiple Instruction Stream Single Data Stream) 구조는 응용되지 않고 있으며 MIMD(Multiple Instruction Stream Multiple Data Stream) 구조는 진정한 의미에 있어서 병렬 프로세서로서 멀티프로세서라고도 불린다.
5. 파이프라인 기법(pipeline)은 한 번에 여러 개의 기계어 명령어가 실행 단계에 있을 수 있도록 해서 성능을 향상시키는 방법이다.
6. 배열처리기(array processor)는 SIMD 구조로서 한 배열의 각 항목에 동시에 같은 명령어를 수행하는데 각각 별도의 프로세서들을 사용하며 대표적인 시스템으로는 MPP(Massive Parallel Processror)가 있다.
7. 데이터 흐름 컴퓨터(data flow computer)는 많은 연산을 병렬적으로 수행하는데 요구되는 데이터가 이용 가능한 명령어를 실행하기 때문에 데이터 구동방식이라고도 한다.
8. 다중 처리기 구조에는 크게 하나의 버스를 공유하여 자료를 전송하는 공유버스 방식, 버스의 수를 기억장치 수만큼 증가시킨 크로스바 교환행렬, 많은 프로세서들을 연결한 하이퍼큐브 방식, 그리고 하나의 노드가 어떠한 다른 노드에게도 연결될 수 있는 단단계 네트워크 구분된다.
9. 다중처리시스템의 결합은 크게 2개 이상의 독립된 컴퓨터 시스템을 통신선을 통해 연결하는 연식 결합 다중처리와 여러 프로세서들간에 하나의 기억장치를 공유하고 하나의 운영체제가 통제하는 경식결합 다중처리로 구분된다.
10. 다중처리기의 운영체제는 크게 하나의 프로세서가 Master로 지정되고 다른 하나가 Slave로 지정되는 Master/Slave 구조, 각 프로세서들이 별도의 운영체제를 갖고 실행되는 분리실행 구조, 여러 프로세서들이 한 운영체제를 동시에 수행할 수 있도록 상호베제가 이루어지며 가장 복잡하나 가장 강력하다고 할 수 있는 대칭 구조로 구분된다.
'정보과학 > 운영체제특론' 카테고리의 다른 글
| 임베디드 시스템과 리눅스 (0) | 2023.12.13 |
|---|---|
| 운영체제 보안 (1) | 2023.12.11 |
| 네트워크와 분산처리 (1) | 2023.12.09 |
| 파일관리 (3) | 2023.12.05 |
| 입출력관리와 디스크 스케줄링 (1) | 2023.12.03 |



