728x90
1. 관계 DBMS의 카탈로그
① 카탈로그의 의미
| ∘카탈로그(catalog)는 각 데이터베이스에 대한 정의를 저장한다. 즉 데이터베이스를 기술하는 데이터를 저장하는데, 이런 데이터를 종종 메타 데이터(meta-data)라고 함 ∘카탈로그라는 용어보다 좀더 일반적인 소프트웨어 유틸리티를 나타내기 위해서 흔히 데이터 사전(data dictionary)이라는 용어를 사용함 ∘카탈로그에 저장된 정보는 사용자나 데이터베이스관리자에게 제공되기도 하지만, 데이터 정의어나 데이터 조작어 컴파일러, 질의최적화기, 트랜잭션 처리기, 보고서 생성기, 제약조건 관리기 등과 같은 DBMS 자체의 다양한 소프트웨어 모듈들이 주로 시스템 카탈로그를 접근함 ∘데이터베이스 설계의 각 단계와 설계에 관한 결정 결과에 대한 정보를 저장함으로써 데이터베이스 설계 과정 자체를 문서화하기 위해서 데이터 사전을 사용함 ∘데이터베이스를 설계하는 동안 데이터 사전을 사용하는 것은 설계의 최종 단계에서 이미 메타 데이터가 데이터 사전에 존재한다는 것을 의미함 ∘관계 DBMS의 카탈로그에는 뷰에 대한 외부단계의 명세 및 저장 구조나 인덱스들에 대한 내부단계의 명세뿐만 아니라 릴레이션 이름, 애트리뷰트 이름, 애트리뷰트 도메인(데이터 타입), 기본키와 보조키 애트리뷰트, 외래키, 여러 유형의 제약조건들에 대한 정보가 저장됨 ∘보안 및 데이터베이스의 릴레이션과 뷰에 대한 사용자의 권한, 각 릴레이션의 생성자나 소유자에 관한 권한관리 정보도 포함됨 ∘관계 DBMS에서는 카탈로그 자체를 릴레이션들의 형태로 저장하고, 카탈로그에 대해 질의하고, 갱신하고, 유지하기 위해서 DBMS를 사용하는 것이 일반적임 ∘DBMS 루틴(사용자 포함)들은 DBMS의 질의어를 사용하여 카탈로그에 대한 접근이 허용되는 범위에서 카탈로그에 저장된 정보를 접근 할 수 있음 ∘대부분의 관계 DBMS 에서는 카탈로그 파일들을 DBMS 릴레이션들로 저장함 ∘DBMS 모듈들이 카탈로그를 매우 자주 접근하기 때문에 카탈로그 접근을 가능한 한 효율적으로 구현하는 것이 중요함 |
② DBMS 모듈들이 접근하는 카탈로그의 정보
| ∘데이터 정의어, 저장구조 정의어 컴파일러 - DBMS 모듈들은 데이터 정의어로 표현한 데이터베이스 스키마에 대한 명세를 처리하고 검사하며 그 명세를 카탈로그에 저장함. - 각 단계(개념, 외부, 내부)에 대한 스키마 구조와 제약조건 및 필요하다면 각 단계 사이의 사상 정보를 데이터 정의어와 저장구조 정의어 명세에서 추출해서 카탈로그에 저장함 ∘ 질의와 데이터 조작어 파서 및 검증기 - 질의, 데이터 조작어 검색문, 데이터베이스 갱신문을 파싱하고, 이 구문들에서 참조된 모든 스키마들의 이름이 유효한가를 결정하기 위해서 카탈로그를 검사함 ∘질의와 데이터 조작어 컴파일러 - 컴파일러들은 고수준의 질의와 데이터 조작어 명령들을 저수준의 파일 접근 명령들로 변환함 - 이 과정에서 카탈로그로부터 개념스키마와 내부스키마 파일 구조들 사이의 사상에 대한 정보를 접근함 ∘질의와 데이터 조작어 최적화 - 질의 최적화기는 질의나 데이터 조작어 명령을 수행하는 최적의 방법을 결정하기 위해서 접근 경로와 구현 정보를 위해 카탈로그를 접근함 ∘권한 관리와 보안 검사 - 데이터베이스 관리자는 카탈로그에서 권한관리와 보안 검사에 관한 부분을 갱신할 수 있는 특권 명령들을 가짐 - DBMS는 릴레이션에 대한 사용자의 모든 접근이 적절한 권한을 갖고 있는가를 검사하기 위해서 카탈로그를 접근함 ∘질의와 데이터조작어 명령들에 대한 외부 대 개념 사상 - 외부의 뷰나 스키마를 참조하는 질의나 데이터 조작어 명령들은 DBMS가 수행하기 전에 개념 스키마를 참조하도록 변환해야 한다. 카탈로그에서 뷰에 대한 명세를 접근하여 이런 변환을 수행함  [그림 1] 데이터 사전에 접근 정보 |
2. 질의 최적화 과정 및 질의문의 내부표현
① 질의 최적화 과정
| ∘어휘/구문 분석 및 변환 - SQL로 작성된 문장을 스캐너를 통해 언어 요소에 맞는지, 파서를 통해 구문에 맞는지를 검사한다. 그리고 이것은 관계대수로 변환되며, 내부 표현에 근거하여 변환이 이루어짐 ∘질의 최적화 - 관계 대수 형태의 내부표현(셀렉션, 조인, 프로젝션 등)을 통해 최적화를 구함 - 질의 최적화는 동등한 표현식으로 재배열하기 위한 경험적인 규칙과 소요되는 비용계산의 추정을 통해 실행계획을 생성함 ∘질의 코드 생성기 - 질의 실행계획을 수행하기 위한 수행코드 생성. ∘런 타임 실행기 - 직접 질의를 실행시켜 질의문의 처리결과를 생성.  [그림 2] 고수준의 질의를 처리하는 전형적인 과정 |
② SQL질의를 관계대수로 번역
| ∘관계 DBMS의 대부분 상업용 질의어인 SQL 질의는 관계대수식으로 번역된 후, 즉 질의 트리 자료구조로 표현되고 나서 최적화가 이루어짐 ∘전형적으로 SQL 질의는 질의블록(query block)들로 분해한 후, 이것을 대수 연산자들로 변역한 것이 최적화되는 기본 단위임 ∘하나의 질의 블록은 SELECT-FROM-WHERE 식이 포함되며, GROUP BY절 및 HAVING절이 그 블록에 일부분이라면 함께 포함됨 ∘중첩된 질의는 별개의 질의 블록으로 취급함 ∘EMPLOYEE 릴레이션에 대한 SQL 질의의 예 SELECT LNAME,FNAME FROM EMPLOYEE WHERE SALARY > (SELECT MAX(SALARY) FROM EMPLOYEE WHERE DNO = 5); - 2개의 질의 블록으로 분해됨 내부블록 : SELECT MAX(SALARY) FROM EMPLOYEE WHERE DNO = 5 외부블록 : SELECT LNAME, FNAME FROM EMPLOYEE WHERE SALARY > C /* C 는 내부블록 반환 결과를 나타냄 */ - 확장된 관계대수식으로 번역 내부블록 : FMAX SALARY (σDNO=5(EMPLOYEE)) 외부블록 : πLNAME, FNAME(σSALARY>C(EMPLOYEE)) ∘다음 단계 질의 최적화기는 각 블록에 대한 실행계획을 선택하는데, 위의 내부블록은 최대임금을 계산하기 위하여 한 번만 수행되며, 계산된 최대 급여는 상수 C로서 외부 블록이 사용함 |
※ 질의문 분해(query decomposition)
| ∘INGRES DBMS의 QUEL언어를 실행하는데 사용한 최적화 기법임 (QUEL: 투플 관계해석) ∘여러개 투프 변수가 관련된 질의문을 하나 또는 두 개의 투플 변수만 포함된 하나의 서브 질의문(sub-query)으로 분해하여 처리한다는 전략을 의미함 ∘다중변수 질의문(MVQ : multi-variable query)을 ➡ 일련의 단일변수 질의문(OVQ :one variable queries)으로 분해 과정 - 분리(Detachment): 하나의 소질의문을 식별해서 분리하고, 분리된 서브 질의문과 나머지는 하나의 공통 투플 변수로 연결 - 투플 대입(Tuple substitution): 질의문의 변수에 투플 값을 하나씩 대입, n-변수 질의문을 (n-1)-변수 질의문으로 축소 |
3. 질의 연산들을 수행하기 위한 기본 알고리즘
① 외부 정렬 알고리즘
| ∘외부 정렬은 대부분의 데이터베이스 파일처럼 디스크에 저장된 레코드들로 구성되며 주기억 장치에 한꺼번에 수용할 수 없는 대규모 파일들에 적합한 정렬 알고리즘. ∘정렬 처리는 ORDER BY 절에는 필수이며, 조인 과 기타 연산(예: 합집합, 교집합)에 사용되는 정렬-합병 알고리즘, 프로젝트 연산을 위한 중복제거(즉 SELECT 절 DISTINCT 명시한 경우) 알고리즘에 핵심 구성요소임 ∘정렬-합병 알고리즘은 주 파일을 런(run)이라고 하는 작은 부 파일(sub file)들로 나누고 이들을 정렬한 후 정렬한 런들을 합병하여 더 큰 규모의 정렬된 부 파일들을 생성하는 과정을 반복함 ∘주기억 장치에 버퍼 공간을 필요로 하며 그 버퍼 공간에서 런들의 실제 정렬과 합병이 수행됨 ∘정렬 단계 - 이용 가능한 버퍼 공간에 들어갈 수 있는 파일의 런들을 주기억 장치로 읽어온 뒤, 내부 정렬 알고리즘을 이용하여 정렬한 후 이들을 임시 정렬된 부 파일(또는 런)로서 디스크에 저장함 - 하나의 런의 크기와 최초 런들의 개수(nR)는 파일의 블록 수(b)와 이용 가능한 버퍼공간(nB)에 의해 결정됨 . 예) nB=5블록, b=1024블록인 경우, nR=(b/nB) , 최초 런의 개수는 205개 결정 - Read RUN; Sort; Write RUN ∘합병 단계 - 정렬된 런들이 한 번 이상의 패스(pass)를 거쳐 합병됨 - 합병차수 dM은 각 패스에서 합병될 수 있는 런들의 개수임 - 각 패스에서 합병할 각 런으로부터 하나의 블록을 보관하기 위해 하나의 버퍼 블록이 필요하며 합병 결과의 한 블록을 포함하기 위해 하나의 버퍼 블록이 필요함 - 패스의 수 =(log dM(nR)) - 앞의 예에서 dM=4, 즉 4원-합병이며, 최초 205개의 최초 정렬 런은 첫째 이후 52개 합병, 다시 13개 합병, 다시 4개로, 마지막 1개로 4번의 패스가 필요함 |
② 실렉트 연산을 위한 알고리즘
| ∘company 데이터베이스 연산의 예 - (op1): σSSN='123456789'(EMPLOYEE) - (op2): σDNUMBER>5(DEPARTMENT) - (op3): σDNO=5(EMPLOYEE) - (op4): σDNO=5 and SALARY>30000 and SEX='F"(EMPLOYEE) - (op5): σESSN='123456789' and PNO=10(WORK_ON) ∘단순 선택(simple selection)을 위한 탐색 방법: 파일 스캔(S1~S2), 인덱스 스캔(S3~S6) - S1. 선형 탐색(linear search): 파일에 모든 레코드 검색하고, 검색된 각 애트리뷰트 값이 선택조건을 만족하는가 검사함 - S2. 이진 탐색(binary search): 파일이 어떤 키 애트리뷰트에 따라 정렬되어 있고, 선택 조건에 그 키의 애트리뷰트에 대한 동등비교가 포함되었을 경우 -예 (op1) - S3. 기본 인덱스나 해시 키를 사용하여 단일 레코드를 검색 - S4. 기본 인덱스를 사용하여 여러 개의 레코드들을 검색: 비교 조건이 >,>=,<,<= 경우 - S5. 클러스터링 인덱스를 사용하여 여러 개의 레코드들을 검색: 키가 아닌 어떤 애트리뷰트가 클러스트링 인덱스를 갖지만 선택조건이 그 애트리뷰트에 대하여 동등비교를 포함할 경우 - 예 (op3)에서 DNO=5인 레코드를 검색하려고 헐때 - S6. 동등 비교에 대하여 보조(B+-트리) 인덱스를 사용: 인덱싱 필드가 유일한 값을 가질 경우, 키이면 하나의 레코드가 검색되고, 키가 아니면 여러 개의 레코드가 검색됨 ∘복합 선택(complex selection)을 위한 탐색 방법 - 논리곱 조건(conjunctive condition)인 경우 : 여러 단순 조건들이 AND로 연결된 것 - S7. 개별 인덱스를 사용하는 논리곱 선택(conjunctive selection) - S8. 복합 인덱스를 사용하는 논리곱 선택 - S9. 레코드 포인터들의 교집합에 의한 논리곱 선택 ∘논리합 조건인 경우 : 여러 단순 조건들이 OR로 연결된 것 - 각 조건을 만족하는 레코드들의 합집합 - (op4'): σDNO=5 or SALARY>30000 or SEX='F"(EMPLOYEE) - 방법 1. 단순 조건들 중 어느 하나라도 접근경로를 가지지 않으면 선형 탐색 방법을 사용할 수밖에 없음 - 방법 2. 각 조건을 만족하는 레코드 포인터들의 합집합을 구하여 레코드들을 읽음 |
※ 선택률(selectivity)
| ∘조건을 만족하는 투플수를 릴레이션의 전체 투플수로 나눈 값으로서 0과 1 사이의 값이 되며 선택률에 따라 인덱스를 선택함 |
③ 조인 및 프로젝트와 집합 연산을 위한 알고리즘
| ∎ 조인연산을 위한 알고리즘 ∘조인은 질의 처리에서 가장 시간이 많이 소요되는 연산 중의 하나임 ∘질의에 나오는 대부분의 조인 연산을 동등 조인과 자연 조인의 변형으로 두 종류에 대해서 주로 언급하며, 두 파일의 조인은 2원 조인, 세 파일 이상 조인은 다원 조인이라고 함 ∘company 데이터베이스 조인 연산의 예 - (op6): EMPLOYEE ⋈ DNO=DNUMBER DEPARTMENT - (op7): DEPARTMENT ⋈ MGRSSN=SSN EMPLOYEE ∘조인을 구현하는 방법 - J1. 중첩 루프 조인(nested loop join): R(외부 루프)의 각 레코드에 대해 S(내부 루프)의 모든 레코드를 검색하고, 두 레코드가 조인조건 t[A]=s[B]를 만족하는가를 테스트함 - J2. 단일 루프 조인(single loop join): R에 있는 각 레코드에 대해 인덱스를 사용하여 S의 레코드들 중에서 조인 조건을 만족하는 모든 레코드들을 검색함. 예를 들어 S의 B에 대해 인덱스(또는 해시키)가 존재하면 R에 있는 각 레코드 t를 한 번에 하나씩 검색한 뒤 접근구조를 사용하여 S의 레코드 중에서 s[B]=s[A] 조건을 만족하는 모든 레코드 s를 직접 검색함 - J3. 정렬-합병 조인(sort-merge): R과 S의 모든 레코드들을 조인 애트리뷰트를 기반으로 정렬한 후, R과 S의 파일 블록들의 쌍을 순서대로 읽어서 조인 조건을 테스트함 - J4. 해시조인(hash join) . 분할단계(partitioning phase): 더 적은 수의 레코드를 가진 파일(예를 들면 R)에 대하여 한번의 패스를 거치면서 그 R의 레코드들을 해시 파일 버켓들로 해시함 . 조사단계(probing phase): S의 각 레코드를 해시하여 동일한 해시주소를 갖는 각 버켓에 속하는 R과 S의 레코드들이 조인조건을 만족하면 결합함 ∎ 프로젝트와 집합 연산을 위한 알고리즘 ∘프로젝트 연산 ∏<attribute list> (R)은 <attribute list>가 R의 키를 포함할 경우에는 연산의 결과가 R과 같은 수의 투플들을 가짐 ∘<attribute list>가 R의 키를 포함하지 않을 경우에는 연산의 결과를 정렬한 후 연속적으로 나타나는 중복된 투플을 제거하면 됨 ∘합집합, 교집합, 차집합, 카티션 프로덕트는 구현에 많은 비용이 들 수 있으며, 특히 카티션 프로덕트 연산(R X S)은 아주 많은 비용이 듬 ∘동일한 애트리뷰트들에 대해 두 릴레이션들을 정렬 후 각 릴레이션을 한번 조사하는 것으로 결과를 산출 ∘카티션 프로덕트(R X S)은 구현 비용이 비싸므로 질의 최적화 동안 연산을 피하고 동등한 연산으로 대치것이 중요함 ∘합집합, 교집합, 차집합은 동일한 수의 애트리뷰트와 동일한 애트리뷰트 도메인들을 가지는 릴레이션에만 적용되며, 이 들 연산을 구현하기 위해서 통상적으로 정렬-합병 기법의 변형된 방법을 사용함 ∘해싱을 사용하여 합집합, 교집합, 차집합을 구현할 수도 있음 |
④ 집계 연산과 외부 조인의 구현
| ∎ 집계(aggregation) 연산의 구현 ∘집계 연산자에는 MIN, MAX, COUNT, AVERAGE, SUM 등이 있으며, 한 테이블 전체에 적용할 경우에는 테이블 스캔을 하거나 적절한 인덱스를 사용하여 계산할 수 있음 - 예) SELECT MAX(SALARY) FROM EMPLOYEE; ∘SALARY에 대하여 인덱스가 있는 경우: 그 인덱스를 이용하여 집계 연산의 결과를 구할 수 있음 ∘SALARY에 대해 인덱스가 없는 경우: 파일 스캔을 해야 함 ∘인덱스는 밀집 인덱스, 즉 주 파일의 각 레코드에 대하여 하나의 엔트리를 가지는 경우에 한하여 COUNT, AVERAGE, SUM 연산자에 대해서도 사용될 수 있다. 이런 경우에는 인덱스 내의 값들에 해당 연산을 적용하면 됨 ∘비밀집 인덱스의 경우에는 정확한 계산을 위해 각 인덱스 엔트리와 연관된 레코드들의 실제 개수가 사용되어야 함. ∘인덱스로부터 유일한 값들의 개수를 계산할 수 있는 COUNT DISTINCT의 경우는 예외임 ∘GROUP BY 절이 질의에 사용되면, 집계 연산자는 투플들의 각 그룹별로 적용되어야 함 - 예) SELECT DNO, AVG(SALARY) FROM EMPLOYEE GROUP BY DNO; ∘해싱을 이용하여 투플들을 각 그룹으로 분할하여 그룹들을 생성한 후, 각 그룹에서 집계함 ∎외부 조인(outer join)의 구현 ∘외부 조인 연산에는 왼쪽 외부 조인, 오른쪽 외부 조인, 전체 외부 조인 의 세 가지 형태가 있는데, 다음은 왼쪽 외부 조인 연산의 예를 SQL로 표현한 것임 SELECT LNAME, FNAME, DNAME FROM (EMPLOYEE LEFT OUTER JOIN DEPARTMENT ON DNO=DNUMBER); ∘조인 알고리즘을 수정하여 구현하는 방법은 조인에 참여하지 않는 투플은 상대방 투플을 널로 채워서 조인함 ∘별개 알고리즘 고안하는 방법으로는 외부 조인을 위하여 조인 알고리즘의 수정이 아닌 별개의 알고리즘을 개발할 수도 있으나 이의 효율성은 낮음 |
※ 파이프라이닝을 사용한 연산의 결합
| ∘파이프라이닝 또는 스트림 기반 처리(stream-based processing) - 이 기법은 질의 처리 도중에 생성되는 임시 결과 파일의 수를 줄이는 것이 목적임 - 하나의 연산의 결과를 임시 파일에 저장하는 대신에 다음 연산의 입력으로 사용하는 것이 파이프라이닝의 기본 아이디어임 - 예) 기본 릴레이션들에 대하여 두 개의 실렉트 연산 다음에 조인 연산이 오면 각 실렉트 연산의 결과물인 투플들은 생성되는 대로 스트림 또는 파이프라인 상에서 조인 알고리즘의 입력으로 제공됨 |
4. 경험을 사용한 질의 최적화
① 질의 트리와 질의 그래프의 표시법(1)
| ∘성능 향상을 위한 경험적 규칙들 중에 하나의 예는 조인이나 기타 연산을 수행하기 전에 실렉트나 프로젝트 연산을 수행하는 것임 ∘경험적 규칙들은 질의에 대하여 초기 파서는 내부 표현을 생성하며, 그것은 질의 트리 또는 질의 그래프로 표현함 - 질의 트리 : 관계대수 혹은 확장된 관계대수식을 표현하는데 사용 - 질의그래프: 관계해석식을 표현하는데 사용 ∎질의 트리 ∘질의 트리란 관계대수식의 내부 표현으로 트리의 자료 구조로 나타낸 것임 - 리프노드 : 질의의 입력 릴레이션들 - 내부노드 : 관계대수 연산들 ∘질의 트리의 실행 - 트리는 질의에 포함된 연산들의 처리 순서를 나타냄 - 내부노드의 연산에 대해 피연산자가 사용 가능할 때마다 그 연산을 실행하고, 그 연산의 결과로 생성된 릴레이션으로 그 내부노드를 대치함 - 루트노드가 실행되어 질의에 대한 최종 결과 릴레이션이 생성되면 실행이 끝남 ∎질의 그래프 ∘질의를 보다 중립적으로 표현한 것이 질의 그래프 표기법이며, 관계 해석식을 표현하는 자료구조에 대응함 ∘질의 그래프의 구조 - 릴레이션 노드(node) : 질의의 입력 릴레이션들 (한겹 원으로 표시) - 상수 노드(node) : 질의의 상수값들 (이중 원으로 표시) - 그래프 에지(edge) : 실렉션과 조인 조건들 - 각 릴레이션으로부터 검색할 애트리뷰트들 (꺽쇠 기호안에 표시) ∘질의 그래프의 실행 - 질의를 실행하기 위한 연산들의 특정 순서를 나타내지 않음 - 각 질의에 대응되는 질의그래프는 유일함 |
② 질의 트리와 질의 그래프의 표시법(2)
| ∘관계 대수 식 표현 ∏ PNUMBER, DNUM,LNAME,ADDRESS,BDATE(((σ PLOCATION=‘Stafford’(PROJECT)) ⋈DNUM=DNUMBER(DEPARTMENT)) ⋈MGRSSN = SSN(EMPLOYEE)) ∘위의 것을 SQL 질의 표현으로 하면, SELECT PNUMBER, DNUM, LNAME, ADDRESS, BDATE FROM PROJECT, DEPARTMENT, EMPLOYEE WHERE DNUM=DNUMBER AND MGRSSN=SSN AND PLOCATION=‘Stafford’ 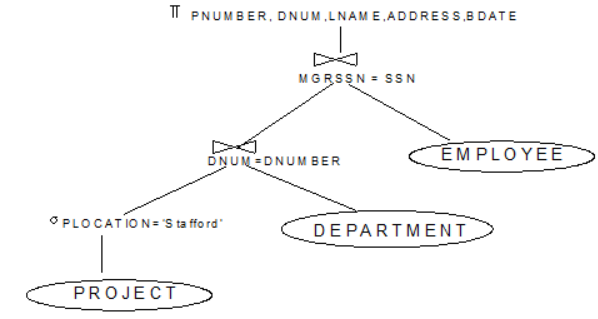 [그림 3] 위의 관계대수식에 대응되는 질의 트리  [그림 4] 위의 SQL 질의에 대한 초기 (규준) 질의 트리 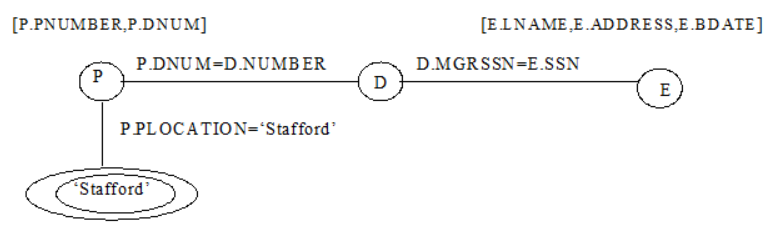 [그림 5] 위의 질의에 대한 질의 그래프 |
③ 질의트리의 경험적 최적화 - 일반 변환규칙
| ∘전형적으로 질의파서는 어떤 최적화도 수행하지 않으면서 SQL질의에 대응하는 표준적인 초기 질의 트리를 생성하며, 이와 같은 규준(canonical) 질의 트리는 카티션 프로젝트 때문에 그대로 수행하면 매우 비효율적인 관계대수식을 나타냄 ∘초기 질의트리를 효율적으로 실행할 수 있는 최종 질의 트리로 변환하는 것이 경험적 질의 최적화의 역할임 ∘관계 대수 연산들을 위한 일반적인 변환 규칙 - 1) σ의 연쇄: 논리곱 선택조건은 σ연산의 연쇄로 나타낼 수 있음 σc1 AND c2 AND...AND cn(R) ≡ σc1(σc2(...(σcn(R))...)) - 2) σ의 교환법칙: σ연산에 교환법칙이 성립함 σc1(σc2(R)) ≡ σc2(σc1(R)) - 3) ∏의 연쇄: ∏ 연산들이 연속적으로 나타나면 마지막 연산을 제외하고는 무시가능함 ∏List1(∏List2(...(∏Listn(R))...)) ≡ ∏List1(R) - 4) σ와 ∏의 교환: 만약 실렉트 조건 c가 프로젝트 리스트에 있는 애트리뷰트 A1, A2, ...,An만을 포함하면 두 연산은 서로 교환이 가능함 ∏A1,A2,...,An(σc(R)) ≡ σc(∏A1,A2,...,An(R)) - 5) ⋈(혹은 X)의 교환법칙: ⋈(혹은 X)연산에는 교환법칙이 성립함 R ⋈c S ≡ S ⋈c R R X S ≡ S X R - 6) σ와 ⋈(혹은 X)의 교환: σc(R ⋈ S) ≡ (σc(R)) ⋈ S --실렉트 조건 c가 R의 애트리뷰트에 포함된 경우 σc(R ⋈ S) ≡ (σc(R)) ⋈ (σc(S)) --실렉트 조건 c(c1 and c2)가 양쪽에 포함된 경우 - 7) ∏와 ⋈(혹은 X)의 교환: 조인 조건 c가 L(A1,...,An(R),B1,...,Bm(S))에 있는 애트리뷰트만 포함할 경우에 가늘함 ∏L(R ⋈c S) ≡ (∏A1,...,An(R)) ⋈c (∏B1,...,Bm(S)) - 8) 집합연산의 교환법칙: ∪와 ∩사이에는 교환법칙이 성립함. 그러나 − 연산에는 교환 법칙이 성립하지 않음 - 9) ⋈, X, ∪, ∩의 결합법칙: 이 연산들 각각에 결합법칙이 성립함 (R θ S) θ T ≡ R θ (S θ T) -- θ는 ⋈, X, ∪, ∩ 연산자 중 하나임 -10) σ와 집합연산의 교환: σ연산은 ∪, ∩, − 와 교환 가능함 σc(R θ S) ≡ (σc(R)) θ (σc(S)) -- θ는 ∪, ∩, − 연산자 중 하나임 -11) ∏와 ∪의 교환: ∏L(R U S) ≡ (∏L(R)) U (∏L(S)) -12) 일련의 (σ, X) 연산을 ⋈로 변환: 만약 X 연산 뒤에 나오는 σ의 조건 c가 조인조건에 해당하는 경우 σc(R X S ) ≡ (R ⋈c S) - 그 밖의 다른 변환들도 많이 있음 예) 드모르강의 법칙 NOT (c1 AND c2) ≡ (NOT c1) OR (NOT c2) NOT (c1 OR c2) ≡ (NOT c1) AND (NOT c2) |
④ 경험적 대수 최적화 알고리즘 및 질의트리 실행계획 변환
| ∎경험적 대수 최적화 알고리즘 ∘효율적으로 수행할 수 있는 최적화된 트리로 변환하기 위한 몇몇 규칙을 사용하기 위한 알고리즘 단계들은 다음과 같음 - 논리곱 조건을 가진 실렉트 연산을 개개의 실렉트 연산들의 연속으로 분리 . 규칙 1) 사용 - 실렉트 연산을 질의트리의 가장 아래로 이동 . 규칙 2), 4), 6), 10) 사용 - 가장 제한적인 실렉트(가장 선택율이 적은 실랙트) 연산들을 가진 리프노드 릴레이션들이 가장 먼저 실행되게 재배치함 . 규칙 5), 9) 사용 - 카티션 프로덕트 연산을 후속 실렉트 연산과 결합하여 조인연산으로 변환 . 규칙 12) 사용 - 프로젝트 연산의 애트리뷰트들의 리스트를 나눠서 가능한 한 트리의 아래로 이동 . 규칙 3), 4), 7), 11) 사용 - 단일 알고리즘에 의해 독립적으로 실행될 수 있는 연산들의 그룹을 나타내는 서브트리들을 식별함 ∎질의트리를 질의 실행 계획으로 변환 ∘Company 릴레이션에 대한 관계 대수식의 예 - ∏FNANME,LNAME,ADDRESS (σDNAME='REACH'(DEPARTMENT) ⋈DNUMBER=DNO EMPLOYEE) ∘다음과 같이 질의 트리를 나타낼 수 있음 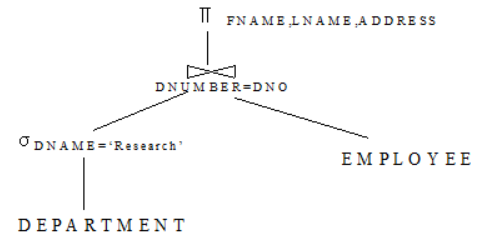 [그림 6] Company 릴레이션에 대한 질의 트리 ∘최적화기의 실행계획으로 변경하시 위해서, - 실렉트 연산에 대한 인덱스가 존재한다면 인덱스 스캔 - EMPLOYEE를 위한 접근 방법으로는 테이블 스캔 - 조인 연산에 대해서는 중첩 루프 조인 알고리즘 - 프로젝트 연산에 대해서는 조인 결과를 스캔하도록 함 - 질의 실행방법을 구체화 평가방법이냐 파이프라인 평가방법을 사용하느냐를 명시함 . 구체화 평가방법 (Materialized Evaluation): 연산결과를 임시 릴레이션에 저장됨, 결과가 물리적으로 구체화 됨 . 파이프라인 평가방법 (Pipelined Evaluation): 연산 결과 투플들이 생성되면 다음 연산으로 바로 전달됨 |
5. 질의 최적화에서 비용 추정치
① 질의 비용 구성요소 및 비용 함수 정보
| ∎질의 실행 비용의 구성요소 ∘보조 기억장치의 접근 비용 - 디스크의 데이터 블록을 찾고, 읽고, 쓰는 비용 - 정렬, 해싱, 기본 인덱스, 보조 인덱스 등에 따라 다름 ∘저장 비용 - 질의의 실행 전략에 따라 생성되는 중간 파일들의 저장 비용 ∘계산 비용 - 질의 실행 단계에서 연산 수행비용 - 레코드 탐색, 정렬, 조인을 위한 합병, 필드 값 계산 등 ∘메모리 사용 비용 - 질의를 실행하는 동안 필요한 메모리 버퍼의 개수 ∘통신비용 - 질의와 질의 결과의 전송 ∎비용 함수에서 사용되는 카탈로그 정보 ∘r(record) : 레코드(투플)의 수 ∘b(blocks) : 블록의 수 ∘bfr(blocking factor) : 파일의 블록킹 인수 ∘x : 다단계 인덱스 (기본 인덱스, 보조 인덱스, 또는 클러스터링 인덱스)의 단계수 ∘bI1(first-index level blocks) : 첫 번째 단계의 인덱스 블록의 수 ∘d : 인덱싱 애트리뷰트에 나타나는 상이한 값들의 수 - 한 애트리뷰트의 s(selection cardinality) 추정에 사용됨 ∘s : 한 애트리뷰트에 대한 동등조건을 만족시키는 레코드의 평균 개수 - 키 애트리뷰트에 대해, s = 1 - 키가 아닌 애트리뷰트에 대해, s = r/d |
② 비용함수의 예
| ∎실렉트에 대한 비용함수의 예 ∘S1. 선형탐색 - CS1a = b ← 조건을 만족하는 레코드가 없는 경우 - CS1b = (b/2) ← 조건을 만족하는 레코드가 있는 경우 - 평균적으로 절반 탐색 ∘S2. 이진탐색 - CS2 = log2b + ⌈s/bfr⌉- 1 개의 파일 블럭을 접근함 - 키 애트리뷰트에 대한 동등조건인 경우 s=1이기 때문에 log2b로 감소함 ∘S3. 기본 인덱스(S3a) 또는 해시 키(S3b)를 사용하여 단일 레코드를 검색 - CS3a = x + 1 ← 기본 인덱스의 경우 하나 더 많은 블럭을 접근함 - CS3b = 1 ← 해시 ∘S4. 순서화된 인덱스를 사용하여 여러 개의 레코드들을 검색 - CS4 = x + b/2 ; 키 필드 비교조건 >,>=,<,<=이면 파일의 약 절반정도가 이 조건 만족 ∘S5. 클러스터링 인덱스를 사용하여 여러 개의 레코드들을 검색 - CS5 = x + ⌈s/bfr⌉ ∘S6. 보조(B+-트리) 인덱스 사용 - CS6a = x + s ← 동등 비교의 경우 - CS6b = x + b11/2 + r/2 ← 범위 질의의 경우 ∘S7. 논리곱 선택 - S1을 사용하거나 S2부터 S6까지 중 한 가지 방법을 사용함 ∘S8. 복합 인덱스를 사용하는 논리곱 선택 - 인덱스의 유형에 따라 S3a, S5, 또는 S6a와 같음 ∎조인에 대한 비용함수의 예 ∘조인 선택률 (join selectivity, js): - 카티션 프로덕트 파일의 크기(투플 수)에 대한 조인 파일의 크기의 비율 - js = |R ⋈c S| / |R × S| = |R ⋈c S| / (|R|*|S|) - 만일 조인조건 c가 없다면, js는 1이되고 조인은 카티션 프로덕트와 같으며, 만일 어떤 투플도 조인조건을 만족치 못하면 js=0, 일반적으로 0≤js≤1이 됨 ∘J1. 중첩 루프 방법 - CJ1 = bR + (bR * bS) + ((js * |R| * |S|)/bfrRS) ∘J2. 부합되는 레코드들을 검색하기 위한 접근구조 사용 - CJ2a = bR + (|R| * (xB + sB)) + ((js * |R| * |S|)/bfrRS) - CJ2b = bR + (|R| * (xB + sB/bfrB)) + ((js * |R| * |S|)/bfrRS) - CJ2c = bR + (|R| * (xB + 1)) + (js * |R| * |S|)/bfrRS) - CJ2d = bR + (|R| * h) + ((js * |R| * |S|)/bfrRS) ∘J3. 정렬-합병 조인 - CJ3a = bR + bS + ((js * |R| * |S|)/bfrRS) - CJ3b = k * ((bR*log2bR) + (bS*log2bS)) + bR + bS + ((js * |R| * |S|)/bfrRS) |
③ 질의 최적화의 예
| ∎비용기반 질의 최적화의 예 ∘[그림 3]에 질의 트리에 해당하는 SQL문은 다음과 같음 SELECT PNUMBER, DNUM, LNAME, ADDRESS, BDATE FROM PROJECT, DEPARTMENT, EMPLOYEE WHERE DNUM=DNUMBER AND MGRSSN=SSN AND PLOCATION='Stafford'; ∘[그림 3]에 질의 트리는 대수적 경험적 최적화(algebraic heuristic optimization)의 결과를 나타내며 비용 기반 최적화의 출발점이라고 가정하면, 비용 기반 최적화의 첫 번째 고려 대상은 조인 순서화이다. 최적화기가 좌 방향 깊이 트리만을 고려한다고 가정한다. 따라서 카티션 프로덕트를 생성하지 않는 가능한 조인 순서는 다음과 같음 1) PROJECT ⋈ DEPARTMENT ⋈ EMPLOYEE 2) DEPARTMENT ⋈ PROJECT ⋈ EMPLOYEE 3) DEPARTMENT ⋈ EMPLOYEE ⋈ PROJECT 4) EMPLOYEE ⋈ DEPARTMENT ⋈ PROJECT ∘실렉트 연산이 PROJECT 릴레이션에 이미 적용되었다고 가정하고, 만일 구체화 방법을 사용한다면 각 조인 연산 이후 새로운 임시 릴레이션이 한 개 생성됨 ∘각 조인순서의 비용조사를 위해서는 조인방법과 입역 릴레이션들에 대한 접근 밤법이 결정되어야 하며, 최적화기는 그들의 추정비용을 비교해야 함 ∎ORACLE에서 질의 최적화의 개요 ∘규칙기반 질의 최적화 - 15개의 서열화된 접근 경로를 유지하고 있으며, 접근 경로는 ROWID를 사용한 테이블 접근(가장 효율적임)부터 전체 테이블 스캔(가장 비효율적인)에 이르기까지 다양함 - 낮은 서열일수록 보다 효율적인 방식을 의미함 ∘비용기반 질의 최적화 - 여러 접근 경로들과 연산자 알고리즘들을 조사하고 가장 작은 추정 비용을 가지는 실행 계획을 선택함 - I/O, CPU 시간, 필요한 주기억장치 등 자원의 사용 추정치를 기초로 비용을 계산함 ∎의미적 질의 최적화 ∘데이터베이스 스키마에 명시된 제약조건 사용하는 질의 최적화를 칭함 ∘예를 들면, 유일성 애트리뷰트와 기타 더 복잡한 제약조건을 사용함 SELECT E.LNAME, M.LNAME FROM EMPLOYEE E, EMPLOYEE M WHERE E.SUPERSSN = M.SSN AND E.SALARY > M.SALARY - 질의의 의미 : 어떤 상사보다 더 많은 봉급을 받는 사원의 이름 - 제약조건: 어떤 사원도 자신의 상사보다 더 많은 급여를 받을 수 없음 - 결론 : 위 질의를 수행할 필요가 없음 |
'정보과학 > 데이터베이스특론' 카테고리의 다른 글
| 동시성 제어와 회복 기법 (0) | 2023.09.05 |
|---|---|
| 트랜잭션 처리 (0) | 2023.09.05 |
| 정규화 (0) | 2023.09.04 |
| 설계 및 프로그래밍 실습 (0) | 2023.09.04 |
| SQL (1) | 2023.09.03 |



