1. 스케줄링
스케줄링 정책(scheduling policy)이란 새로 실행할 프로세스를 언제, 어떻게 선택할지 결정할 때 사용하는 일련의 규칙을 말합니다.
1) 프로세스
(1) 시불할(time-sharing) 기법
․리눅스의 스케줄링 정책은 시분할(time-sharing) 기법을 토대로 한다.
․CPU 시간을 슬라이스(slice)로 쪼개고, 실행 가능한 각 프로세스마다 슬라이스를 하나씩 할당하여 프로세스 여러 개를 시간 다중화(time multiplexing) 방식으로 실행한다.
․한 프로세서는 어느 순간이든 한 프로세스만 실행할 수 있다. 현재 실행하고 있는 프로세스가 종료하지 않은 채 프로세스에 부여한 타임 슬라이스(time slice) 즉 퀀텀(quantum)이 만료되면 프로세스 전환이 일어날 수 있다.
(2) 우선순위에 따라 순위를 매기는 작업
․프로세스를 우선 순위에 따라 순위를 매기는 작업 또한 스케줄링 정책의 기반이 된다.
․리눅스에서는 프로세스의 우선 순위를 동적으로 정한다.
․스케줄러(scheduler)는 프로세스가 무엇을 하는지 계속 지켜보면서 주기적으로 프로세스의 우선 순위를 조정한다. 이런 식으로 스케줄러는 오랜 시간 CPU를 사용하지 못한 프로세스의 경우 우선 순위를 동적으로 높여주지만, 오랫동안 실행한 프로세스는 동적으로 우선순위를 낮춘다.
(3) 우선순위의 결정방법
․우선 순위는 프로세스의 종류에 따라 정해질 수도 있다. 이를 위해 프로세스는 두 가지 분류법에 의해 구분될 수 있다.
| 입출력 위주(I/O-bound) 프로세스/CPU 위주 (CPU-bound)프로세스 |
입출력 위주(I/O-bound) 프로세스 | 입출력 장치를 많이 이용하며, 많은 시간을 입출력 작업이 끝나기를 기다리는 데 사용 |
| CPU 위주(CPU-bound) 프로세스 | 숫자 계산을 하는 프로그램처럼 CPU 시간이 많이 필요한 애플리케이션 | |
| 상호 작용 프로세스/ 일괄 작업 프로세스/ 실시간 프로세스 |
상호 작용 프로세스 |
- 사용자와 끊임없이 상호 작용하는 것으로 많은 시간을 키가 눌리거나 마우스 조작이 일어나길 기다리는 데 소비 - 명령 쉘(command shell)과 문서 편집기, 그래픽 프로그램 등 |
| 일괄 작업 프로세스 |
- 사용자와 상호 작용을 요구하지 않는 것으로 백그라운드 작업으로 실행하기도 함 - 프로그래밍 언어 컴파일러와 데이터베이스 찾기 엔진, 과학 계산 프로그램 등 |
|
| 실시간 프로세스 |
- 정해진 시간 안에 빠르게 결과를 반환하는 것으로 스케줄링과 관련하여 많은 요구 사항이 있음 - 우선 순위가 더 낮은 프로세스가 이런 프로세스를 블록해서는 안되며, 짧은 반응 시간을 보장하면서 이 시간 편차를 최소화하는 등의 요구 사항임 - 비디오와 소리 관련 애플리케이션, 로봇 제어기, 물리적인 센서로부터 데이터를 수집하는 프로그램 등 |
※ 리눅스에서 시스템 콜 중의 대부분은 실시간 프로세스에도 해당하므로 사용자는 이를 이용하여 실시간 애플리케이션을 개발할 수 있다.
그러나 리눅스 커널 2.4는 비선점형(nonpreemptive)이므로 요구 사항이 많은 대부분의 실시간 애플리케이션을 지원하지 않는다. 그리고 리눅스는 상호 작용하는 애플리케이션의 반응 시간을 향상하기 위하여 암묵적으로 CPU 위주 프로세스보다는 입출력 위주 프로세스를 선호한다.
※ 리눅스 커널이 비선점형인 것에 반해 리눅스 프로세스는 선점형(preemptive)이다.
어떤 프로세스가 TASK_RUNNING 상태가 되면 커널은 이 프로세스의 동적 우선 순위가 현재 실행 중인 프로세스의 우선 순위보다 높은지 검사한다. 더 높다면 현재 실행 중인 프로세스의 실행을 중단하고 스케줄러를 호출하여 다른 프로세스를 선택해서 실행한다.(보통은 방금 실행 가능하게 된 프로세스를 선택한다.)
프로세스가 자신에 주어진 타임 퀀텀(time quantum)을 다 사용했을 때도 선점할 수 있다. 이런 경우 현재 프로세스의 need_resched 변수를 1로 설정하여 타이머 인터럽트 핸들러가 끝날 때 스케줄러를 호출한다. 여기서 선점 당한 프로세스는 보류되는 것이 아니다.
이 프로세스는 여전히 TASK_RUNNING 상태로 남아 있는 것이며 단지 CPU를 사용하지 않을 뿐이다
(4) 선점형(preemptive) 프로세스의 특징
․몇몇 실시간 운영체제는 선점형 커널의 특징이 있다.
․선점형(preemptive)이란 커널 모드에서 실행 중인 프로세스라도 사용자 모드에서와 마찬가지로 아무 명령에서나 CPU를 가로챌 수 있음을 의미한다.
․리눅스 프로세스는 선점형(preemptive)이다.
어떤 프로세스가 TASK_RUNNING 상태가 되면 커널은 이 프로세스의 동적 우선 순위가 현재 실행 중인 프로세스의 우선 순위보다 높은지 검사한다. 더 높다면 현재 실행 중인 프로세스의 실행을 중단하고 스케줄러를 호출하여 다른 프로세스를 선택해서 실행한다.
․반면에 리눅스 커널은 선점형이 아니므로 사용자 모드에 있을 때만 프로세스를 선점할 수 있다. 비선점형 커널은 커널 자료 구조와 관련한 대부분의 동기화(synchronization) 문제를 쉽게 해결할 수 있어 커널 설계가 훨씬 간단하다.
2) 스케줄링 알고리즘
(1) 에포크(epoch)
․리눅스의 스케줄링 알고리즘은 CPU 시간을 에포크(epoch) 단위로 나누어 동작한다.
․한 에포크 동안 모든 프로세스는 정해진 타임 퀀텀을 소유하며, 이 기간을 그 에포크가 시작할 때 계산한다.
․일반적으로 서로 다른 프로세스는 타임 퀀텀 기간이 서로 다르다.
․타임 퀀텀 값은 그 에포크 동안 프로세스에 할당하는 최대 CPU 시간이다.
․프로세스가 타임 퀀텀을 모두 소비하면 해당 프로세스를 선점하여 다른 실행할 수 있는 프로세스로 교체한다. 물론 프로세스가 퀀텀을 모두 소비하지 않는 한 스케줄러는 한 에포크 안에 그 프로세스를 여러 번 선택하여 실행할 수도 있다.
․한 에포크는 실행 가능한 모든 프로세스가 자신의 퀀텀을 완전히 소비할 때 끝난다. 이 경우 스케줄러 알고리즘은 모든 프로세스의 타임 퀀텀을 다시 계산하고, 새로운 에포크를 시작한다.
(2) 기본 타임 퀀텀(base time quantum)
․각 프로세스는 기본 타임 퀀텀(base time quantum)이 있다.
․퀀텀은 프로세스가 이전 에포크에서 자신의 퀀텀을 모두 소비하면 스케줄러가 프로세스에 할당하는 타임 퀀텀 값이다.
․사용자는 nice()와 setpriority() 시스템 콜을 이용하여 자신이 실행하는 프로세스의 기본 타임 퀀텀을 바꿀 수 있다.
․새로 생성되는 프로세스는 항상 부모의 기본 타임 퀀텀을 상속받는다.
(3) 우선순위
․리눅스 스케줄러는 실행할 프로세스를 선택할 때 각 프로세스의 우선 순위를 고려해야 하며, 이런 우선 순위에는 정적 우선 순위(static priority)와 동적 우선 순위(dynamic priority)가 있다.
․정적 우선 순위는 사용자가 실시간 프로세스에 부여한 것으로 값의 범위는 1부터 99까지이다.
․스케줄러는 이 값을 절대로 바꾸지 않는다. 동적 우선 순위는 일반 프로세스에 해당하는 것이다.
․이것은 기본적으로 기본 우선 순위라고도 불리는 기본 타임 퀀텀과 현재 에포크에서 퀀텀이 만료되기까지 프로세스에 남은 CPU 시간의 틱 수를 합한 값이다.
․실시간 프로세스의 우선 순위는 일반 프로세스의 동적 우선 순위보다 항상 높다.
․스케줄러는 TASK_RUNNING 상태에 있는 실시간 프로세스가 없을 때에만 일반 프로세스를 실행한다.
․시스템에는 언제나 실행 가능한 프로세스가 적어도 하나가 있다. 이는 바로 PID 0인 스와퍼 커널 스레드로 실행할 다른 프로세스가 없을 때만 실행한다.
(3) 우선순위
․need_resched:need_resched는 ret_from_sys_call()이 schedule() 함수를 호출해야 하는지 여부를 나타내는 플래그이다.
․policy:policy 변수는 스케줄링 방식을 나타내는 것으로, SCHED_FIFO, SCHED_RR, SCHED_OTHER의 세 가지 값 중 하나를 가질 수 있다.
| SCHED_FIFO | - 먼저 들어온 것이 먼저 나가는 방식의 실시간 프로세스 - 선점 불가능(nonpreemtive : 이 프로세스가 한 번 스케줄링 되면 끝날 때까지 또는 자발적으로 중지할 때까지 CPU를 빼앗을 수 없음) 유형임을 의미 |
| SCHED_RR | - 라운드 로빈(Round Robin) 방식의 실시간 프로세스 - 선점 가능(preemptive : 이 프로세스가 실행 중일 때 이 프로세스보다 우선 순위가 높은 새로운 프로세스가 나타나면, 이 프로세스를 중지시키고 다른 프로세스를 실행시킬 수 있음) 유형임을 의미 |
| SCHED_OTHER | - 비실시간 프로세스 - 이 프로세스는 일반 시분할 방식으로 스케줄링 |
․rt_priority:rt_priority는 실시간 프로세스의 정적 우선 순위를 나타내는 것으로, 유효한 우선 순위의 범위는 1부터 99까지다. 일반 프로세스의 정적 우선 순위는 0으로 설정해야 한다.
․counter:counter는 프로세스의 퀀텀이 만료되기까지 프로세스에 남은 CPU 시간의 틱 수로, 새로운 에포크를 시작할 때 이 변수를 프로세스의 타임 퀀텀 기간으로 설정한다. update_process_times() 함수는 틱이 발생할 때마다 현재 프로세스의 counter 변수의 값을 1씩 줄인다.
․nice:nice는 새 에포크를 시작할 때 프로세스가 가지는 타임 퀀텀의 길이를 지정하는 것으로, -20에서 19 사이의 값을 가진다. 음수 값은 높은 우선 순위 프로세스에, 양수 값은 낮은 우선 순위 프로세스에 해당한다. 기본 값은 보통 프로세스에 해당하는 0이다.
․cpus_allowed:cpus_allowed는 프로세스를 실행할 수 있도록 허가한 CPU의 비트 마스크를 지정한다. 80x86 구조에서 최대 프로세서 개수는 32이므로 전체 마스크를 정수 필드 하나에 집어넣을 수 있다.
․cpu_runnable:cpu_runnable는 프로세스를 실행 중인 CPU가 있을 경우의 비트 마스크다. 프로세스를 실행 중인 CPU가 없다면 이 변수의 모든 비트를 1로 설정한다. 있다면 프로세스를 실행 중인 CPU에 해당하는 비트를 1로 설정하고 나머지 비트는 모두 0으로 설정한다.
․processor:processor는 프로세스를 실행 중인 CPU가 있을 경우의 CPU 인덱스다. 없다면 프로세스를 실행한 마지막 CPU의 인덱스다.
(4) 스케줄러(scheduler)를 구현한 함수
․스케줄러(scheduler)를 구현한 함수는 kernel/sched.c 파일에 있는 schedule()이다.
․이 함수는 실행 큐 리스트에서 실행할 프로세스를 찾아 CPU를 할당한다.
․스케줄러는 2가지 사건에 의해 호출된다.
| 1단계 | *현재 실행 중인 프로세스의 task_struct에 need_resched라는 멤버가 1로 설정되어 있으면 호출된다. need_resched 멤버는 현재 실행중인 프로세스보다 더 높은 우선 순위를 갖는 프로세스가 생성되거나 타임 퀀텀이 만료되는 것 등과 같은 사건이 발생하면 1로 설정된다. 그리고 프로세스가 커널 수준에서 사용자 수준으로 전이할 때 이 멤버가 설정되어 있는지 여부를 조사하고, 설정되어 있을 경우에도 스케줄러를 호출한다. |
| 2단계 | *현재 실행중인 프로세스가 대기 상태로 전이할 때 스케줄러가 호출된다. 스케줄러가 호출되면 우선 실시간 클래스에 속한 프로세스 중에서 가장 순위가 높은 프로세스를 실행시킨다. 만일 실시간 클래스에 속한 프로세스가 없으면 비실시간 프로세스 중에서 우선 순위가 가장 높은 프로세스를 스케줄링 한다. 수행될 프로세스가 선택되면 문맥 교환(context switch)을 통해 현재 실행 중이던 프로세스(current)를 중지시키고, 사건에 따라 준비 상태 또는 대기 상태로 전이시킨다. 그리고 선택된 프로세스(next)를 실행 상태로 전이시킨다. 실시간 클래스에 속하지 않은 프로세스들에게는 시분할 방식을 적용한다. |
※ 커널의 선점성과 비선점성
오랫동안 유지해온 리눅스 커널의 주요 특징 하나는 커널의 비선점성(nonpreemption)이다.
즉 커널 모드에 진입한 프로세스는 직접 또는 간접적으로 스케줄러를 호출하여 CPU를 반납하는 경우를 제외하고 임의로 선점할 수 없다. 인터럽트 처리 등을 통해 새로운 프로세스가 실행 가능해져 리스케줄링(rescheduling)이 일어나야 하는 경우 스케줄링은 항상 커널 모드에서 사용자 모드로 되돌아가는 시점에서 일어난다. 따라서 항상 우선 순위가 높은 프로세스를 실행해야 하는 실시간 운영체제의 요건에는 맞지 않는다.
선점 가능한 커널은 이런 제한을 극복하고 인터럽트를 처리한 직후 우선 순위가 높은 프로세스가 있는 경우 커널 모드를 빠져나가지 않고 새로운 프로세스로 스케줄링을 할 수 있는 경우 커널 모드를 빠져나가지 않고 바로 새로운 프로세스로 스케줄링을 할 수 있게 한다.
즉 커널 모드에서도 특별히 정해진 구역을 제외한 어디서나 스케줄링이 일어날 수 있게 한다. 이는 실시간 운영체제의 하드 실시간(hard real-time) 기능으로, 입출력 위주 프로그램이나 실시간 프로그램의 반응성을 크게 향상시킨다.
선점 가능한 커널은 원래 임베디드 리눅스 업체인 몬타비스타(Montavista)에서 2.4 커널용으로 개발하여 발표한 것으로, 러버트 러브(Robert Love)가 이를 수정하여 2.5 커널에 반영하였다. 선점 가능한 커널에서는 몇 가지 경우를 제외하고 언제든지 커널을 선점할 수 있다. 선점할 수 없는 경우는 인터럽트 처리중일 때, 미룰 수 있는 함수를 실행 중일 때, (둘 다 현재 프로세스가 의미 없는 인터럽트 컨텍스트에서 동작 중일 때다.),스핀 락이나 다른 읽기/쓰기 락을 점유하고 있을 때, 커널이 스케줄러를 실행하고 있을 때 등이다.
3) 스케줄링 관련 시스템 콜
| 시스템 콜 | 설 명 |
| nice() | 일반 프로세스의 우선 순위를 변경한다. |
| getpriority() | 일반 프로세스 그룹의 최대 우선 순위 값을 알아낸다. |
| setpriority() | 일반 프로세스 그룹의 우선 순위를 설정한다. |
| sched_getscheduler() | 프로세스 스케줄링 정책을 알아낸다. |
| sched_setscheduler() | 프로세스 스케줄링 정책과 우선 순위를 설정한다. |
| sched_getparam() | 프로세스 스케줄링 우선 순위를 알아낸다. |
| sched_setparam() | 프로세스 우선 순위를 설정한다 |
| sched_yield() | 블록하지 않으면서 자진하여 프로세서를 반납한다. |
| sched_get_priority_min() | 지정한 스케줄링 정책에 대한 최소 우선 순위 값을 알아낸다. |
| sched_get_priority_max() | 지정한 스케줄링 정책에 대해 최대 우선 순위 값을 알아낸다. |
| sched_rr_get_interval() | 라운드 로빈(Round Robin) 정책의 타임 퀀텀 값을 알아낸다. |
◎ 시케줄링 관련 시스템 콜
․nice()
- nice() 시스템 콜은 프로세스가 자신의 기본 우선 순위를 바꿀 수 있게 한다.
- increment 매개변수로 전달한 정수 값을 프로세스 서술자의 nice 변수를 바꾸는 데 사용한다.
- sys_nice() 서비스 루틴은 nice() 시스템 콜을 처리한다.
- increment 매개 변수에 어떤 값이든 지정할 수 있지만 절대값이 40을 넘어가면 이를 40으로 맞춘다.
- 전통적으로 음수는 우선 순위를 높이는 요청으로 관리자 권한이 필요하다. 반면 양수는 우선 순위를 낮추는 요청이다. 음수인 경우 이 함수는 capable() 함수를 호출하여 프로세스에 CAP_SYS_NICE 특질(capability)이 있는지 확인한다.
- 사용자가 우선 순위를 바꾸는 데 필요한 특질이 있음을 확인하면, sys_nice()는 current의 nice 변수에 increment 값을 더한다. 필요하다면 이 변수의 값을 조정하여 그 값이
- 20보다 작거나 19보다 클 수 없게 만든다.
․getpriority()
- nice() 시스템 콜은 이를 호출한 프로세스에만 영향을 미친다.
getpriority()와 setpriority() 시스템 콜은 지정한 프로세스 그룹에 있는 모든 프로세스의 기본 우선 순위에 영향을 미친다.
- getpriority()는 20에서 지정한 그룹 내에 있는 모든 프로세스의 기본 우선 순위 중 가장 낮은 nice 변수의 값을 뺀 값을 반환한다.
․setpriority()
- nice() 시스템 콜은 이를 호출한 프로세스에만 영향을 미친다.
getpriority()와 setpriority() 시스템 콜은 지정한 프로세스 그룹에 있는 모든 프로세스의 기본 우선 순위에 영향을 미친다.
- setpriority()는 지정한 그룹 내에 있는 모든 프로세스의 기본 우선 순위를 지정한 값으로 설정한다. 커널은 이 시스템 콜들을 각각 sys_getpriority()와 sys_setpriority() 서비스 루틴으로 구현한다.
- 이 두 함수는 모두 매개 변수로 which, who, niceval을 사용한다.
- which는 프로세스 그룹을 식별하는 것으로 PRIO_PROCESS, PRIO_PGRP, PRIO_USER의 값 중 하나를 가진다.
*PRIO_PROCESS:프로세스 ID와 일치하는 프로세스를 선택하고, PRIO_PGRP는 그룹 ID와 일치하는 프로세스를 선택
*PRIO_USER:사용자 ID와 일치하는 프로세스를 선택
- who는 프로세스를 선택하는 데 사용하는 pid나 pgrp, uid 멤버의 값이다. who가 0이면 이 값을 current 프로세스의 해당 멤버 값으로 설정한다.
- niceval은 sys_setpriority()에만 필요한 새로운 기본 우선 순위 값이다. 가장 높은 우선 순위 값-20에서 가장 낮은 우선 순위 값인 19 사이의 값이다.
․sched_getscheduler()
- sched_getscheduler() 시스템 콜은 pid 매개 변수로 지정한 프로세스에 현재 적용하는 스케줄링 정책을 질의한다.
- pid가 0이면 이 시스템 콜을 호출한 프로세스의 스케줄링 정책을 반환한다.
- 이 시스템 콜이 성공하면 지정한 프로세스의 스케줄링 정책으로 SCHED_FIFO나 SCHED_RR, SCHED_OTHER를 반환한다.
- 이 시스템 콜을 처리하는 sys_sched_getscheduler() 서비스 루틴은 find_process_by_pid() 함수를 호출하여 지정한 pid에 해당하는 프로세스 디스크립터를 찾아 policy 멤버 값을 반환한다.
․sched_setscheduler()
- sched_setscheduler() 시스템 콜은 pid 매개 변수로 지정한 프로세스의 스케줄링 정책과 이와 관련한 인자를 설정한다.
- pid가 0이면 이를 호출한 프로세스의 스케줄러 인자를 설정한다.
- 해당 서비스 루틴인 sys_sched_setscheduler() 함수는 policy 매개 변수로 지정한 스케줄링 정책과 param->sched_priority 매개 변수로 지정한 새로운 정적 우선 순위가 올바른 값인지 검사한다.
․sched_getparam()
- sched_getparam() 시스템 콜은 pid에 해당하는 프로세스의 스케줄링 인자를 얻어온다.
- pid가 0이면 current 프로세스의 스케줄링 인자를 얻어온다.
- 이를 처리하는 sys_sched_getparam() 서비스 루틴은 pid와 연관된 프로세스 서술자의 포인터를 찾아서 프로세스 디스크립터 내의 rt_priority 멤버를 sched_param 타입 지역 변수에 저장한다.
- 그런 후에 copy_to_user()를 호출하여 param 매개 변수로 지정한 프로세스 주소 공간에 있는 주소로 이를 복사한다.
․sched_setparam()
- sched_setparam() 시스템 콜은 sched_setscheduler()와 비슷하지만, 이 시스템 콜은 policy 변수 값을 설정하지 않는다는 차이가 있다.
- 이를 처리하는 sys_sched_setparam() 서비스 루틴은 sys_sched_setscheduler()와 거의 똑같지만, 이를 적용하는 프로세스의 스케줄링 정책은 절대 바뀌지 않는다.
․ sched_yield()
- sched_yield() 시스템 콜을 사용하면 프로세스를 보류 상태로 만들지 않고 자발적으로 CPU를 반납할 수 있다.
- 프로세스는 여전히 TSAK_RUNNING 상태로 남지만 스케줄러는 이 프로세스를 실행 큐 리스트의 맨 끝에 넣어 동적 우선 순위가 같은 다른 프로세스에 실행할 기회를 준다.
- 이 시스템 콜은 SCHED_FIFO 프로세스가 주로 사용한다.
- 이 시스템 콜을 처리하는 sys_sched_yield() 서비스 루틴은 먼저 시스템에 이 시스템 콜을 실행하는 프로세스와 스와퍼(swapper) 커널 스레드를 제외한 다른 실행 가능한 프로세스가 있는지 검사한다.
․ sched_get_priority_min()
- sched_get_priority_min()과 sched_get_priority_max() 시스템 콜은 각각 policy 매개 변수로 지정한 스케줄링 정책에서 사용할 수 있는 실시간 정적 우선 순위의 최소, 최대 값을 반환한다.
- sys_sched_get_priority_min() 서비스 루틴은 current가 실시간 프로세스면 1, 그렇지 않으면 0을 반환한다.
․sched_get_priority_max()
- sched_get_priority_min()과 sched_get_priority_max() 시스템 콜은 각각 policy 매개 변수로 지정한 스케줄링 정책에서 사용할 수 있는 실시간 정적 우선 순위의 최소, 최대 값을 반환한다.
- sys_sched_get_priority_max() 서비스 루틴은 current가 실시간 프로세스면 가장 높은 우선 순위인 99를, 그렇지 않으면 0을 반환한다.
․ sched_rr_get_interval()
- sched_rr_get_interval() 시스템 콜은 pid 매개 변수로 지정한 실시간 프로세스의 라운드 로빈(round robin) 타임 퀀텀을 사용자 모드 주소 공간에 있는 구조체에 기록한다.
- pid가 0이면 이 시스템 콜은 현재 프로세스의 타임 퀀텀을 기록한다. 해당 서비스 루인 sys_sched_rr_get_interval()은 마찬가지로 find_process_by_pid()를 호출하여 pid에 해당하는 프로세스 디스크립터를 가져온다.
- 그런 후에 선택한 프로세스 디스크립터의 nice 멤버에 들어 있는 틱의 수를 초와 나노초(nanosecond)로 변환하여 이 값을 사용자 모드에 있는 구조체로 복사한다.
2. 프로세스간 통신
․시스템에 작동하기 위해서는 프로세스간의 통신이 필요합니다.
1) 시그널 처리
(1) 시그널의 구분
․정규 시그널(regular signal) :큐에 들어가지 않는다. 정규 시그널을 연이어 여러 번 보내더라도 이를 수신하는 프로세스는 하나만 받는다.
․실시간 시그널 (real-time signal) 은 항상 큐에 쌓이므로 시그널을 여러 번 보내더라도 모두 받을 수 있다는 점에서 정규 시그널과 달라진다.
(2) 리눅스에서의 시스템 콜
․프로그래머는 여러 시스템 콜을 이용하여 시그널을 전송하고, 프로세스가 수신한 시그널에 어떻게 반응할지 결정할 수 있다.
․다음은 이러한 시스템 콜을 간략하게 정리한 것이다.
| 시스템 콜 | 설 명 |
| kill() | 일반 프로세스의 시그널을 전송한다. |
| sigaction() | 시그널과 관련한 동작을 변경한다. |
| signal() | sigaction()과 비슷하다. |
| sigpending() | 대기 중인 시그널이 있는지 검사한다 |
| sigprocmask() | 블록할 시그널 목록을 수정한다. |
| sigsuspend() | 시그널을 기다린다. |
| rt_sigaction() | 실시간 시그널과 관련한 동작을 변경한다. |
| rt_sigpending() | 대기 중인 실시간 시그널이 있는지 검사한다 |
| rt_sigprocmask() | 블록할 실시간 시그널 목록을 수정한다. |
| rt_sigqueueinfo() | 프로세스에 실시간 시그널을 전송한다 |
| rt_sigsuspend() | 실시간 시그널을 기다린다. |
| rt_sigtimedwait() | rt_sigsuspend()와 비슷하다. |
(3) 시그널 처리의 특징
․대개 어떤 상태인지 예측할 수 없는 프로세스에 언제든지 시그널을 보낼 수 있다.
․실행 중이지 않은 프로세스에 시그널을 보내면 커널은 해당 프로세스가 다시 실행을 재개할 때까지 시그널을 저장해야 한다.
․시그널을 블록(block)하면 해당 시그널의 블록을 해제할 때까지 시그널 전송을 미뤄야 하는데, 이는 시그널을 전달할 수 있는 상태가 되기 전에 발생한 시그널의 처리 문제를 더욱 복잡하게 만든다.
․따라서 커널은 시그널 전송을 다음의 두 단계로 구별한다.
*1단계:시그널 발생->커널은 새로운 시그널을 보낸 것을 나타내려고 시그널을 받는 프로세스의 디스크립터를 갱신한다.
*2단계:커널은 시그널을 수신한 프로세스의 실행 상태를 바꾸거나 특정 시그널 핸들러를 실행하거나, 이 두 가지를 모두 실행해서 수신한 프로세스가 시그널에 반응하게 만든다.
*참고사항:발생한 각 시그널은 많아야 한 번만 배달할 수 있다. 시그널은 소모성 자원이다.
즉 시그널을 배달하고 나면 해당 시그널의 기존 존재를 나타내는 모든 프로세스 디스크립터 정보를 지운다.
발생했지만 아직 배달하지 않은 시그널을 대기 중인 시그널(pending signal)이라 한다. 어느 순간이든 한 프로세스에서 같은 종류의 시그널은 단 하나만 대기할 수 있다.
같은 프로세스에 같은 종류의 시그널이 추가로 대기하더라도 큐에 쌓지 않고 무시한다. 실시간 시그널은 이와 달리 같은 종류의 시그널이 동시에 여러 개 대기할 수 있다.
(4) 프로세스가 시그널에 반응하는 양식
․다음은 프로세스가 시그널에 반응하는 양식에 대한 설명이다.
*시그널 무시:명시적으로 시그널을 무시한다.
*시그널과 관련한 기본 동작 수행:해당 시그널과 관련한 기본 동작을 수행한다. 커널에서 미리 정의하고 있는 기본 동작은 시그널 종류에 따라 다르며, 다음 중 하나다.
- 종료(terminate) : 프로세스를 종료한다.
- 덤프(dump) : 프로세스를 종료하고 가능하면 실행 컨텍스트(context)를 포함하는 코어(core) 파일을 만든다. 이 파일은 디버깅 용도로 사용할 수 있다.
- 무시(ignore) : 시그널을 무시한다.
- 중지(stop) : 프로세스를 멈춘다. 즉 프로세스를 TASK_STOPPED 상태로 만든다.
- 계속(continue) : 프로세스가 멈춰 있다면(TASK_STOPPED) 프로세스를 TASK_RUNNING 상태로 만든다.
*핸들러 함수 호출 : 해당 시그널 핸들러 함수를 호출하여 시그널을 잡는다.
※ 시그널을 블록하는 것과 무시하는 것이 차이
시그널을 블록하는 것과 무시하는 것은 다르다.
시그널을 블록하는 동안에는 시그널을 배달하지 않고 블록을 해제한 후에만 배달한다. 무시한 시그널은 항상 배달하지만 더는 동작을 하지 않는다.
SIGKILL과 SIGSTOP 시그널은 무시하거나 잡거나 블록할 수 없으며, 항상 기본 동작을 실행해야 한다. 따라서 사용자는 적절한 특권만 있다면 프로그램이 어떻게 방어하든지 상관없이 SIGKILL과 SIGSTOP 시그널을 사용하여 프로세스 0과 프로세스 1을 제외한 모든 프로세스를 종료하거나 멈출 수 있다.
2) 파이프(pipe)
(1) 리다이렉션(redirection)을 통한 파이프 생성
․일반적으로 사용하는 리눅스 쉘들은 모두 리다이렉션(redirection)을 지원하는데, 이를 이용하여 파이프를 생성할 수 있다.
․임시파일 대신 파이프를 사용할 때 얻어지는 장점
① 쉘 문장이 더 짧고 간단하다.
② 임시 파일을 생성하고 삭제할 필요가 없다.
(2) pipe() 시스템 콜의 호출
․pipe() 시스템 콜을 호출한 프로세스는 새로운 파이프에 읽고 쓰기 위해 접근할 수 있는 유일한 프로세스다.
․파이프에 읽기와 쓰기 프로세스가 있음을 나타내기 위해 pipe_inode_info 데이터 구조체의 readers와 writers 멤버를 1로 초기화한다.
․일반적으로 어떤 프로세스가 파이프의 파일 객체를 오픈하고 있을 때만 파일 객체에 대응하는 멤버가 1로 설정되고 대응하는 파일 객체를 해제하면 0으로 설정된다.
․새로운 프로세스를 포크(fork)해서 자식 프로세스를 생성하는 것은 readers와 writers 멤버 값을 증가시키지 않으므로 1보다 커지지 않지만, 부모 프로세스에서 계속 사용하는 모든 파일 객체의 사용 카운터는 증가한다. 그러므로 부모 프로세스가 죽더라도 객체는 해제되지 않으며, 자식 프로세스에서 이용하기 위해 파이프는 열린 상태가 지속된다.
․프로세스가 파이프를 가리키는 파일 디스크립터에 대해 clone() 시스템 콜을 호출할 때마다 커널은 대응하는 파일 객체에 fput() 함수를 실행한다.
․이 함수는 실행할 때마다 사용 카운터를 감소시키며, 카운터가 0이 되면 파일 연산의 release 메소드를 호출한다.
․release 메소드는 파일이 읽기 채널과 쓰기 채널 중 어느 쪽에 관련되어 있는지에 따라 pipe_read_release()나 pipe_write_release() 중 하나로 구현된다.
․이 두 함수는 pipe_release()를 호출하는데, 이 함수는 pipe_inode_info 구조체의 readers 또는 writers 멤버를 0으로 설정한다. 또한 두 멤버가 모두 0이면 파이프 버퍼를 포함하는 페이지 프레임을 해제한다. 그렇지 않으면 파이프 상태의 변화를 알 수 있도록 파이프의 대기큐에 잠들어 있는 프로세스를 활성화한다.
(3) 파이프의 작동
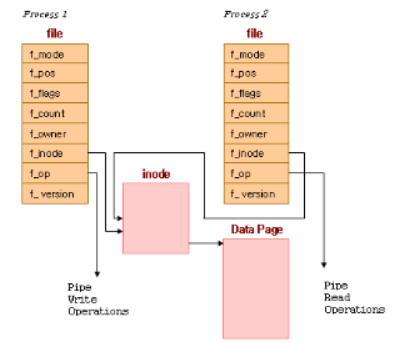
․위의 그림은 각 파일 자료구조가 각기 다른 파일 연산 루틴 벡터를 가리키는 포인터를 가지고 있는 모습을 보여준다.
․여기서 한 파일 자료구조는 파이프에 쓰는 함수에 대한 포인터를 가지고, 다른 자료구조는 파이프에서 읽어들이는 함수에 대한 포인터를 가진다.
․이것은 보통의 파일에 읽고 쓰는 시스템 콜이 아래 계층의 차이에 관계없이 동작하도록 한다.
․쓰는 프로세스가 파이프에 쓴 데이터는 공유 데이터 페이지에 복사되고, 읽는 프로세스가 그 파이프로부터 읽어 들일 때는 공유 데이터 페이지로부터 데이터가 복사되게 된다. 리눅스는 파이프에 대한 접근을 동기화해야 한다.
․파이프의 읽는 프로세스와 쓰는 프로세스가 반드시 차례를 지킬 수 있도록 해야 하고, 그렇게 하기 위해 락(lock)과 대기큐(waiting queue), 시그널 등을 사용한다.
(4) 표준 라이브러리 함수의 활용
․프로세스가 파이프에 쓰기를 할 때는 쓰기를 하는 표준 라이브러리 함수를 사용한다.
․이들 함수들에는 파일 디스크립터(file descriptor)를 넘기는데, 이는 프로세스가 가진 여러 개의 파일 자료구조(이들 각각은 프로세스가 열어 놓은 파일을 나타내며, 이 경우에는 열어 놓은 파이프를 나타낸다.)에 대한 인덱스이다.
․리눅스 시스템 콜은 이 파이프를 나타내는 파일 자료구조에서 가리키고 있는 쓰기 루틴을 사용한다. 이 쓰기 루틴은 쓰기 요청을 처리하기 위해 파이프를 나타내는 VFS inode에 있는 정보들을 이용한다.
․파이프에 요청한 바이트들을 모두 쓸 공간이 있는 상태에서 파이프를 읽는 프로세스가 락을 걸어두지 않았다면, 리눅스는 먼저 파이프에 락을 걸고 쓸 데이터 바이트들을 프로세스의 주소공간에서 공유 데이터 페이지로 복사한다.
- 만약 읽는 프로세스가 파이프에 락을 걸어두었거나 데이터를 담을 충분한 공간이 없었다면 현재 프로세스는 해당 파이프 inode에 있는 대기큐에 들어가 잠들고, 실행할 수 있는 다른 프로세스를 선택하기 위해 스케줄러를 호출한다.
- 잠든 프로세스는 인터럽트 허용 상태이므로 시그널을 받을 수 있으며, 읽는 프로세스에 의해 쓸 데이터를 담기에 충분한 공간이 생기거나 파이프의 락이 풀리면 깨어나게 된다. 데이터를 쓰고 나면 파이프의 VFS inode의 락을 풀고 inode의 대기큐에서 기다리며 잠들어 있는 읽는 프로세스를 깨우게 된다.
(5) 파이프에서 데이터 읽기
․파이프에서 데이터를 읽는 과정은 파이프에 쓰는 과정과 매우 비슷하다.
․프로세스들은 블록킹을 하지 않고 읽을 수 있는데(이는 파일이나 파이프를 열 때 어떤 모드를 사용하였느냐에 따라 다르다.), 이 경우 읽을 데이터가 없거나 파이프에 락이 걸려있으면 에러가 돌아온다. 이는 프로세스가 잠들지 않고 실행을 계속할 수 있다는 것이다.
․블록킹 모드라면 파이프 inode의 대기큐에서 쓰기 프로세스가 끝나기를 기다려야 한다. 양쪽 프로세스가 파이프를 통한 작업을 종료하면, 파이프 inode는 공유 데이터 페이지와 함께 폐기된다.
3) FIFO
(1) FIFO의 개념
․FIFO는 파이프와 거의 비슷하다. FIFO는 파일시스템에서 디스크 블록을 소유하지 않으며, 열린 FIFO는 프로세스 두 개 이상이 자료를 교환하기 위해 커널 버퍼를 임시 저장 공간으로 사용한다.
․FIFO 파일명은 시스템의 디렉토리 트리에 포함되어 있기 때문에 해당하는 접근 권한을 가지고 있다면 어떠한 프로세스도 FIFO에 접근할 수 있다.
(2) 리눅스에서의 FIFO
․리눅스 2.4 커널에서 FIFO와 파이프는 거의 동일하며 동일한 pipe_inode_info 구조체를 이용하기 때문에 FIFO의 읽기/쓰기 연산 또한 파이프와 동일한 pipe_read()와 pipe_write() 함수로 구현되었다. 그러나 다음과 같은 차이점이 있다.
① FIFO 아이노드는 pipefs라는 특별한 파일시스템이 아닌 시스템 디렉토리 트리에 있다.
② FIFO는 양방향 통신 채널이다. 즉 한 FIFO를 읽기/쓰기 모드로 열 수 있다.
(3) mknod() 시스템 콜을 통한 FIFO의 생성
․프로세스는 mknod() 시스템 콜을 호출하여 FIFO를 생성한다.
․FIFO를 생성할 때 새로운 FIFO 경로 이름과 새로운 파일 허가 비트 마스크와 S_IFIFO(0x1000) 값을 논리 연산자 OR로 연결한 값을 매개 변수로 전달한다.
․FIFO가 생성되면 open(), read(), write(), close() 시스템 콜을 이용하여 FIFO에 접근할 수 있다.
(4) open() 시스템 콜의 동작 방식
․open() 시스템 콜의 동작 방식은 기본적으로 요청한 유형, 입출력 연산의 종류(blocking 또는 non-blocking), FIFO에 접근하는 다른 프로세스의 존재 여부에 따라 다르다.
․프로세스는 읽기나 쓰기용으로 또는 읽기/쓰기 겸용으로 FIFO를 열 수 있다. 파일 연산은 이러한 세 가지 경우에 따라 다른 메소드로 설정된다.
(5) FIFO의 세 가지 연산 테이블
․FIFO의 세 가지 연산 테이블은 read와 write 메소드의 구현 방법에서 차이가 난다.
․접근 유형이 읽기 연산을 허용한 경우 읽기 메소드는 pipe_read() 함수로 구현하고, 그렇지 않으면 에러 코드를 반환하는 bad_pipe_r()로 구현한다.
이와 비슷하게 접근 유형이 쓰기 모드를 허용한다면 쓰기 메소드는 pipe_write() 함수로 구현하고, 그렇지 않으면 에러 코드를 반환하는 bad_pipe_w()로 구현한다.
4) 시스템 V IPC(Inter-Process Communication)
(1) IPC의 개념
․IPC는 사용자 모드 프로세스가 다음과 같은 일을 할 수 있게 하는 시스템 콜 집합을 나타낸다. 세마포어를 이용하여 다른 프로세스와 동기화하기
- 다른 프로세스로 메시지를 보내거나 다른 프로세스로부터 메시지 받기
- 다른 프로세스와 메모리 영역 공유하기
(2) IPC의 자료구조
․IPC 자료 구조는 프로세스가 IPC 자원(세마포어, 메시지 큐나 공유 메모리 영역 등)을 요청할 때마다 동적으로 생성된다.
․각 IPC 자원은 프로세스가 명시적으로 제거하지 않으면 시스템을 종료할 때까지 계속 메모리에 남아 있다. IPC 자원을 생성한 프로세스와 조상 프로세스를 공유하지 않는 모든 프로세스도 이 자원을 이용할 수 있다.
․프로세스가 같은 유형의 IPC 자원을 여러 개 요청할 수 있으므로 각각의 새로운 자원은 32비트 IPC 키로 구별한다. 이 키는 시스템 디렉토리 트리의 파일 경로 이름과 비슷하다. 또한 각 IPC 자원은 IPC 식별자를 가진다. 이는 파일인 경우의 파일 디스크립터와 비슷하다.
․IPC 식별자는 커널이 할당하며 시스템 안에서 유일하다. 반면 IPC 키는 프로그래머가 임의로 선택할 수 있다. 프로세스 두 개 이상이 IPC자원을 이용하여 통신하려면 자원의 IPC식별자를 참조한다.
(3) IPC 식별자 계산법
․ IPC 식별자는 자원 유형과 관련된 슬롯 사용 시퀀스 번호(slot usage sequence number)와 할당된 자원에 대한 임의의 슬롯 인덱스 그리고 할당 가능한 자원의 최대 수보다 크며 커널이 선택한 임의의 수 조합으로 다음과 같이 계산된다.
IPC 식별자 = s * M + I
(s는 슬롯 사용 시퀀스 번호, M은 할당 가능한 자원의 최대 수, I는 슬롯 인덱스)
․리눅스 2.4에서는 M의 값은 32768로 설정되어 있다. 슬롯 사용 시퀀스 번호 s는 0으로 초기화되며 각 자원을 할당할 때마다 1씩 증가한다. s가 IPC 자원의 유형에 따라 미리 정의된 값(threshold)에 도달하게 되면 다시 0부터 시작하게 된다.
(4) IPC 자원의 생성
․IPC 자원은 새로운 자원이 세마포어, 메시지 큐나 공유 메모리 영역인지에 따라 semget(), msgget()이나 sgmget() 함수를 호출함으로써 생성된다.
․이러한 함수들의 주목적은 IPC 키(첫 번째 매개 변수)에 대응하는 IPC 식별자를 얻는 것이다.
․프로세스는 자원에 접근하기 위해 이 식별자를 이용한다.
만약 IPC 키에 대응하는 IPC 자원이 없다면 새로운 자원이 생성된다. 모든 일이 제대로 되었다면 함수는 양수인 IPC 식별자를 반환하고, 그렇지 않다면 에러 코드를 반환한다.
(5) 세마포어(Semaphore)
․세마포어는 여러 프로세스가 공유하는 자료 구조에 대한 통제된 접근 방법을 제공하기 위해 사용하는 카운터다. 세마포어의 가장 단순한 형태는 메모리의 한 위치에 있는 변수로, 그 값을 하나 이상의 프로세스가 검사하고 설정(test and set)할 수 있는 것이다. 이 검사 및 설정(test and set) 연산은 각 프로세스에 있어서 중단될 수 없는 원자성을 가진 것이다. 즉 한번 시작되면 아무 것도 이를 중단할 수 없다.
※ 세마포어의 특성
세마포어는 여러 프로세스가 공유하는 자료 구조에 대한 통제된 접근 방법을 제공하기 위해 사용하는 카운터다. 세마포어의 가장 단순한 형태는 메모리의 한 위치에 있는 변수로, 그 값을 하나 이상의 프로세스가 검사하고 설정(test and set)할 수 있는 것이다. 이 검사 및 설정(test and set) 연산은 각 프로세스에 있어서 중단될 수 없는 원자성을 가진 것이다. 즉 한번 시작되면 아무 것도 이를 중단할 수 없다.
세마포어 값은 보호된 자원을 이용 가능하면 양의 정수를 가지며, 보호된 자원을 현재 이용 불가능하면 0이다. 자원에 접근하려는 프로세스는 세마포어 값을 감소시킨다. 그러나 세마포어 값이 0이면 커널은 세마포어 값이 양수가 될 때까지 프로세스를 블록한다. 프로세스가 보호된 자원을 해제하면 세마포어 값을 감소시키고, 이렇게 함으로써 세마포어에 대기 중인 다른 프로세스가 깨어나게 된다.
각 IPC 세마포어는 세마포어 값 하나 이상을 가지는 집합이고, IPC 세마포어에는 프로세스가 세마포어에 내린 이전 연산을 취소하지 못하고 죽는 상황에 대한 실패 대비(fail-safe) 메커니즘이 있다. 이런 연산을 취소 가능(undoable) 세마포어 연산이라 한다. 세마포어는 동시에 한 프로세스만이 실행해야 하는 중요한 코드가 있는 임계구역(critical region)을 구현하는데 사용할수 있다.
IPC세마포어로 보호된 자원 하나이상에 접근하려는 프로세스동작의 전형적인단계는 다음과 같다.
① IPC 세마포어 식별자를 얻기 위해 semget() 래퍼 함수를 호출한다. 매개 변수로는 공유자원을 보호하는 IPC 세마포어의 IPC 키를 전달한다. 프로세스가 새로운 IPC 세마포어를 생성하려면 IPC_CRATE 또는 IPC_PRIVATE 플래그와 필요한 기본 세마포어의 수도 지정한다.
② semop() 래퍼 함수를 호출하여 모든 기본 세마포어 값을 테스트하고 감소시킨다. 모든 테스트를 성공하면 세마포어 값을 줄이고 함수를 종료한다. 그러면 프로세스는 보호된 자원에 접근할 수 있게 된다. 이미 사용 중인 세마포어가 있다면 프로세스는 다른 프로세스가 자원을 해제할 때까지 보류된다.
③ 보호된 자원을 풀어줄 때 semop() 함수를 다시 호출하여 관련된 모든 기본 세마포어를 한 번에 증가시킨다.
④ 옵션으로 IPC_RMID 명령을 지정하여 semctl() 래퍼 함수를 호출하여 시스템에서 IPC 세마포어를 제거한다.
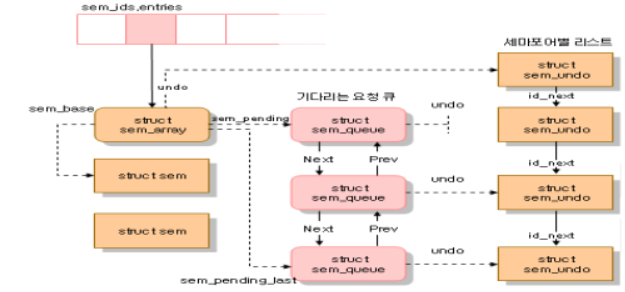
위의 그림은 IPC 세마포어의 자료 구조를 나타낸 것이다. sem_ids 변수는 IPC 세마포어 자원 유형인 ipc_ids 자료 구조를 저장한다. ipc_ids 자료 구조의 entries 필드는 sem_array 자료 구조를 가리키는 포인터의 배열이며, 각 항목은 IPC 세마포어 자원 하나씩 가리킨다. 배열은 kern_ipc_perm 자료 구조의 포인터를 저장하지만 사실 각각의 자료 구조는 sem_array 자료 구조의 첫 번째 필드다. sem_array 자료 구조의 모든 필드는 다음의 표와 같다.
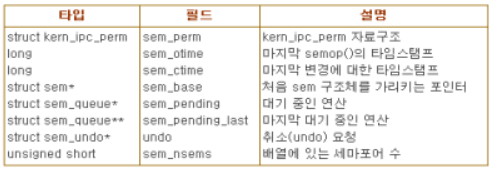
sem_base 필드는 struct sem 자료 구조의 배열을 가리킨다. 배열의 각 자료 구조는 IPC 세마포어 하나를 나타낸다. 이 자료 구조는 semval과 sempid의 두 필드를 포함한다. semval은 세마포어의 카운터 값이다. sempid는 세마포어에 마지막으로 접근한 프로세스의 PID로, 이 PID 값은 프로세스가 semctl() 래퍼 함수를 사용하여 질의할 수 있다.
(6) 메시지 큐(Message Queue)
․프로세스가 생성한 각 메시지는 IPC메시지 큐로 전송되며 다른 프로세스가 읽을 때까지 메시지 큐에 머문다. 메시지는 고정된 크기의 헤더(header)와 가변 크기 텍스트로 이루어진다. 메시지에는 메시지 유형을 나타내는 정수 값이 붙을 수 있으며 이러한 정수 값을 이용하여 프로세스는 연결 리스트로 구현된 메시지 큐에서 선택적으로 메시지를 읽을 수 있다. IPC 메시지 큐에서 프로세스가 메시지를 읽으면 커널은 메시지를 제거한다. 그러므로 단 한프로세스만이 주어진 메시지를 받게 된다.
※ 메시지 큐의 특성
프로세스가 생성한 각 메시지는 IPC 메시지 큐로 전송되며 다른 프로세스가 읽을 때까지 메시지 큐에 머문다. 메시지는 고정된 크기의 헤더(header)와 가변 크기 텍스트(text)로 이루어진다. 메시지에는 메시지 유형을 나타내는 정수 값이 붙을 수 있으며 이러한 정수 값을 이용하여 프로세스는 연결 리스트로 구현된 메시지 큐에서 선택적으로 메시지를 읽을 수 있다. IPC 메시지 큐에서 프로세스가 메시지를 읽으면 커널은 메시지를 제거한다. 그러므로 단 한 프로세스만이 주어진 메시지를 받게 된다.
프로세스는 메시지를 보낼 때에는 msgsnd() 함수를 호출하고, 메시지를 받을 때에는 msgrcv() 함수를 호출한다. msgsnd() 함수는 목적지 메시지 큐 자원의 IPC 식별자, 메시지 텍스트의 크기, 메시지 유형과 뒤에 바로 따라오는 메시지 텍스트를 포함하는 사용자 모드 버퍼의 주소를 매개 변수로 받으며, msgrcv() 함수는 IPC 메시지 큐 자원의 IPC 식별자, 메시지 유형과 메시지 텍스트를 복사할 사용자 모드 버퍼의 포인터, 버퍼 크기, 어떤 메시지를 받을 것인가를 나타내는 값 t를 매개 변수로 받는다. t 값이 0이면 큐에 있는 첫 번째 메시지를 반환한다. t가 양수이면 메시지 큐에 있는 t와 같은 유형의 처음 메시지를 반환한다. 마지막으로 t가 음수이면 함수는 값이 t의 절대값보다 작거나 같은 가장 작은 메시지 유형의 처음 메시지를 반환한다.
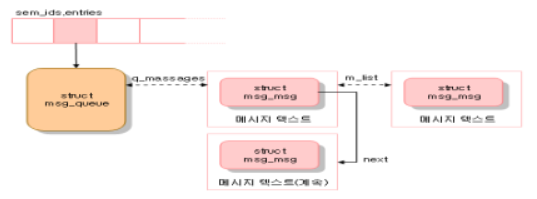
위의 그림은 IPC 메시지 큐와 관련 있는 자료 구조를 보여준다. msg_ids 변수에는 IPC 메시지 큐 자원 유형의 ipc_ids 자료 구조를 저장한다. entries 필드는 msg_queue 자료 구조에 대한 포인터의 배열로, 각 항목은 IPC 메시지 큐 자원 하나를 나타낸다. 형식적으로 배열은 kern_ipc_perm 자료 구조의 포인터를 저장하지만 사실 각 구조체는 msg_queue 자료 구조의 첫 번째 필드다. msg_queue 자료 구조 중 가장 중요한 필드는 q_messages다. 이 필드는 현재 큐에 있는 모든 메시지를 포함하고 있는 이중 연결 원형 리스트의 헤드를 나타낸다.
각 메시지는 동적으로 할당된 페이지 하나 이상에 분할되어 들어간다. 첫 번째 페이지의 시작 부분에 msg_msg 타입인 자료 구조로 된 메시지 헤더가 저장된다. 이 자료 구조의 필드는 아래의 표와 같다.
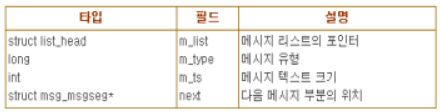
m_list 필드에는 큐에서의 이전과 다음 메시지를 가리키는 포인터를 저장한다. 메시지 텍스트는 msg_msg 디스크립터 바로 다음에서 시작한다. 메시지가 4072 바이트(페이지 크기- msg_msg 디스크립터 크기)보다 길다면 다음 페이지에서 계속되며 이 페이지 주소는 msg_msg 디스크립터의 next 필드에 저장된다. 두 번째 페이지 프레임은 msg_msgseg 타입 디스크립터로 시작한다. msg_msgseg는 세 번째 페이지의 주소를 저장하고 있는 next 포인터만을 담고 있다.
메시지 큐가 이용 가능한 메시지의 최대 수에 도달하거나 전체 크기의 최대 값에 도달한 경우 새로운 메시지를 큐에 넣으려는 프로세스는 블록된다. msg_queue 자료 구조의 q_senders 필드는 모든 블록된 전송 측 프로세스의 디스크립터를 가리키는 포인터를 담고 있는 리스트의 헤드이다. 수신 측 프로세스도 메시지 큐가 비어 있거나 프로세스가 지정한 유형의 메시지가 큐에 없을 때에는 블록될 수 있다. msg_queue 자료 구조의 q_receivers 필드는 블록된 수신 측 프로세스를 나타내는 msg_receiver 자료 구조 리스트의 헤드다. 각 자료 구조는 프로세스의 디스크립터를 가리키는 포인터, 메시지의 msg_msg 구조체를 가리키는 포인터, 요청한 메시지 유형을 담고 있다.
(7) 공유 메모리(Shared Memory)
․가장 유용한 IPC 메커니즘은 공유 메모리이다. 공유 메모리는 공통 자료 구조를 IPC 공유 메모리 영역에 넣으면 프로세스 둘 이상이 해당 공통 자료 구조에 접근할 수 있게 해준다. IPC 공유 메모리 영역에 있는 자료 구조에 접근하려는 프로세스는 IPC 공유 메모리 영역의 페이지 프레임에 매핑되는 새로운 메모리 영역을 프로세스 자신의 주소 공간에 추가해야 한다. 세마포어와 메시지 큐와 마찬가지로 shmget() 함수를 호출하여 공유 메모리 영역의 IPC 식별자를 얻을 수 있다. 이미 존재하는 공유 메모리 영역이 아니라면 새로 생성한다.
※ 공유 메모리의 특성
가장 유용한 IPC 메커니즘은 공유 메모리이다. 공유 메모리는 공통 자료 구조를 IPC 공유 메모리 영역에 넣으면 프로세스 둘 이상이 해당 공통 자료 구조에 접근할 수 있게 해준다. IPC 공유 메모리 영역에 있는 자료 구조에 접근하려는 프로세스는 IPC 공유 메모리 영역의 페이지 프레임에 매핑되는 새로운 메모리 영역을 프로세스 자신의 주소 공간에 추가해야 한다. 세마포어와 메시지 큐와 마찬가지로 shmget() 함수를 호출하여 공유 메모리 영역의 IPC 식별자를 얻을 수 있다. 이미 존재하는 공유 메모리 영역이 아니라면 새로 생성한다.
shmat() 함수를 호출하여 IPC 공유 메모리 영역을 프로세스에 붙일(attach) 수 있다. 이 함수는 IPC 공유 메모리 자원의 식별자를 매개 변수로 받으며, 호출한 프로세스의 주소 공간에 공유 메모리 영역을 추가한다. shmdr() 함수는 IPC 식별자가 명시한 IPC 메모리 영역을 떼어내기(detach) 위해, 즉 프로세스 주소 공간에 대응되는 메모리 영역을 제고하기 위해 호출한다.
IPC 공유 메모리 자원은 지속적이기 때문에 해당 자원을 이용하는 프로세스가 없어지고 대응되는 페이지가 스왑 아웃되더라도 공유 메모리 영역은 제거할 수 없다. IPC 자원의 다른 유형들처럼 사용자 모드 프로세스가 공유 메모리를 너무 많이 사용하는 것을 방지하기 위해 IPC 공유 영역의 수(기본으로 4096)와 각 세그먼트의 크기(기본으로 32M 바이트), 그리고 모든 세그먼트의 최대 총 사용량(8G 바이트) 제한이 있다.
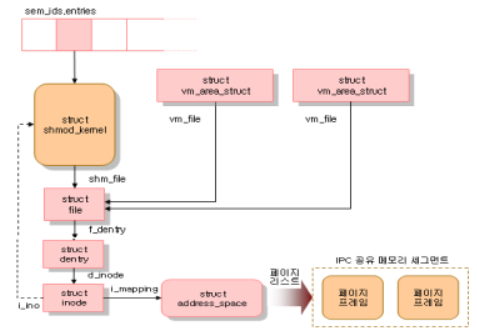
위의 그림은 IPC 공유 메모리에 관련한 자료 구조를 보여준다. shm_ids 변수는 IPC 공유 메모리 자원 유형의 ipc_ids 자료 구조를 저장한다. entries 필드는 IPC 공유 메모리 자원을 나타내는 shmid_kernel 자료 구조를 가리키는 포인터의 배열이다. 형식적으로 배열은 kerm_ipc_perm 자료 구조를 가리키는 포인터를 저장하지만, 각 구조체는 단순히 shmid_kernel 자료 구조의 첫 번째 필드이다. shmid_kernel 자료 구조의 필드는 다음의 표와 같다.
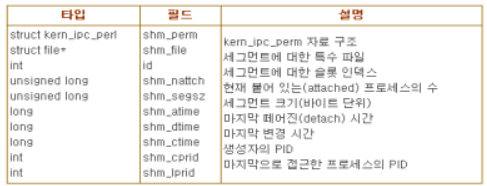
위의 표에서 가장 중요한 필드는 파일 객체의 주소를 저장하고 있는 shm_file이다. 이것은 리눅스 2.4의 VFS 계층과 IPC 공유 메모리의 밀접한 통합을 반영한다. 또한 각 IPC 공유 메모리 영역은 shm 특수 파일시스템에 속한 정규 파일과 대응한다.
shm 파일시스템은 시스템 디렉토리에 마운트 포인트가 없기 때문에 사용자는 일반적인 VFS 시스템 콜을 이용하여 열거나 접근할 수 없다. 그러나 프로세스가 세그먼트 하나를 붙일 때마다 커널은 do_mmap()을 호출하고, 파일의 새로운 공유 메모리 매핑을 프로세스의 주소 공간에 생성한다. 그러므로 shm 특수 파일시스템에 속한 파일은 하나뿐인 파일 객체 메소드(mmap)를 가지며, 이 메소드는 shm_mmap 함수로 구현된다.
IPC 공유 메모리 영역과 대응하는 메모리 영역은 vm_area_struct 객체로 표현된다. 이 객체의 vm_file 필드는 다시 특수 파일의 파일 객체를 가리키고, 파일 객체는 디엔트리 객체와 아이노드 객체를 가리킨다. 아이노드의 i_ino 필드에 저장된 아이노드 번호는 실제로는 IPC 공유 메모리 영역의 슬롯 인덱스이기 때문에 아이노드 객체는 shmid_kernel 디스크립터를 간접적으로 참조하게 된다. 모든 공유 메모리 영역에 대해서 IPC 공유 메모리에 속한 페이지 프레임은 아이노드의 i_mapping 필드를 통해 참조하는 address_space 객체 형태로 페이지 캐시에 포함된다.



'정보과학 > 운영체제특론' 카테고리의 다른 글
| 파일 및 입출력 장치 관리 커널 (0) | 2023.12.16 |
|---|---|
| 메모리 관리 커널 (0) | 2023.12.16 |
| 프로세서 관리 커널 1 (0) | 2023.12.13 |
| 임베디드 시스템과 리눅스 (0) | 2023.12.13 |
| 운영체제 보안 (1) | 2023.12.11 |



