1. 가상 파일시스템
․가상 파일시스템(VFS : Virtual File System)은 표준 유닉스 파일시스템이 제공하는 모든 시스템 콜을 처리하는 커널 소프트웨어 계층을 말합니다.
1) 가상 파일시스템의 개념
․가상 파일시스템(VFS : Virtual File System)은 표준 유닉스 파일시스템이 제공하는 모든 시스템 콜을 처리하는 커널 소프트웨어 계층으로, 애플리케이션 프로그램과 파일시스템 구현 사이의 추상 계층입니다.
(1) 가상파일시스템의 개념
․가상 파일시스템(VFS : Virtual File System)은 표준 유닉스 파일시스템이 제공하는 모든 시스템 콜을 처리하는 커널 소프트웨어 계층으로, 애플리케이션 프로그램과 파일시스템 구현 사이의 추상 계층이다.
․VFS의 장점은 여러 종류의 파일시스템에 대해 공통 인터페이스를 제공한다는 점이다.
(2) VFS가 지원하는 파일 시스템
․VFS가 지원하는 파일시스템은 크게 다음과 같이 세 부류로 나눌 수 있다.
| 디스크 기반 파일시스템 | 로컬 디스크 파티션의 기억 장소를 관리한다. VFS가 지원하는 잘 알려진 디스크 기반 파일 시스템은 다음과 같다. - Ext2, Ext3, ReiserFS 같은 리눅스의 독자적인 파일시스템. - SYSV(시스템 Ⅴ, Coherent, XENIX), UFS(BSD, Solaris, NeXT), MINIX 파일시스템, 베리타스 VxFS(SCO 유닉스웨어) 등 다른 유닉스를 위한 파일시스템. - MS-DOS, VFAT(윈도우 95, 윈도우 98), NTFS(윈도우 NT, 윈도우 2000) 같은 마이크로소프트 파일시스템. - ISO9660 CD-ROM 파일시스템(전 하이 시에라 파일시스템), 유니버설 디스크 포맷(UDF) DVD 파일시스템. - IBM OS/2(HPFS), 애플 매킨토시(HFS), 아미가 패스트 파일시스템(AFFS), 아콘 디스크 파일시스템(ADFS) 등 기타 전용 파일시스템. - IBM의 JFS, SGI의 XFS 등 리눅스 이외의 시스템에서 유래한 추가적인 저널링 파일시스템. |
| 네트워크 파일 시스템 | *네트워크로 연결된 다른 컴퓨터의 파일시스템에 있는 파일에 쉽게 접근하게 해준다. VFS가 지원하는 잘 알려진 네트워크 파일시스템으로는 NFS, Coda, AFS(앤드류 파일시스템), SMB(서버 메시지 블록, 마이크로소프트 윈도우, IBM OS/2 랜 매니저에서 파일과 프린터 공유를 위해 사용.), NCP(노벨 넷웨어 코어 프로토콜) 등이 있다. |
| 특수 파일시스템(가장 파일시스템) | *자신의 컴퓨터나 다른 컴퓨터의 실제 디스크 공간을 관리하지 않는다. /proc 파일시스템은 전형적인 특수 파일시스템이다. *VFS의 핵심 개념은 지원하는 모든 파일시스템을 표현할 수 있는 공통 파일 모델(common file model)을 도입하는 것이다. 그러나 각각의 특정 파일시스템을 구현하려면 반드시 자신의 특정한 물리적인 구성을 VFS의 공통 파일 모델로 변환해야 한다. *본래 리눅스 커널은 read()나 ioctl() 연산을 처리하는 특정 함수를 직접 구현(hardcore)할 수 없다. 대신 각 연산에 대해 포인터를 사용해야 한다. 포인터는 접근할 특정 파일시스템을 위한 적절한 함수를 가리키게 한다. |
(2) 공통 파일 모델
․공통 파일 모델은 객체 지향으로 볼 수도 있는데, 여기서 객체는 자료 구조와 이에 대한 연산을 수행하는 메소드를 한 번에 정의하는 소프트웨어 구조다.
․성능을 높이기 위해 리눅스는 C++와 같은 객체 지향 언어로 작성되지 않았다. 리눅스는 대부분 C로 작성되어 있으며, 어셈블리 코드도 포함하고 있다. 따라서 객체의 메소드에 대응하는 함수를 가리키는 항목을 포함한 자료 구조로 객체를 구현한다.
․공통 파일 모델은 다음과 같은 객체 유형으로 이루어진다.
*슈퍼블록 객체
- 마운트된 파일시스템에 대한 정보를 저장한다.
- 디스크 기반 파일시스템의 경우 이 객체는 일반적으로 디스크에 저장한 파일시스템 제어 블록(filesystem control block)에 대응한다.
*아이노드 객체
- 특정 파일에 대한 일반 정보를 저장한다.
- 디스크 기반 파일시스템의 경우 이 객체는 일반적으로 디스크에 저장한 파일 제어 블록(file control block)에 대응한다.
- 각 아이노드 객체에는 아이노드 번호가 할당되어 파일시스템 내에 있는 각 파일을 유일하게 식별한다.
*파일 객체
- 열린 파일과 프로세스 사이의 상호 작용과 관련한 정보를 저장한다.
- 이 정보는 각 프로세스가 파일에 접근하는 동안 커널 메모리에만 존재한다.
*디렉토리 객체
- 디렉토리 항목과 이에 대응하는 파일의 연결에 대한 정보를 저장한다.
- 각 디스크 기반 파일시스템에서는 독자적인 방법으로 이 정보를 디스크에 저장한다.
(3) 프로세스와 VFS 객체의 상호작용
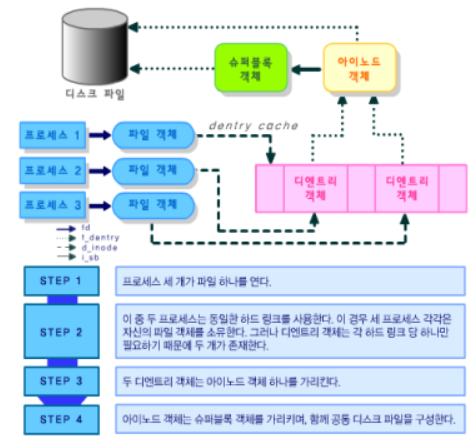
(4) VFS의 기타 역할
․VFS는 모든 파일시스템에 대한 공통 인터페이스를 제공하는 일 외에도 시스템 성능과 관련한 중요한 역할을 한다.
․가장 최근에 사용한 디엔트리 객체를 디엔트리 캐시(dentry cache)라는 디스크 캐시에 저장한다. 이렇게 함으로써 파일 경로명을 경로명의 마지막 구성 요소인 파일의 아이노드로 변환하는 속도를 높인다.
․일반적으로 디스크 캐시(disk cache)는 보통 디스크에 저장하는 정보 중 일부를 램에 저장하여 이후 이 정보에 접근할 때 더는 느린 디스크에 접근하지 않고 빨리 처리하도록 하는 소프트웨어 메커니즘이다.
2) 가상 파일시스템 자료 구조
․각 VFS 객체는 객체 속성과 객체 메소드의 테이블에 대한 포인터로 이루어진 적절한 자료 구조에 저장됩니다. 커널은 동적으로 객체의 메소드를 변경할 수 있으며, 특정 객체에 대해 특수한 동작을 설정할 수도 있습니다.
(1) super_block 구조체 유형
․슈퍼블록 객체는 super_block 구조체 유형으로 되어 있다.
․마운트된 파일시스템마다 하나씩 있는 모든 슈퍼블록 객체는 원형 이중 연결 리스트로 연결되어 있다.
․super_blocks 변수가 리스트의 처음 요소를 나타내며, 슈퍼블록 객체의 s_list 필드에는 리스트에 인접한 요소의 포인터가 있다.
(2) u 공용체 필드
․슈퍼블록 객체의 마지막 u 공용체 필드는 특정 파일시스템에 속한 슈퍼블록 정보를 포함한다.
․일반적으로 u 필드의 정보는 효율을 높이기 위해 메모리에 복제된다.
․모든 디스크 기반 파일시스템은 디스크 블록을 할당하고 해제하기 위해 할당 비트맵을 읽고 변경해야 하며, VFS는 이들 파일시스템이 디스크에 접근하지 않고 메모리에 있는 슈퍼블록의 u 공용체 필드를 직접 사용하도록 한다.
․그러나 이 접근 방법은 새로운 문제를 야기한다. VFS 슈퍼블록이 디스크의 대응하는 슈퍼블록과 더는 동기화 되지(synchronized) 않을 수도 있다.
․이를 해결하기 위해 s_dirt 플래그를 도입하여 디스크의 자료를 갱신해야 하는지 여부를 표시한다.
․동기화가 취약하면 사용자에게 시스템을 클린 상태로 셧다운할 기회를 주지 않고 갑자기 전원이 나간 경우 파일시스템이 깨지는 문제가 발생한다.
․따라서 리눅스는 주기적으로 모든 더티 슈퍼블록을 디스크에 기록함으로써 이 문제를 최소화한다.
(3) 슈퍼블록 연산(superblock operation)
․슈퍼블록과 관련한 메소드를 슈퍼블록 연산(superblock operation)이라고 한다.
․superblock_operations 구조체로 이를 표현하며, 구조체의 주소는 s_op 필드에 저장되어 있다. 각각의 특정 파일시스템은 자신의 슈퍼블록 연산을 정의할 수 있다.
(4) 아이노드 자료 구조
․파일시스템이 파일을 다루는 데 필요한 모든 정보는 아이노드라는 자료 구조에 들어 있다. 파일명은 임시로 할당한 이름표 같은 것으로, 언제나 변경할 수 있다. 그러나 아이노드는 각 파일에 유일하며, 파일이 존재하는 동안 그대로 남아 있다. 메모리 내에 있는 아이노드 객체는 inode 구조체로 이루어진다.
․각 아이노드 객체는 아래와 같은 원형 이중 연결 리스트 중 하나에 언제나 포함되며, 이 리스트 항목은 각 아이노드 객체의 i_list 필드로 서로 연결된다.
*유효하며 사용하고 있지 않은 아이노드 리스트
- 유효한 디스크 아이노드의 내용을 담고 있지만 현재 이 아이노드를 사용 하고 있는 프로세스는 없다.
- 이 아이노드는 더티가 아니며, i_count 필드의 값은 0이다.
이 리스트의 처음과 마지막 요소는 inode_unused 변수의 next, prev 필드로 참조한다.
이 리스트는 디스크 캐시로 동작한다
*사용 중인 아이노드 리스트
- 유효한 디스크 아이노드의 내용을 담고 있으며 현재 어떤 프로세스가 사용하고 있다.
- 아이노드는 더티가 아니며, i_count 필드의 값은 양수다. 리스트의 처음과 마지막 요소는 inode_in_use 변수로 참조한다.
*더티 아이노드 리스트
- 리스트의 처음과 마지막 요소는 대응하는 슈퍼블록 객체의 s_dirty 필드로 참조한다.
- 아이노드 객체는 inode_hashtable이라는 해시 테이블에도 포함된다. 해시 테이블은 커널이 아이노드 번호와 해당 파일을 포함한 파일시스템에 대응하는 슈퍼블록 객체 주소를 알고 있을 때 아이노드 객체를 찾는 검색 속도를 빠르게 해준다. 해싱은 충돌을 일으킬 수 있으므로 아이노드 객체는 같은 위치로 해시하는 다른 아이노드를 가리키는 양방향 포인터를 가지는 i_hash 필드를 포함한다. 이 필드는 같은 위치로 해시되는 아이노드의 이중 연결 리스트를 구성한다. 해시 테이블은 슈퍼블록에 할당되지 않은 아이노드의 특별한 연결 리스트도 포함한다.
이 리스트의 처음과 마지막 요소는 anon_hash_chain 변수로 참조한다.
- 아이노드 객체와 관련한 메소드를 아이노드 연산(inode operation)이라 한다. 아이노드 연산은 inode_operations 구조체로 표현하며, i_op 필드에 주소를 넣는다.
- 파일 객체는 프로세스가 열린 파일과 어떻게 상호 작용하는지 나타낸다. 이 객체는 파일을 열 때 생성되며, file 구조체로 구성된다.
파일 객체는 디스크에 대응하는 이미지가 없으며, 따라서 file 구조체에는 파일 객체 변경 여부를 나타내는 더티 필드가 없다.
- 파일 객체에 저장하는 가장 중요한 정보는 파일 포인터(file pointer)이다. 파일 포인터는 파일에서의 현재 위치를 나타낸다. 여러 프로세스가 같은 파일에 동시에 접근할 수 있기 때문에 파일 포인터를 아이노드 객체에 저장할 수는 없다.
각 파일 객체는 언제나 아래의 원형 이중 연결 리스트 중 하나에 들어간다.
*사용 중이 아닌(unused) 파일 객체 리스트
- 이 리스트는 파일 객체의 메모리 캐시로 그리고 슈퍼유저를 위해 예약된 공간으로 동작한다.
- 이 공간을 사용하여 슈퍼유저는 시스템의 동적 메모리를 전부 사용했다 하더라도 파일을 열 수 있다.
- 객체가 사용 중이 아니므로 f_count 필드 값은 0이다.
- 리스트의 첫 번째 요소는 더미(dummy)며, free_list 변수에 주소가 저장되어 있다. 커널은 리스트가 요소를 최소한 NR_RESERVED_FILES 객체의 값만큼 저장하고 있도록 한다.
이 값은 일반적으로 10이다.
*사용 중이며, 슈퍼블록에 할당되지 않은 파일 객체의 리스트
- 리스트 내에 있는 각 요소의 f_count 필드는 1로 설정된다. 리스트의 첫 번째 항목은 더미고, anon_list 변수에 저장되어 있다.
*사용 중이며, 슈퍼블록에 할당된 파일 객체의 리스트
- 각 슈퍼블록 객체는 s_file 필드에 파일 객체 리스트의 첫 번째 요소를 저장한다. 따라서 서로 다른 파일시스템에 속한 파일의 파일 객체는 서로 다른 리스트에 저장된다.
- 리스트 내에 있는 각 요소의 f_count 필드는 파일 객체를 사용 중인 프로세스 수의 합+1로 설정된다.
(5) inode_hashtable
․아이노드 객체는 inode_hashtable이라는 해시 테이블에도 포함된다.
․해시 테이블은 커널이 아이노드 번호와 해당 파일을 포함한 파일시스템에 대응하는 슈퍼블록 객체 주소를 알고 있을 때 아이노드 객체를 찾는 검색 속도를 빠르게 해준다.
․해싱은 충돌을 일으킬 수 있으므로 아이노드 객체는 같은 위치로 해시하는 다른 아이노드를 가리키는 양방향 포인터를 가지는 i_hash 필드를 포함한다. 이 필드는 같은 위치로 해시되는 아이노드의 이중 연결 리스트를 구성한다.
․해시 테이블은 슈퍼블록에 할당되지 않은 아이노드의 특별한 연결 리스트도 포함한다. 이 리스트의 처음과 마지막 요소는 anon_hash_chain 변수로 참조한다.
(6) 아이노드 연산(inode operation)
․아이노드 객체와 관련한 메소드를 아이노드 연산(inode operation)이라 한다. 아이노드 연산은 inode_operations 구조체로 표현하며, i_op 필드에 주소를 넣는다.
․파일 객체는 프로세스가 열린 파일과 어떻게 상호 작용하는지 나타낸다. 이 객체는 파일을 열 때 생성되며, file 구조체로 구성된다. 파일 객체는 디스크에 대응하는 이미지가 없으며, 따라서 file 구조체에는 파일 객체 변경 여부를 나타내는 더티 필드가 없다.
․파일 객체에 저장하는 가장 중요한 정보는 파일 포인터(file pointer)이다. 파일 포인터는 파일에서의 현재 위치를 나타낸다.
․여러 프로세스가 같은 파일에 동시에 접근할 수 있기 때문에 파일 포인터를 아이노드 객체에 저장할 수는 없다. 각 파일 객체는 언제나 아래의 원형 이중 연결 리스트 중 하나에 들어간다.
*사용 중이 아닌(unused) 파일 객체 리스트
- 이 리스트는 파일 객체의 메모리 캐시로 그리고 슈퍼유저를 위해 예약된 공간으로 동작한다.
- 이 공간을 사용하여 슈퍼유저는 시스템의 동적 메모리를 전부 사용했다 하더라도 파일을 열 수 있다.
- 객체가 사용 중이 아니므로 f_count 필드 값은 0이다.
- 리스트의 첫 번째 요소는 더미(dummy)며, free_list 변수에 주소가 저장되어 있다.
- 커널은 리스트가 요소를 최소한 NR_RESERVED_FILES 객체의 값만큼 저장하고 있도록 한다. 이 값은 일반적으로 10이다.
*사용 중이며, 슈퍼블록에 할당되지 않은 파일 객체의 리스트
- 리스트 내에 있는 각 요소의 f_count 필드는 1로 설정된다.
- 리스트의 첫 번째 항목은 더미고, anon_list 변수에 저장되어 있다.
*사용 중이며, 슈퍼블록에 할당된 파일 객체의 리스트
- 각 슈퍼블록 객체는 s_file 필드에 파일 객체 리스트의 첫 번째 요소를 저장한다.
- 서로 다른 파일시스템에 속한 파일의 파일 객체는 서로 다른 리스트에 저장된다.
- 리스트 내에 있는 각 요소의 f_count 필드는 파일 객체를 사용 중인 프로세스 수의 합+1로 설정된다.
(7) 파일포인터의 저장
․파일 객체가 어떤 순간에 어느 리스트에 있든, 리스트의 이전 항목과 다음 항목을 가리키는 포인터는 파일 객체의 f_list 필드에 저장된다.
․사용 중이 아닌 파일 객체 리스트의 크기는 files_stat 변수의 nr_free_files 필드에 저장한다.
․VFS는 새로운 파일 객체를 할당할 때 get_empty_filp() 함수를 호출한다. 이 함수는 사용 중이 아닌 리스트가 NR_RESERVED_FILES 값보다 많은 항목을 포함하고 있는지 검사하여, 더 많은 항목이 있다면 이 중 하나를 새로 연 파일에 사용한다.
․그렇지 않으면 일반적인 메모리 할당으로 대체한다.
․Files_stat 변수에는 nr_files 필드와 max_files 필드도 있다.
| nr_files 필드 | 모든 리스트에 포함되어 있는 파일 객체의 수 |
| max_files 필드 | 할당될 수 있는 최대 파일 객체의 수, 즉 시스템에서 동시에 접근할 수 있는 파일의 수 |
(8) 파일 연산(file operation) 집합
․각 파일시스템에는 파일 읽기 쓰기와 같은 작업을 위한 자신만의 파일 연산(file operation) 집합을 포함한다.
․커널은 아이노드를 디스크에서 메모리로 로드할 때 파일 연산에 대한 포인터를 file_operations 구조체에 저장한다. 이 구조체의 주소는 아이노드 객체의 i_fop 필드에 저장한다.
․프로세스가 파일을 열 때 VFS는 아이노드에 저장한 주소로 새로운 파일 객체의 f_op 필드 값을 초기화하여 이후 파일 연산에 대해 호출할 때 이 함수를 사용할 수 있도록 한다. 필요하다면 VFS는 새로운 값을 f_op에 저장하여 파일 연산 집합을 변경할 수도 있다.
(9) 디엔트리 객체의 이용
․VFS는 각 디렉토리 파일과 다른 디렉토리 리스트가 들어 있는 일반 파일로 간주한다.
․일단 디렉토리 엔트리를 메모리로 읽어온 다음에 VFS는 이 디렉토리 엔트리를 dentry 구조체의 디엔트리 객체로 변환한다.
․커널은 프로세스가 탐색하는 경로명의 모든 구성 요소에 대해 디엔트리 객체를 만든다. 디엔트리 객체는 각 구성 요소를 대응하는 아이노드와 연결해준다.
․디스크에는 디엔트리 객체에 대응하는 이미지가 없다. 따라서 dentry 구조체에는 객체가 변경되었다는 사실을 나타내는 필드가 없다.
․dentry_cache라는 슬랩 할당자 캐시(slab allocator cache)에 디엔트리 객체를 저장한다. kmem_cache_alloc()과 kmem_cache_free()를 호출하여 디엔트리 객체를 생성, 제거한다.
(10) 디엔트리 객체의 상태
․각 디엔트리 객체는 다음 네 상태 중 하나에 해당한다.
*해제(free)
- 이 디엔트리 객체는 의미 있는 정보를 담고 있지 않으며, VFS가 사용하고 있지 않다.
- 대응하는 메모리 영역은 슬랩 할당자(slab allocator)가 관리한다.
*사용 중이 아님(unused)
- 이 디엔트리 객체는 커널에서 사용하지 않고 있다.
- 객체의 d_count 사용 카운터는 0이다. 그러나 d_inode 필드는 아직 관련 아이노드를 가리키고 있다.
- 디엔트리 객체는 유효한 정보를 포함하지만 만약 메모리를 회수할 필요가 있다면 내용을 삭제할 것이다.
*사용 중(in use)
- 이 디엔트리 객체는 커널에서 사용하고 있다.
- d_count 사용 카운터는 양수고, d_inode 필드는 관련 아이노드 객체를 가리키고 있다.
- 디엔트리 객체는 유효한 정보를 담고 있으며, 이를 제거할 수 없다.
*네거티브(negative)
- 이 디엔트리에 대응하는 아이노드가 더는 존재하지 않는다.
- 대응하는 디스크 아이노드가 삭제되었거나, 존재하지 않는 파일의 경로명을 처리하면서 생성된디엔트리이기 때문이다.
- 디엔트리 객체의 d_inode 필드는 NULL로 설정된다. 그러나 디엔트리 객체는 계속 디엔트리 캐시에 남아 같은 파일 경로명에 대해 탐색 연산을 빠르게 처리할 수 있도록 한다.
- 음수(negative)라는 용어와는 달리 어떤 음수와도 관계가 없다.
(11) 디엔트리 캐시의 활용
․리눅스는 디엔트리를 처리하는 효율을 극대화하려고 디엔트리 캐시를 사용하는데, 이는 두 가지 자료 구조로 구성되어 있다.
1 : 사용 중, 사용 중이 아님, 또는 네거티브 상태에 있는 디엔트리 객체 집합
2 : 주어진 디렉토리와 파일명으로부터 이에 대응하는 디엔트리 객체를 얻기위한 해시 테이블. 일반적으로 요청한 객체가 디엔트리 캐시에 들어 있지 않은 경우, 해시 함수는 NULL 값을 반환한다.
․ 디엔트리 캐시는 아이노드 캐시(inode cache)에 대한 제어기 역할도 한다.
- 사용 중이 아닌 디엔트리에 대응하는 커널 메모리의 아이노드인 경우에는 디엔트리 캐시가 계속 사용하고 있으므로 제거되지 않는다.
- 따라서 아이노드 객체는 램에 남아 있고, 대응하는 디엔트리를 통해 빠르게 참조할 수 있다.
(12) 디엔트리 캐시의 작동
․사용 중이 아닌 디엔트리는 이중 연결 리스트인 가장 오래 전에 사용한(LRU:Least Recently Used) 리스트에 삽입 시간 순서대로 저장한다.
- 사용 중이 아닌 디엔트리는 이중 연결 리스트인 가장 오래 전에 사용한(LRU : Least Recently Used) 리스트에 삽입 시간 순서대로 저장한다.
- 바꿔 말하면, 가장 나중에 해제한 디엔트리 객체가 리스트의 맨 앞에 들어가며, 사용한지 가장 오래된 디엔트리 객체일수록 리스트의 끝에 위치한다.
- 커널은 디엔트리 캐시의 크기를 줄여야 할 때 리스트 끝 부분부터 요소를 제거하며, 최근에 사용한 객체들은 유지한다.
- LRU 리스트의 처음과 마지막 요소의 주소는 dentry_unused 변수의 next와 prev 필드에 각각 저장한다.
- 디엔트리 객체의 d_lru 필드는 리스트 내의 인접한 디엔트리의 포인터를 포함한다.
․사용 중인 디엔트리 객체는 대응하는 아이노드 객체의 i_dentry 필드가 나타내는 이중 연결 리스트에 삽입된다.
- 사용 중인 디엔트리 객체는 대응하는 아이노드 객체의 i_dentry 필드가 나타내는 이중 연결 리스트에 삽입된다.
- 각 아이노드는 여러 하드 링크를 가질 수 있으므로 리스트가 필요하다.
- 디엔트리 객체의 d_alias 필드는 리스트 내의 인접한 항목을 가리킨다. 두 필드는 struct_list_head 타입이다.
․대응하는 파일에 대한 마지막 하드 링크가 삭제되면 사용 중인 디엔트리 객체는 네거티브 상태가 된다.
- 대응하는 파일에 대한 마지막 하드 링크가 삭제되면 사용 중인 디엔트리 객체는 네거티브 상태가 된다.
- 이 경우 디엔트리 객체는 사용 중이 아닌 디엔트리 객체의 LRU 리스트로 이동한다.
- 커널이 디엔트리 캐시 크기를 줄일 때 네거티브인 디엔트리는 점차 LRU 리스트의 끝으로 이동하여 점차적으로 해제된다.
(13) dentry_hashtable 배열
․dentry_hashtable 배열을 사용하여 해시 테이블을 구현한다.
․각 항목은 해시 함수를 거치면 같은 해시 테이블 값으로 해시되는 디엔트리들의 리스트를 가리키는 포인터다.
․배열의 크기는 시스템의 메모리 용량에 따라 다르다.
․디엔트리 객체의 d_hash 필드는 해시 값이 같은 리스트의 인접 항목에 대한 포인터를 포함한다.
․해시 함수는 디렉토리와 파일명의 디엔트리 객체 주소 두 개로부터 해시 값을 생성한다.
․d_lookup() 함수는 매개 변수의 디엔트리 객체와 파일명에 대해 해시 테이블을 탐색한다.
(14) 디엔트리 연산(dentry operation)
․디엔트리 객체에 관련된 메소드를 디엔트리 연산(dentry operation)이라고 한다.
․이들은 dentry_operations 구조체로 표현하며, 주소는 d_op 필드에 있다.
․어떤 파일시스템은 독자적인 디엔트리 메소드를 정의하기도 하지만 필드 값은 대개 NULL이며,이 경우 VFS는 이들을 기본 함수로 대체한다.
2. EXT2 파일시스템
․최초의 리눅스 버전은 미닉스(Minix) 파일시스템을 기반으로 했지만, 리눅스가 성장하면서 확장 파일시스템(Ext FS)을 도입했습니다. 그 후 1994년에 2차 확장 파일시스템(Ext2)을 도입했는데, 이는 현재 가장 널리 사용되는 리눅스 파일시스템입니다.
1) EXT2의 일반적 특성
․ Ext2 파일시스템을 생성할 때 시스템 관리자는 예상하는 평균 파일 크기에 따라 최적의 블록 크기(1024~4096 바이트)를 선택할 수 있다.
․Ext2 파일시스템을 생성할 때 시스템 관리자는 예상하는 파일 수에 따라 같은 크기의 파티션에 들어갈 아이노드 수를 선택할 수 있다.
․파일시스템은 디스크 블록 몇 개를 그룹으로 관리한다. 따라서 단일 블록 그룹 내에 저장된 파일에 접근하는 데 필요한 디스크 탐색 시간은 평균보다 낮아진다.
․파일시스템은 디스크 데이터 블록을 사용하기 전에 정규 파일에 미리 할당한다. 이로 인해 파일 단편화를 줄일 수 있다.
․빠른 심볼릭 링크를 지원하므로 데이터 블록을 읽지 않고 경로명 변환이 가능하다.
․시스템 크래시(crash)로 인한 영향을 최소화하려고 파일 갱신 전략을 주의 깊게 구현했다.
․부트 과정에서 파일시스템 상태에 대한 일관성 검사를 자동으로 제공한다.
․변경 불가능 파일(파일을 수정, 삭제하거나 이름을 변경할 수 없다.), 추가 기능 파일(파일의 맨 끝에 데이터를 덧붙이는 것만 가능하다.)을 지원한다.
․새로운 파일의 그룹 ID에 유닉스 시스템 Ⅴ 릴리즈 4(SVR4), BSD 구현과 호환성을 제공한다.
2) EXT2의 디스크 자료 구조
․EXT2의 디스크 자료 구조를 살펴봅시다.
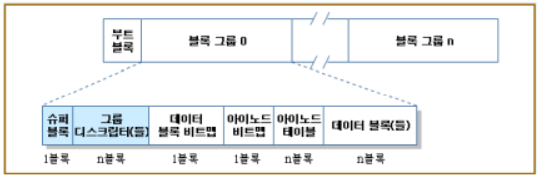
STEP1:EXT2의 각 블록의 내부배치는 아래 그림과 같다. 모든 Ext2 파티션의 첫 번째 블록은 Ext2 파일시스템이 관리하지 않는다. Ext2 파티션의 나머지 부분은 블록 그룹 단위로 나뉜다. 파티션의 첫 블록의 역할은 무엇인가?

▶교재 및 참고자료를 통해 EXT2의 자료 구조의 특성에 대해 정리합니다.
모든 Ext2 파티션의 첫 번째 블록은 Ext2 파일시스템이 관리하지 않는다. 이 블록은 파티션 부트 섹터를 위해 예약되어 있다.
STEP2:EXT2 디스크에서는 어떤 자료 구조는 반드시 한 블록에 저장해야 하고, 어떤 것은 한 블록 이상을 사용한다. 이때 얻는 효과는 무엇인가?
▶파일시스템의 모든 블록 그룹은 같은 크기며, 순차적으로 저장된다. 그러므로 커널은 블록 그룹의 정수 인덱스로부터 디스크에서 블록 그룹이 차지한 위치를 구할 수 있다.
또한 커널은 가능하면 한 파일의 데이터 블록을 같은 블록 그룹에 저장하려 하므로 블록 그룹은 파일 단편화를 줄이는 효과가 있다.
블록 그룹의 각 블록은 파일시스템의 슈퍼블록 복사본, 블록 그룹 디스크립터 그룹의 복사본, 데이터 블록 비트맵, 아이노드의 그룹, 아이노드 비트맵, 파일에 속한 한 데이터 블록 중의 한 가지 정보를 포함한다. 어떤 블록이 의미 있는 정보를 전혀 포함하지 않으면 여유(free) 블록이라고 한다.
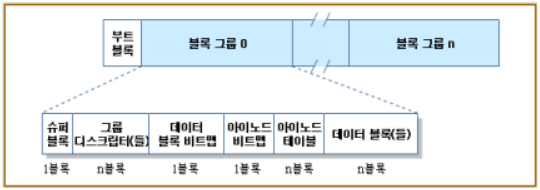
STEP3:슈퍼블록과 그룹 디스크립터는 각 블록 그룹에 복제되어 있다. 이 부분의 역할에 대해 살펴보자.
▶슈퍼블록과 그룹 디스크립터는 각 블록 그룹에 복제되어 있다. 커널은 블록 그룹 0에 속한 슈퍼블록과 그룹 디스크립터만 사용하며, 나머지 슈퍼블록과 그룹 디스크립터는 변경되지 않은 채 남아 있다.
/sbin/e2fsck 프로그램이 파일시스템 상태의 일관성 검사를 수행할 때 블록 그룹 0에 저장한 슈퍼블록과 그룹 디스크립터를 읽어서 다른 모든 블록 그룹에 복사한다. 데이터가 깨져서 블록 그룹 0의 슈퍼블록 또는 그룹 디스크립터를 사용할 수 없을 때 시스템 관리자는 /sbin/e2fsck에 첫 번째 블록 그룹 외의 블록 그룹에 저장한 슈퍼블록과 그룹 디스크립터를 사용하도록 지시할 수 있다.
일반적으로 이들 중복된 복사본은 /sbin/e2fsck가 Ext2 파티션을 일관성 있는 상태로 돌리는 데 충분한 정보를 담고 있다.
STEP4:파티션에서 블록 그룹의 수의 결정에 영향을 미치는 것은 무엇인가?
▶파티션에서 블록 그룹의 수는 파티션 크기와 블록 크기에 따라 결정된다. 한 가지 제약 조건은 그룹 내에서 사용 중인 블록과 여유 블록을 구분하기 위해 사용하는 블록 비트맵을 반드시 단일 블록에 저장해야 한다는 점이다. 따라서 블록 크기를 바이트 단위로 나타낸 값을 b라고 할 때, 각 블록 그룹에는 최대 8×b 개 블록이 있을 수 있다. 따라서 파티션의 블록 수를 s라고 할 때 블록 그룹 수는 대략 s/(8×b)이다.
(1) ext2_super_block 구조체
․Ext2 디스크 슈퍼블록은 ext2_super_block 구조체에 저장된다.
․s_inodes_count 필드는 Ext2 파일시스템에 있는 아이노드 수를 저장하고, s_blocks_count 필드는 블록 수를 저장한다.
․s_log_block_size 필드는 블록 크기를 2의 지수로 나타낸다. 단위는 1024바이트이다. 따라서 0은 1024바이트 블록을 나타내고, 1은 2048바이트 블록을 나타낸다.
․s_blocks_per_group, s_frags_per_group, s_inodes_per_group 필드는 각각 블록 그룹의 블록 수, 단편 수, 아이노드 수를 나타낸다.
※ 디스크 블록 예약
어느 정도의 디스크 블록은 슈퍼유저를 위해 예약되어 있다. 이 블록은 일반 사용자가 사용할 수 있는 여유 블록이 더는 없을 경우에도 시스템 관리자가 파일시스템을 사용할 수 있게 한다.
(2) s_mnt_count, s_max_mnt_count, s_lastcheck, s_checkinterval 필드
․s_mnt_count, s_max_mnt_count, s_lastcheck, s_checkinterval 필드는 부트 과정에서 Ext2 파일시스템을 자동으로 검사하도록 한다.
․이 필드들은 마운트 연산을 지정된 수만큼 실행했거나 마지막 일관성 검사 이후 지정된 시간이 경과했을 때 /sbin/e2fsck를 실행하게 한다.
․파일시스템이 언마운트되지 않았거나 커널이 파일시스템에서 어떤 에러를 발견했을 때도 부트 시간에 일관성 검사를 수행한다.
․s_state 필드는 파일시스템을 마운트한 상태이거나 제대로 언마운트하지 않았을 때 0을 저장하고, 제대로 언마운트했을 때 1을 저장하며, 에러를 포함하고 있을 때 2를 저장한다.
(3) 그룹 디스크립터
․각 블록 그룹에는 자신만의 그룹 디스크립터가 있다.
․새로운 아이노드와 데이터 블록을 할당할 때에는 bg_free_blocks_count, bg_free_inodes_cont, bg_used_dirs_count 필드들을 사용한다.
․이 필드들은 각 자료 구조를 할당하는 데 가장 적절한 블록을 선택할 때 사용한다.
․비트맵은 비트의 연속으로, 값이 0인 경우는 대응하는 아이노드 또는 데이터 블록이 여유 있다는 의미이고, 값이 1인 경우는 사용 중이라는 의미이다.
․각 비트맵은 반드시 단일 블록에 저장해야 하며, 블록 크기는 1024, 2048, 4096 바이트일 수 있으므로 비트맵 하나는 블록 8192, 16384, 32768 개의 상태를 나타낼 수 있다.
(4) 아이노드 테이블
․아이노드 테이블은 인접하는 연속된 블록으로 이루어져 있으며, 각 블록은 미리 정의된 수의 아이노드를 포함한다.
․아이노드 테이블에서 첫 번째 블록의 블록 번호는 그룹 디스크립터의 bg_inode_table 필드에 저장된다.
․모든 아이노드의 크기는 128바이트이다.
- 1024바이트 블록은 아이노드 8개를 포함하고, 4096바이트 블록은 아이노드 32개 를 포함한다.
- 아이노드 테이블이 얼마나 많은 블록을 차지하는지 알려면 그룹에 속하는 전체 아이노드 수를 블록 당 아이노드 수로 나누면 된다.
․각 Ext2 아이노드는 ext2_inode 구조체로 이루어져 있다
․i_size 필드는 파일의 실제 길이를 바이트 단위로 나타낸다.
- i_blocks 필드는 파일에 할당된 데이터 블록의 수(512바이트 단위)를 나타내는 것으로, 파일에 할당된 데이터 블록을 식별하는 데 사용하는 블록을 가리키는 포인터 EXT2_N_BLOCKS(보통 15) 개의 블록이다.
․i_size 필드를 위해 32비트가 예약되어 있으므로 파일 크기는 4GB로 제한된다. 그러나 실제로는 i_size 필드의 최상위 비트는 사용하지 않으므로 최대 파일 크기는 2GB로 제한된다.
(5) Ext2의 파일 유형
․Ext2의 파일 유형으로는 알 수 없음, 정규 파일, 디렉토리, 문자 장치, 블록 장치, 명명된(named) 파이프, 소켓, 심볼릭이 있으며, 파일 유형들은 데이터 블록을 서로 다른 방법으로 사용한다.
․어떤 파일은 데이터를 저장하지 않으므로 데이터 블록이 전혀 필요 없다.
․정규 파일은 가장 일반적인 경우로, 정규 파일에 데이터를 저장하기 시작하면 데이터 블록이 있어야 한다.
- 단지 처음 정규 파일을 생성할 때는 파일이 비어 있으므로 데이터 블록이 없어도 된다.
- 또한 truncate()나 open() 시스템 콜을 사용하여 다시 빈 파일로 만들 수 있다.
(6) Ext2의 디렉토리 유형
․Ext2의 디렉토리는 파일명과 이에 대응하는 아이노드 번호를 저장하는 데이터 블록으로 구성된 특별한 파일로 구현한다.
․데이터 블록은 ext2_dir_entry_2 타입 구조체로 이루어져 있다. - 이 구조체의 길이는 가변적이다.
- 마지막 name 필드가 최대 EXT2_NAME_LEN(보통 255)개 문자로 이루어진 길이가 가변적인 배열이기 때문이다.
- 효율성을 위해 디렉토리 엔트리 길이는 언제나 4의 배수며, 필요하다면 파일명 끝에 널 문자(\0)가 들어간다.
․심볼릭 링크의 경로명이 60자 이하이면, 4바이트 정수 15개로 구성된 배열인 아이노드 i_block 필드에 심볼릭 링크를 저장하며 데이터 블록을 사용하지 않는다.
․경로명이 60자 이상이면 데이터 블록 하나를 사용한다. 장치 파일, 파이프, 소켓과 같은 파일 유형에서는 모든 정보가 아이노드에 저장되므로 데이터 블록이 필요 없다.
3) EXT2의 메모리 자료 구조
(1) Ext2의 메모리 자료 구조 개요
․파일시스템을 마운트하면 Ext2 파티션의 디스크 자료 구조에 저장된 정보 중 대부분을 RAM에 복사하여, 커널이 디스크 읽기 연산을 여러 번 수행하지 않도록 한다.
․모든 Ext2 디스크 자료 구조를 Ext2 파티션의 블록에 저장하기 때문에 커널은 이런 자료 구조를 최신 상태로 유지하려고 버퍼 캐시에 페이지 캐시를 사용한다.
| 유형 | 디스크 자료 구조 | 메모리 자료 구조 | 캐싱 모드 |
| 슈퍼블록 그룹 디스크립터 블록 비트맵 아이노드 비트맵 아이노드 데이터 블록 여유 아이노드 여유 블록 |
ext2_super_block ext2_group_desc 블록에 저장된 비트 배열 블록에 저장된 비트 배열 ext2_inode 지정되지 않음 ext2_inode 지정되지 않음 |
ext2_sb_info ext2_group_desc 버퍼에 저장된 비트 배열 버퍼에 저장된 비트 배열 ext2_inode_info 버퍼 페이지 없음 없음 |
항상 캐시됨 항상 캐시됨 고정된 크기 고정된 크기 동적 동적 캐시되지 않음 캐시되지 않음 |
※ EXT2 파일 시스템과 파일에 관련한 규칙
위의 표는 Ext2 파일시스템과 파일에 관련한 각 데이터 유형에 대해 디스크에서 데이터를 표현하기 위해 사용하는 자료 구조, 메모리에서 커널이 사용하는 자료 구조 그리고 얼마나 많은 캐싱을 사용할지 결정하기 위한 간단한 규칙을 나타낸다.
자주 바뀌는 데이터는 언제나 캐시된다. 즉 데이터는 항상 버퍼 캐시나 페이지 캐시에 저장되고, 대응하는 Ext2 파티션이 언마운트될 때까지 버퍼 캐시에 저장되어 있다. 이를 위해 커널은 버퍼의 사용 카운터를 언제나 0보다 크게 유지한다. 캐시된 적이 없는 데이터는 의미 있는 정보를 담고 있지 않으므로 어떤 캐시에도 저장되지 않는다.
이 두 극단 사이에 두 가지 다른 모드 즉 고정된 제한 모드와 동적 모드가 있다.
고정된 제한(fixed limit) 모드에서는 지정된 자료 구조만 버퍼 캐시에 저장할 수 있다. 한계를 넘으면 오래된 자료 구조는 디스크로 플러시된다. 동적(dynamic) 모드에서 데이터는 대응하는 객체(아이노드 또는 블록)를 사용하는 동안에만 버퍼 캐시에 위치한다. 파일을 닫거나 데이터 블록을 삭제하면 shrink_caches() 함수가 대응하는 데이터를 캐시에서 제거한다.
(2) Ext2 파일시스템 마운트
․Ext2 파일시스템을 마운트하면 파일시스템 고유의 데이터를 포함하고 있는 VFS 슈퍼블록의 u 필드를 ext2_sb_info 구조체 형태로 로드하여 커널이 전체적인 파일시스템과 관련한 정보를 찾을 수 있게 한다.
․이와 유사하게 Ext2 파일과 관련한 아이노드 객체를 초기화하면 ext2_inode_info 구조체 형태로 u 필드를 로드한다.
․커널은 Ext2 파일시스템이 마운트되면 Ext2 디스크 슈퍼블록을 위한 버퍼를 할당하고 슈퍼블록의 내용을 디스크에서 읽는다.
․이 버퍼는 Ext2 파일시스템을 언마운트한 경우에만 해제한다.
․커널이 Ext2 슈퍼블록의 필드 내용을 변경해야 하는 경우 버퍼의 적절한 위치에 새로운 값을 기록하고 버퍼를 더티로 표시한다.
※ 리눅스에서의 EXT2 파일 시스템 마운트
리눅스는 Ext2 디스크립터의 메모리 요구를 제한하기 위해 모든 마운트된 Ext2 파일시스템에 대해 EXT2_MAX_GROUP_LOADED(보통 8) 크기인 캐시 두 개를 사용하는 방법을 채택했다. 한 캐시에는 가장 최근에 접근한 아이노드 비트맵을 저장하고, 다른 캐시에는 가장 최근에 접근한 블록 비트맵을 저장한다. 캐시에 포함된 비트맵을 포함하는 버퍼는 사용 카운터 값이 0보다 크기 때문에 shrink_mmap()이 해제하지 않는다. 반대로 비트맵 캐시에 없는 비트맵을 포함하는 버퍼는 사용 카운터 값이 0이기 때문에 여유 메모리가 모자라면 해제된다.
각 캐시는 요소를 EXT2_MAX_GROUP_LOADED개 포함하는 배열 두 개를 사용하여 구현한다. 한 배열에는 현재 캐시 안에 비트맵이 있는 블록 그룹의 인덱스를 저장하고, 다른 배열에는 비트맵을 참조하는 버퍼 헤드를 가리키는 포인터를 저장한다.
ext2_sb_info 구조체는 아이노드 비트맵 캐시와 관련한 배열을 저장한다. 블록 그룹의 인덱스는 s_inode_bitmap 필드에, 버퍼 헤드에 대한 포인터는 s_inode_bitmap_number 필드에 있다. s_block_bitmap과 s_block_bitmap_number 필드에는 블록 비트맵 캐시에 대응하는 배열을 저장한다.
load_inode_bitmap() 함수는 지정된 블록 그룹의 아이노드 비트맵을 로드하고, 비트맵이 들어 있는 캐시 위치를 반환한다.
비트맵이 비트맵 캐시에 없으면 load_inode_bitmap()은 read_inode_bitmap()을 호출한다. 이 함수는 그룹 디스크립터의 bg_inode_bitmap 필드에서 비트맵을 포함하는 블록 수를 얻은 다음 bread()를 호출하여 새로운 버퍼를 할당한다. 버퍼 캐시에 아직 없다면 디스크에서 블록을 읽는다.
Ext2 파티션의 블록 그룹 수가 EXT2_MAX_GROUP_LOADED보다 작거나 같으면 비트맵을 삽입할 캐시 배열 위치 인덱스는 항상 load_inode_bitmap() 함수에 매개 변수로 넘긴 블록 그룹 인덱스와 일치한다. 반면 캐시 공간보다 더 많은 블록 그룹이 있다면 LRU(Least Recently Used) 기법을 사용해서 캐시에서 비트맵을 제고하고, 요청한 비트맵을 첫 번째 캐시 위치에 넣는다.
(3) 마운트 된 Ext2 파일시스템의 메모리 구조
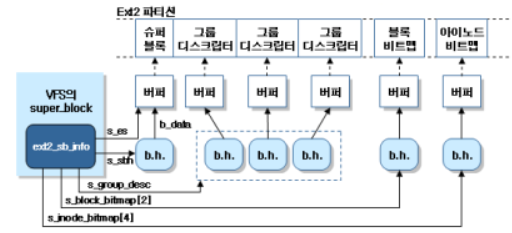
․디스크의 세 블록 안에는 디스크립터를 저장한 세 블록 그룹이 있다.
․ext2_sb_info의 s_group_desc 필드는 버퍼 헤드 세 개의 배열을 가리킨다.
․인덱스가 2인 아이노드 비트맵 하나와 인덱스가 4인 블록 비트맵 하나만 볼 수 있다.
․커널은 비트맵 캐시에 비트맵 2×EXT2_MAX_GROUP_LOADED개를 저장할 수 있으며, 더 많은 비트맵을 버퍼 캐시에 저장할 수 있다.
4) EXT2 파일시스템 생성
․디스크에 파일시스템을 생성하는 작업은 크게 두 단계로 이루어집다. 첫 번째 단계는 디스크를 포맷하는 것으로 디스크 드라이버가 디스크에 블록을 읽고 쓸 수 있게 하며, 두 번째 단계는 파일시스템을 생성하는 것으로 해당 구조체를 설정합니다.
(1) Ext2 파일시스템 생성
․/sbin/mke2fs 유틸리티 프로그램을 사용하여 Ext2 파일시스템을 생성할 수 있다.
․이 프로그램은 블록 크기는 1024바이트, 단편 크기는 블록 크기, 할당된 아이노드 개수는 4096바이트 당 아이노드 한 개, 예약된 블록의 비율은 5%와 같은 기본 옵션을 가정한다.
․사용자는 옵션을 변경하기 위해 명령에 플래그를 사용할 수 있다.
- 슈퍼블록과 그룹 디스크립터를 초기화한다.
- 파티션에 손상된 블록이 있는지 검사한다(옵션). 손상된 블록이 있다면 손상된 블록 목록을 만든다.
- 각 블록 그룹에 대해 슈퍼블록, 그룹 디스크립터, 아이노드 테이블, 비트맵 두 개를 저장하는 데 필요한 디스크 블록을 예약한다.
- 각 블록 그룹의 아이노드 비트맵과 데이터 블록 비트맵을 0으로 초기화한다.
- 각 블록 그룹의 아이노드 테이블을 초기화한다.
- 루트 디렉토리 /를 생성한다.
- lost+found 디렉토리를 생성한다. e2fsck는 없어지거나 손상된 블록을 연결하기 위해 이 디렉토리를 사용한다.
- 앞에서 만든 두 디렉토리가 속한 블록 그룹의 아이노드 비트맵과 데이터 블록 비트맵을 갱신한다.
- 손상된 블록이 있으면 lost+found 디렉토리로 옮긴다.
(2) VFS의 EXT2파일 생성
․대부분의 VFS 메소드에는 대응하는 Ext2 메소드가 있다.
․대부분의 VFS 슈퍼블록 연산은 Ext2에서 독자적으로 구현한다. 슈퍼블록 메소드의 주소는 포인터의 배열인 ext2_sops에 저장된다.
․대부분의 VFS 슈퍼블록 연산은 Ext2에서 독자적으로 구현한다. 슈퍼블록 메소드의 주소는 포인터의 배열인 ext2_sops에 저장된다.
*아이노드가 정규 파일을 나타내는 경우
- 아이노드가 정규 파일을 나타내는 경우에는 truncate 연산만 ext2_truncate() 함수로 구현한다.
- ext2_file_inode_operations 테이블에 있는 다른 모든 아이노드 연산은 NULL 포인터를 가진다.
- 대응하는 Ext2 메소드가 정의되어 있지 않은 경우(NULL 포인터)의 VFS는 자신의 범용 함수를 사용한다.
*아이노드가 디렉토리를 나타내는 경우
- 아이노드가 디렉토리를 나타내는 경우, ext2_dir_inode_operations 테이블에 있는 대부분의 아이노드 연산은 독자적인 Ext2 함수로 구현한다.
*아이노드가 자체에 저장할 수 있는 짧은 심볼릭 링크를 나타내는 경우
- 아이노드가 자체에 저장할 수 있는 짧은 심볼릭 링크를 나타내는 경우, readlink와 follow_link 메소드를 제외한 모든 아이노드 메소드는 NULL이고, 두 메소드는 각각 ext2_readlink()와 ext2_follow_link() 함수가 구현한다.
- 이 메소드들의 주소는 ext2_fast_symlink_inode_operations 테이블에 저장된다. 아이노드가 데이터 블록에 저장되는 긴 심볼릭 링크를 나타내는 경우, readlink와 follow_link 메소드는 범용 page_readlink()와 page_follow_link() 함수로 구현하며, 이들의 주소는 page_symlink_inode_operations 테이블에 저장된다.
*아이노드가 문자 장치 파일, 블록 장치 파일, 명명된 파이프를 나나태는 경우
- 아이노드가 문자 장치 파일, 블록 장치 파일, 명명된 파이프를 나타내는 경우, 아이노드 연산은 파일시스템에 의존하지 않는다.
- 이들은 각각 chrdev_inode_operations, blkdev_inode_operations, fifo_inode_operations 테이블에 저장된다.
․VFS 파일연산은 Ext2에서 독자적으로 구현한다. 이들 메소드의 주소는 ext2_file_operations 테이블에 저장된다. VFS 메소드 중에는 여러 파일시스템에 공통적인 범용 함수로 구현하는 것도 있다.
3. 입출력 장치 관리
․CPU와 입출력 장치의 연결을 위해 버스를 사용할 때 이 버스를 입출력 버스(I/O bus)라고 부릅니다. 입출력 버스는 입출력 포트, 인터페이스, 장치 컨트롤러의 하드웨어 구성 요소 계층에 의해 각 입출력 장치에 연결됩니다. 이 단원에서는 입출력 장치 관리 대해 자세히 살펴보겠습니다.
1) 입출력 아키텍처
(1) 입출력 아키텍처의 구성 요소
․CPU와 입출력 장치의 연결을 위해 버스를 사용할 때 이 버스를 입출력 버스(I/O bus)라고 부른다.
․이 경우에 인텔 80x86 마이크로프로세서는 입출력 장치 주소를 나타내기 위해 주소 라인 32개 중에서 16개를 사용하고, 데이터를 전송하기 위해 데이터 라인 64개 중 8, 16, 또는 32개를 사용한다.
․입출력 버스는 입출력 포트, 인터페이스, 장치 컨트롤러의 하드웨어 구성 요소 계층에 의해 각 입출력 장치에 연결된다.
․다음은 입출력 아키텍처의 구성 요소이다.

(2) 입출력 포트
․장치를 입출력 버스에 연결하면 각 장치는 자신의 입출력 주소 집합을 소유하게 된다. 이를 입출력 포트라고 한다.
․IBM PC 구조에서는 입출력 주소 공간에 8비트 입출력 포트가 65536개까지 들어간다.
- 연속하는 8비트 포트 두 개가 16비트 포트 하나를 구성하고, 16비트 포트는 짝수 주소에서 시작한다.
- 연속하는 16비트 포트 두 개가 32비트 포트 하나를 구성하고, 4의 배수 주소에서 시작한다.
․CPU는 입출력 명령어들 중 하나를 실행하는 과정에서 주소 버스를 사용하여 요청한 입출력 포트를 선택하고, 데이터 버스를 사용하여 CPU 레지스터와 포트 사이에 데이터를 전송한다.
․입출력 포트를 물리 주소 공간의 주소로 매핑할 수도 있다.
․최근의 하드웨어 장치는 메모리에 매핑된 입출력이 빠르고, DMA를 사용할 수 있어서 더 선호하는 추세이다.
․몇 비트는 장치 상태를 나타내고 나머지 비트는 장치에 보낼 명령을 지정하는 식으로, 비용 절감을 위해 한 입출력 포트를 여러 목적으로 사용하기도 한다.
․같은 입출력 포트를 입력 레지스터나 출력 레지스터로 사용할 수도 있다.
(3) 입출력 인터페이스
․입출력 인터페이스는 입출력 포트 그룹과 이들에 대응하는 장치 컨트롤러(device controller) 사이에 위치하는 하드웨어 회로다.
․인터페이스는 입출력 포트에 넣어준 값을 장치에 대한 명령과 데이터로 변환하는 해석기 역할을 수행하며, 반대 방향으로 장치의 상태 변화를 감지하여 상태 레지스터 역할을 하는 입출력 포트 값을 변경한다.
․인터페이스 회로는 IRQ 라인을 통해 프로그램 가능한 인터럽트 컨트롤러 (PIC : Programmable Interrupt Controller)에 연결되어 장치를 대신해서 인터럽트 요청을 발생시킨다.
․인터페이스에는 전용과 범용 입출력 인터페이스의 두 가지 유형이 있다.
| 전용 입출력 인터페이스 | -전용 입출력 인터페이스는 한 종류의 특정한 하드웨어 장치를 위한 것이다. -어떤 경우 입출력 인터페이스를 포함하는 카드 자체에 장치 컨트롤러가 위치하기도 한다. -전용 입출력 인터페이스에 연결된 장치는 내부 장치(PC 케이스 내부에 있는 장치)일 수도 있고, 외부 장치(PC 케이스 외부에 있는 장치)일 수도 있다. -여기에는 키보드, 그래픽, 디스크, 버스 마우스, 네트워크 인터페이스 등이 속한다 |
| 범용 입출력 인터페이스 | -범용 입출력 인터페이스는 여러 가지 다양한 하드웨어 장치를 연결할 때 사용한다. -범용 입출력 인터페이스에 연결된 장치는 언제나 외부 장치이다. -여기에는 병렬․직렬 포트, 범용 직렬 버스(USB), PCMCIA․SCSI 인터페이스 등이 속한다. |
(3) 직접 메모리 접근 컨트롤러(DMAC : Direct Memory Access Controller)
․모든 PC에는 직접 메모리 접근 컨트롤러(DMAC : Direct Memory Access Controller)라는 보조 프로세서가 있다.
․CPU는 RAM과 입출력 장치 사이에서 데이터를 전송하도록 이 프로세서에 명령을 내릴 수 있다.
․DMAC는 데이터 전송이 끝나면 인터럽트 요청을 발생시킨다.
․CPU와 DMAC가 동시에 같은 메모리 위치에 접근하려 할 때 발생하는 충돌은 메모리 중재자(memory artiter)라는 하드웨어 회로가 해결한다.
․많은 양의 자료를 한 번에 전송하는 디스크 드라이버 같은 느린 장치가 DMAC를 주로 사용한다.
․DMAC의 초기 설정 시간이 상대적으로 길기 때문에 전송할 자료의 양이 적은 경우는 CPU를 직접 사용하여 데이터를 전송하는 것이 더 효과적이다.
(4) 버스 주소
․버스 주소는 CPU를 제외한 모든 하드웨어 장치가 데이터 버스를 구동하기 위해 사용하는 메모리 주소이다.
․DMA 연산에서 데이터 전송은 CPU의 간섭 없이 이루어지며, 입출력 장치와 DMAC가 데이터 버스를 직접 구동한다.
․따라서 커널이 DMA 연산을 설정할 때 커널은 사용할 메모리 버퍼의 버스 주소를 DMAC 또는 입출력 장치의 적절한 입출력 포트에 기록해야 한다.
2) 장치 파일
․기반이 되는 장치 드라이버의 특성에 따라 장치 파일을 블록(block)과 문자(character)라는 두 유형으로 분류합니다.
(1) 블록장치와 문자장치
․기반이 되는 장치 드라이버의 특성에 따라 장치 파일을 블록(block)과 문자(character)라는 두 유형으로 분류한다.
| 블록 장치 | 문자 장치 |
| - 데이터는 임의로 참조할 수 있다. - 데이터 블록을 전송하는 데 걸리는 시간이 짧으며 항상 거의 같다. - 예) 하드 디스크, 플로피 디스크, CD-ROM, DVD 플레이어 등 |
- 데이터는 임의로 참조할 수 없거나(예, 사운드 카드), 임의로 참조할 수는 있지만 임의 위치의 데이터에 접근하는 시간이 장치 안에서의 위치에 크게 의존한다. - 예) 자기 테이프 드라이버 등 |
․네트워크 카드는 이 유형 분류에서 대표적인 예외이며, 파일에 직접 대응하지 않는 하드웨어 장치이다.
(2) 리눅스에서의 파일
․리눅스 2.4에는 시스템의 디렉토리 트리에 실제 파일이 저장되는 구식(old-style) 장치 파일과 /proc 파일시스템처럼 가상 파일인 devfs 장치 파일이라는 두 종류의 장치 파일이 있다.
(3) 구식 장치 파일
․구식 장치 파일은 유닉스 운영체제 초기 버전부터 사용되어 왔다. 구식 장치 파일은 파일시스템에 저장된 실제 파일이다.
그러나 파일의 아이노드는 디스크의 데이터 블록을 참조하지 않는다. 대신 아이노드는 하드웨어 장치를 나타내는 식별자를 가지고 있다.
- 장치 이름과 유형 외에 각 장치 파일은 주 번호(Major number)와 부 번호(Minor number)라는 중요한 속성을 가지고 있다.
- 주 번호는 장치 유형을 나타내는 1~254의 숫자다.
- 일반적으로 동일한 주 번호와 유형을 가진 모든 장치 파일은 같은 장치 드라이버 에 의해 처리되며, 동일한 파일 연산 집합을 공유한다. 부 번호는 같은 주 번호를 공유하는 여러 장치 중에서 특정 장치를 나타내는 숫자다.
․구식 장치 파일을 생성하기 위해 mknod() 시스템 콜을 사용한다.
- 이 시스템 콜의 매개 변수는 장치 파일의 이름과 유형 그리고 주․부 번호이다.
- 주․부 번호라는 두 매개 변수를 16비트 dev_t 숫자로 변환한다.
- 여기서 상위 8비트는 주 번호, 하위 8비트는 부 번호를 나타낸다.
- MAJOR, MINOR 매크로를 사용하여 16비트 숫자에서 두 값을 추출할 수 있으며, MKDEV 매크로를 사용하여 주 번호와 부 번호를 합쳐서 16비트 숫자로 만든다.
- 실제로 dev_t는 애플리케이션 프로그램에서 주로 사용하는 데이터 타입이고, 커널은 kdev_t 데이터 타입을 사용한다.
- 주 번호와 부 번호는 아이노드 객체의 i_rdev 필드에 저장한다.
- 장치 파일의 유형은 i_mode 필드에 저장한다.
(4) 장치 파일의 저장
․일반적으로 장치 파일은 /dev 디렉토리에 저장하며, 하드웨어 장치(/dev/hda 같은 하드 디스크) 또는 하드웨어 장치의 물리적이거나 논리적인 일부(/dev/hda2 같은 디스크 파티션)와 대응한다.
그러나 어떤 경우에 장치 파일은 실제 하드웨어 장치에 대응하지 않고 가상적인 논리적 장치를 나타낸다.
․장치 파일을 주 번호와 부 번호를 사용하여 표현하는 데는 /dev 디렉토리에 있는 장치의 대부분이 실제로 존재하지 않으며, 주 번호와 부 번호가 각각 8비트라는 문제점이 있다.
․devfs 장치 파일은 이런 문제들을 해결하기 위해 도입되었지만, 아직까지도 광범위하게 사용되고 있지는 않다.
(5) devfs 가상 파일시스템
․devfs 가상 파일시스템은 드라이버가 주 번호, 부 번호 대신 이름을 사용하여 장치를 등록하도록 한다. 커널은 특정 장치를 탐색하는 작업을 쉽게 하려고 기본 명명 규칙을 제공한다.
․devfs 파일시스템을 사용하는 입출력 드라이버는 devfs_register()를 호출하여 장치를 등록한다.
- 이 함수는 장치 파일 이름, 장치 드라이버 메소드 테이블을 가리키는 포인터를 포함하는 새로운 devfs_entry 구조체를 생성한다.
- 등록된 장치 파일은 자동으로 devfs 가상 디렉토리에 나타난다.
- 이 디렉토리에 있는 장치 파일의 아이노드 객체는 파일에 접근할 때만 생성된다.
․devfs 파일의 디엔트리 객체가 파일 연산을 가리키는 포인터를 가지고 있기 때문에 장치 파일을 여는 것이 좀더 효율적이다.
․devfs에도 몇 가지 문제가 있다. 가장 중요한 점은 주 번호, 부 번호는 유닉스 시스템에서 어느 정도 불가피하다는 사실이다.
첫째 : NFS 서버나 find 명령과 같은 사용자 모드 애플리케이션은 주어진 파일을 포함하는 물리적 디스크 파티션을 나타내기 위해 주 변호, 부 번호에 의존한다.
둘째 : 장치 번호는 POSIX 표준에서도 요구하고 있다. 따라서 devfs 계층은 커널이 구식 장치 파일처럼 각 장치 드라이버에 대해 주 번호와 부 번호를 정의하도록 하고 있다.
․현재 거의 모든 장치 드라이버는 대응하는 구식 장치 파일과 같은 주 번호, 부 번호를 devfs 장치 파일에 연관하고 있다.
STEP:장치 파일은 시스템 디렉토리 안에 있지만 정규 파일이나 디렉토리와 근본적으로 다르다. 그 근거는 무엇인가?
▶장치 파일은 시스템 디렉토리 안에 있지만 정규 파일이나 디렉토리와 근본적으로 다르다.
프로세스가 정규 파일에 접근하는 경우 파일시스템을 통해 디스크 파티션 내의 데이터 블록에 접근한다. 그러나 프로세스가 장치 파일에 접근하는 경우에는 파일의 내용을 읽거나 쓰지 않고 단지 하드웨어 장치를 구동할 뿐이다.
애플리케이션이 장치 파일과 정규 파일을 구별하지 못하도록 하는 것은 VFS의 역할이다. 이를 처리하기 위해 VFS는 장치 파일이 열릴 때 장치 파일의 기본 파일 연산을 변경한다. 그 결과 해당 장치 파일에 대한 시스템 콜은 장치 파일이 들어 있는 파일시스템이 제공하는 함수가 아닌 장치와 관련한 함수의 호출로 바뀐다.
장치와 관련한 함수는 하드웨어 장치에 작용하여 프로세스가 아닌 요청한 연산을 실행한다.
3) 장치 드라이버
(1) 장치 드라이버의 개념
․장치 드라이버는 잘 정의된 프로그래밍 인터페이스를 통해 하드웨어 장치에 묻고 답하게 해주는 소프트웨어 계층이다.
․정형화된 VFS 함수들(open, read, lseek, iocto 등)은 장치 제어에도 사용된다.
․장치 드라이버가 이 함수들을 실제로 구현한다. 각 장치는 독자적인 입출력 컨트롤러(I/O controller), 명령, 상태 정보를 가지고 있기 때문에 대부분의 입출력 장치에는 독자적인 드라이버가 있다.
․장치 드라이버는 장치 파일 연산을 구현하는 함수만으로 구성되지 않는다.
․장치 드라이버를 사용하기 전에 장치 드라이버의 등록과 초기화라는 두 가지 일을 수행해야 한다. 또한 장치 드라이버가 데이터를 전송할 때 입출력 연산을 감시(monitor)해야 한다.
(2) 리눅스에서의 장치 드라이버
․리눅스 커널은 존재하는 모든 입출력 장치를 완벽하게 지원하지는 않고, 하드웨어 장치에 대한 지원에 다음과 같은 세 가지의 종류가 있다.
*지원하지 않음 : 애플리케이션 프로그램이 적절한 in, out 어셈블리 명령어를 사용해서 장치의 입출력 포트와 직접 상호 작용한다.
*최소 지원
- 커널은 하드웨어 장치를 인식하지 않고, 단지 해당 입출력 인터페이스만 인식한다.
- 사용자 프로그램은 해당 인터페이스를 일련의 문자열을 읽고 쓸 수 있는 순차적 장치로 다룰 수 있다.
*확장 지원 : 커널은 하드웨어 장치를 인식하고, 입출력 인터페이스를 직접 처리한다. 사실 장치에 대한 장치 파일조차 없는 경우도 있다.
(3) 많은 양의 데이터를 처리하는 장치
․커널은 각 입출력 연산에서 많은 양의 데이터를 쏟아내는 장치들도 처리할 수 있어야 한다.
․이런 장치에는 사운드 카드, 네트워크 카드 같은 순차적 장치나 모든 종류(플로피, CDROM, SCSI 디스크)의 디스크 같은 임의 접근 장치들이 포함된다.
․이 문제를 해결하기 위해 다음의 두 가지 기법을 결합하여 사용한다.
- 데이터 블록 전송을 위해 DMA 프로세서를 사용한다.
- 각 요소가 데이터 블록 크기인 요소 두 개 이상을 가지는 원형 버퍼를 사용한다.
※ 많은 양의 데이터를 처리하는 장치
1. 원형 버퍼
원형 버퍼는 CPU 부하의 최고 값(peak)을 낮추는 역할을 한다. 데이터를 받아들이는 사용자 모드 애플리케이션이 우선 순위가 높은 다른 작업 때문에 느려지더라도 인터럽트 처리기는 현재 실행 프로세스 중에 실행되므로 DMAC는 원형 버퍼의 요소를 계속 채울 수 있다.
2. 장치 드라이버의 등록
장치 드라이버를 등록한다는 것은 장치 드라이버를 대응하는 장치 파일과 연결한다는 것을 의미한다. 드라이버가 아직 등록되지 않은 장치 파일에 접근하면 에러 코드 -ENODEW를 반환한다. 장치 드라이버가 정적으로 컴파일되어 커널에 포함되어 있다면 커널 초기화 과정에서 드라이버의 등록이 이루어진다. 장치 드라이버가 커널 모듈로 컴파일되어 있다면 모듈을 로드할 때 등록이 이루어지고, 언로드될 때 등록이 취소될 수 있다.
3. 구식 장치 파일 사용
구식 장치 파일을 사용하는 문자 장치 드라이버를 나타내는 자료 구조는 device_struct의 배열인 chrdevs이다. 각 배열 첨자는 장치 파일의 주 번호다. 주 번호의 범위는 1˜254이므로 배열은 요소를 255개 포함한다. 그렇지만 배열의 첫 번째 요소는 사용되지 않는다. 각 device_struct 구조체는 name, fops라는 두 필드를 포함한다. name은 장치 클래스의 이름을 가리키고, fops는 file_operations 구조체를 가리킨다.
4. 블록 장치 드라이버
이와 유사하게 블록 장치 드라이버는 자료 구조 255개의 배열인 blkdevs로 나타낸다. 각 구조체는 name, bdops의 두 필드를 포함한다. name은 장치 클래스의 이름을 나타내고, bdops는 block_device_operations 구조체를 가리킨다.
5. 사용자 모드 애플리케이션
사용자 모드 애플리케이션이 장치 파일을 통해 사용할 수 있도록 장치 드라이버의 등록은 최대한 빨리 이루어지는 반면 초기화는 최대한 늦게 이루어진다. 사실 드라이버를 초기화하면 시스템의 자원을 할당하므로 다른 드라이버가 사용할 수 없게 된다.
(4) 장치드라이버의 효율적 사용을 위한 기법
․장치 드라이버는 필요할 때 자원을 얻을 수 있게 하면서도 이미 할당된 자원을 여러 번 요청하는 것을 막으려고 다음과 같은 기법을 사용한다.
-사용 카운터가 현재 장치 파일에 접근하고 있는 프로세스의 수를 관리한다.
-open 메소드는 사용 카운터값을 검사한 다음 증가시킨다.
-release 메소드는 감소시킨 다음 사용 카운터의 값을 검사한다.
(5) 모니터링 기법
․어떤 경우든 입출력 연산을 시작한 장치 드라이버는 입출력 연산이 종료했는지 또는 타임아웃 되었는지 알려주는 모니터링 기법에 의존해야 한다.
․연산이 종료하면 장치 드라이버는 입출력 인터페이스의 상태 레지스터를 읽어서 입출력 연산을 제대로 실행했는지 결정한다.
․타임아웃의 경우 해당 연산에 주어진 시간이 지났고 아무런 일도 발생하지 않았으므로 뭔가 잘못되었다는 사실을 드라이버가 알게 된다.
․입출력 연산의 종료를 모니터링하는 기법으로 폴링 모드(polling mode)와 인터럽트 모드(interrupt mode)가 있다
| 폴링 모드(polling mode) | 입출력 연산을 마쳤다는 의미로 상태 레지스터의 값이 변경될 때까지 CPU가 장치의 상태 레지스터를 계속 반복하여 검사한다. |
| 인터럽트 모드(interrupt mode) | 입출력 컨트롤러가 IRQ 라인을 통해 입출력 연산이 끝났음을 신호로 알려줄 수 있을 때만 사용할 수 있다. |
(6) 블록 장치 드라이버
․블록 장치 드라이버는 주 번호 하나와 부 번호 하나로 지정한 하드웨어 장치에 대한 입출력을 처리하는 커널 계층을 의미한다.
․어떤 블록 장치 드라이버가 현재 사용 중인지 추적하기 위해 커널은 주 번호와 부 번호 조합을 통해 참조하는 해시 테이블을 사용한다.
․커널은 블록 장치 드라이버를 사용할 때마다 주 번호와 부 번호 조합으로 나타내는 블록 장치 드라이버가 이미 해시 테이블에 저장되어 있는지 검사한다.
․테이블에 있다면 블록 장치 드라이버는 이미 사용 중이다.
블록 장치 파일의 주 번호와 부 번호에 대해 해시 함수를 사용하므로 주어진 블록 장치 파일을 통해 접근할 때 블록 장치 드라이버가 활성화됐는지 아니면 주 번호와 부 번호가 같은 다른 블록 장치 파일을 통해 접근했는지 여부는 상관없다.
주 번호와 부 번호 조합에 대응하는 블록 장치 드라이버를 찾을 수 없다면 커널은 새로운 요소를 해시 테이블에 추가한다.
(7) bdev_hashtable 배열
․해시 테이블 배열은 bdev_hashtable 배열에 저장된다.
․배열은 블록 장치 디스크립터의 리스트 64개를 포함하며, 각 디스크립터는 block_device 자료 구조이다.
․블록 장치 디스크립터의 bd_inodes 필드는 아이노드의 이중 연결 원형 리스트의 헤드(첫 번째 더미 요소)를 저장한다.
․아이노드는 이 블록 장치 드라이버를 사용해서 열린 블록 장치 파일을 나타낸다. 아이노드 객체의 i_devices 필드가 이 리스트의 앞, 뒤 요소를 가리킨다.
(8) bd_inode 필드
․각 블록 장치 디스크립터는 bd_inode 필드에 드라이버의 특수 블록 장치 아이노드 객체의 주소를 저장한다.
․이 아이노드는 디스크 파일에 대응하지 않고, bdev 특수 파일시스템에 속한다.
․블록 장치 아이노드는 같은 블록 장치를 가리키는 블록 장치 파일의 아이노드 객체가 공유하는 정보의 원본을 가지고 있다.
(9) 블록 장치에 대한 테이터 전송 연산
․블록 장치에 대한 테이터 전송 연산은 섹터(sector)라는 연속하는 바이트 그룹을 단위로 수행한다.
․대개 디스크 장치의 섹터 크기는 512바이트이다. 1024byte나 2048byte를 사용하는 장치도 있다.
․디스크 장치가 여러 인접 섹터를 한 번에 전송할 수 있지만 한 섹터보다 작은 크기는 전송할 수 없다.
․커널은 각 하드웨어 블록 장치의 섹터 크기를 hardsect_size라는 테이블에 저장한다.
․테이블의 각 요소는 대응하는 블록 장치 파일의 주, 부 번호를 통해 참조한다.
(10) 블록 장치 드라이버
․블록 장치 드라이버는 블록 (block)이라는 많은 연속 바이트를 한 번에 전송한다.
․섹터는 하드웨어 장치에 대한 데이터 전송의 기본 단위이지만, 블록은 장치 드라이버가 요청하는 단일 입출력 연산과 관련한 연속 바이트 그룹이다.
․리눅스에서 블록 크기는 반드시 2의 제곱 수여야 하고, 최대 크기는 페이지 프레임의 크기이다. 그리고 블록에는 섹터가 정수 개 있기 때문에 반드시 섹터 크기의 배수여야 한다. 따라서 PC 아키텍처에서 허용되는 블록 크기는 512, 1024, 2048, 4096 바이트이다.
․블록 장치 드라이버 하나가 같은 주 번호를 공유하는 여러 장치 파일을 처리해야 하고 각 블록 장치 파일이 자신의 블록 크기를 가질 수 있기 때문에, 블록 장치 드라이버는 여러 블록 크기에 동작할 수 있어야 한다.
(11) blksize_size 테이블
․커널은 blksize_size라는 테이블에 블록 크기를 저장한다.
․테이블의 각 요소는 대응하는 블록 장치 파일의 주, 부 번호로 참조한다.
․각 블록은 자신의 버퍼, 즉 커널이 블록의 내용을 저장하기 위해 사용하는 RAM 메모리 영역을 요청한다.
․장치 드라이버가 디스크에서 블록을 읽을 때 하드웨어 장치에서 얻은 값을 사용하여 해당 버퍼를 채운다.
․비슷하게 장치 드라이버가 디스크에 블록을 기록할 때 버퍼의 실제 값을 사용하여 하드웨어 장치의 연속 바이트를 갱신한다.
․버퍼 크기는 언제나 대응하는 블록 크기와 일치한다.
(12) buffer_head 타입 디스크립터
․버퍼 헤드는 각 버퍼와 관련한 buffer_head 타입 디스크립터이다.
․여기에는 커널이 버퍼를 다루는 데 필요한 모든 정보가 들어 있다. 따라서 커널은 각 버퍼를 처리하기 전에 버퍼 헤드를 검사한다.
※ 버퍼헤드의 필드
각 버퍼 헤드의 b_data 필드에는 해당 버퍼의 시작 주소를 저장한다.
페이지 프레임 하나가 여러 버퍼를 저장할 수 있으므로, b_this_page 필드가 페이지 내 다음 버퍼의 버퍼 헤드를 가리킨다. 이 필드는 전체 페이지 프레임을 저장하고 검색하는 데 사용된다. b_blocknr 필드는 논리적 블록 번호, 즉 디스크 파티션 내 블록 인덱스를 저장한다. b_state 필드는 버퍼 상태를 나타내는 플래그를 저장한다.
b_dev 필드가 버퍼에 저장된 블록을 포함하는 가상(virtual) 장치를 나타내는 반면, b_rdev 필드는 실제(real) 장치를 나타낸다. 간단한 일반 하드디스크의 경우 이 구분이 의미가 없지만, 동시에 동작하는 디스크 여러 개로 이루어진 RAID(Redundant Array of Independent Disks) 스토리지를 나타내기 위해 도입됐다.
안전성과 효율성을 높이기 위해 RAID 배열에 저장한 파일은 여러 디스크에 나누어 저장하지만, 애플리케이션은 논리 디스크 하나로 간주한다. 따라서 b_blocknr 필드는 논리적인 블록 번호를 나타내고, b_rdev 필드는 특정 디스크 유닛을 나타내며, b_rsector 필드는 섹터 번호를 나타낸다.
(13) 문자 장치의 장치 드라이버
․문자 장치는 복잡한 버퍼링 전략이 필요 없고, 디스크 캐시도 사용하지 않으므로 비교적 다루기 쉽다.
․문자 장치마다 요구 사항이 다르다. 하드웨어 장치를 구동하기 위해 복잡한 통신 프로토콜을 구현해야 하는 경우도 있고, 간단히 하드웨어 장치의 입출력 포트에서 값 몇 개만 읽으면 되기도 한다.
․어떤 문자 장치 드라이버가 현재 사용 중인지 파악하기 위해 커널은 주 번호와 부 번호로 참조하는 해시 테이블을 사용한다.
1단계 : 해시 테이블 배열은 cdev_hashtable 변수에 저장된다.
2단계 : 여기에는 문자 장치 디스크립터 64개의 리스트가 저장되며, 각 디스크립터는 char_device 자료 구조이다.
․블록 장치 드라이버와 마찬가지로, 해시 테이블이 필요한 이유는 커널이 문자 장치 파일이 이미 열려 있는지 검사하는 것만으로는 문자 장치 드라이버가 이미 사용 중인지 판단할 수 없기 때문이다.
․사실 시스템 디렉토리 트리에는 경로명은 다르지만 주 번호와 부 번호가 같은 여러 문자 장치 파일이 있을 수 있다. 그리고 이 파일들은 사실 모두 같은 장치 드라이버를 가리키는 것이다.
․문자 장치 디스크립터를 가리키는 장치 파일을 처음으로 열 때 문자 장치 디스크립터가 해시 테이블에 삽입된다.
1단계 : init_special_inode() 함수가 이 작업을 수행한다.
이 함수는 어떤 디스크 아이 노드가 장치 파일을 나타낸다는 사실을 판단했을 때 저수준 파일시스템 계층 이 호출한다.
2단계 : init_special_inode()는 해시 테이블의 문자 장치 디스크립터를 탐색한다.
3단계 : 디스크립터를 찾을 수 없으면 새로운 디스크립터를 할당하고, 이를 해시 테이블에 삽입한다.
4단계 : 함수는 또한 디스크립터의 주소를 장치 파일의 아이노드 객체의 i_cdev 필드에 저장한다.





'정보과학 > 운영체제특론' 카테고리의 다른 글
| 공개 소프트웨어와 리눅스 산업 전망에 대해서 (1) | 2024.01.01 |
|---|---|
| 메모리 관리 커널 (0) | 2023.12.16 |
| 프로세서 관리 커널 2 (0) | 2023.12.16 |
| 프로세서 관리 커널 1 (0) | 2023.12.13 |
| 임베디드 시스템과 리눅스 (0) | 2023.12.13 |


