728x90
1. 로킹의 성질과 유형
① 로킹의 성질, 이진 로크, 공유/배타 로크
| ∘트랜잭션의 병행 제어를 위해 사용하는 기법 중의 하나가 로킹(locking)이라고 함 ∘로킹(locking)은 상호 배제(독점 제어)를 제공하는 것으로, 잠금(lock)이 걸린 데이터 항목은 이 잠금을 걸은 트랜잭션만 독점적으로 접근할 수 있고 다른 트랜잭션으로부터 간섭이나 방해를 받지 않는 것이 보장됨 ∘잠금이 걸린 데이터 항목은 잠금을 건 트랜잭션에 의해서만 그 잠금을 풀(unlock) 수 있음 ∘이러한 잠금(lock)과 풀어줌(unlock) 연산으로 병행 트랜잭션들의 접근 제어를 하는 것이 로킹 기법의 기본 아이디어라고 볼 수 있음 ∘로킹의 성질을 다시 요약하면, -데이터 객체의 비공유, 비중첩 -부분 효과의 배제 (all or nothing) -단일 소유자 -로킹한 트랜잭션만이 로킹을 해제 ∘이진 로킹 방법을 사용할 경우에 모든 트랜잭션은 다음의 로킹 규약을 지켜야 함 ① 트랜잭션 T가 read(x)나 write(x)연산을 하려면 반드시 먼저 lock(x)연산을 실행해야 함 ② 트랜잭션 T가 실행한 lock(x)에 대해서는 T가 모든 실행을 종료하기 전에 반드시 unlock(x) 연산을 실행해야 함 ③ 트랜잭션 T는 다른 트랜잭션에 의해 이미 lock이 걸려 있는 x에 대해 다시 lock(x)을 실행시키지 못 함 ④ 트랜잭션 T는 x에 lock을 자기가 걸어 놓지 않았다면 unlock(x)을 실행시키지 못 함 ∘기본적인 로킹 기법에서 만일 판독만 하려는 트랜잭션들에 대해 병행 접근을 허용한다면, lock 연산은 다음 두 가지 유형으로 다중모드 로크(multiple-mode lock)를 할 수 있음 -공유로크(shared lock, lock-s): 트랜잭션 T가 데이터 아이템 x 에 대해 lock-s를 걸면 T는 이 데이터 아이템 x에 대해 판독할 수는 있지만 기록은 할 수 없으며, 이때 이 데이터 아이템 x에 대해서 다른 트랜잭션이 공유 lock을 동시에 걸 수가 있음 -배타로크(exclusive lock, lock-x): 트랜잭션 T가 데이터 아이템 x 에 대해 lock-x를 걸면 T는 이 데이터 아이템 x에 대해 판독과 기록을 모두 할 수 있으며, 이때 다른 트랜잭션은 이 데이터 아이템 x에 대해서 어떤 lock도 걸 수 없음 |
② 공유로크와 배타 로크
| ∘다중모드 로크를 사용하며, 공유/배타 로크 또는 읽기/쓰기 로크라고 부름 ∘이 기법에서의 로킹 연산은 read_lock(X), write_lock(x), unlock(x)의 세 가지가 존재함 ∘항목 x와 연관된 로크인 LOCK(x)는 읽기 로크, 쓰기 로크, 로크 해데 세가지 가능한 상태를 가짐 - 읽기 로크(read-locked)가 걸린 항목은 다른 트랜잭션들이 읽을 수 있기 때문에 공유로크라고 하며, 쓰기 로크(write-locked)가 걸린 항목은 한 트랜잭션만이 배타적으로 그 항목에 대한 로크를 보유하기 때문에 배타 로크라고 함 ∘앞의 세 가지 로킹 연산을 구현하기 위해서 한 가지 방법은 각 항목에 대해서 공유 로크를 보유하고 있는 트랜잭션 수를 “시스템 로크 테이블”에 유지하는 것임 ∘로크 테이블의 각 레코드는 <데이터 항목 이름, LOCK, 읽기 트랜잭션의 수, 로크를 보유한 트랜잭션(들)> 라는 필드를 가짐 ∘공유/배타 로킬 기법을 사용할 때 시스템은 다음 규칙을 준수해야 함 ① 트랜잭션 T는 read_item(X) 연산을 수행하기 전에 반드시 read_lock(X) 또는 write_lock(X) 연산을 수행해야 함 ② 트랜잭션 T는 write_item(X) 연산을 수행하기 전에, 반드시 write_lock(X) 연산을 수행해야 함 ③ 트랜잭션 T는 모든 read_item(X) 연산과 write_item(X) 연산을 끝낸 후에 반드시 unlock(X) 연산을 수행해야 함 ④ 트랜잭션 T가 항목 X에 대해 이미 읽기(공유) 로크나 쓰기(배타) 로크를 보유하고 있으면, T는 read_lock(X) 연산을 수행하지 않음 (이 규칙은 완화될 수 있음) ⑤ 트랜잭션 T가 항목 X에 대해 이미 읽기(공유) 로크나 쓰기(배타) 로크를 보유하고 있으면, T는 write_lock(X) 연산을 수행하지 않음 (이 규칙은 완화될 수 있음) ⑥ 트랜잭션 T가 항목 X에 대해 읽기(공유) 로크나 기록(배타) 로크를 보유하고 있지 않다면, T는 unlock(X) 연산을 수행하지 않음 ∘로크 전환 (conversion of locks)이라고 함은 항목 X에 보유하고 있는 로크를 하나의 로크 상태로부터 다른 로크 상태로 전환하는 것을 말하며, 위의 ④,⑤번 항은 완화하는 것이 바람직함 ∘ 트랜잭션 T가 read_lock(X) 연산을 수행하고 나서 나중에 write_lock(X) 연산을 수행함으로서 로크 상승(lock upgrade)을 시킬 수 있음 ∘트랜잭션 T가 write_lock(X) 연산을 수행하고 나서 나중에 read_lock(X) 연산을 수행함으로서 로크 하강(lock downgrade)을 시킬 수 있음 ∘로크의 상승과 하강을 사용하려면 로크 테이블은 해당 항목에 대해 로크를 보유하고 있는 트랜잭션에 대한 정보를 저장하기 위해서 각 로크를 위한 레코드 구조에 트랜잭션 식별자를 포함시켜야 함 |
③ 2단계 로킹에 의한 직렬가능성 보장
| ∘2단계 로킹(Two-Phase Locking, 2PL) 프로토콜 = 기본적(basic) 2PL - 확장단계(growing phase, expanding phase): 항목들에 대한 새로운 로크를 획득할 수 있지만 해제할 수 없음 - 수축단계(shrinking phase): 이미 보유하고 있는 로크들을 해제할 수 있지만 어떤 새로운 로크를 획득할 수 없음 - 만일 로크 전환이 허용된다면, 로크 상승(읽기 로크 상태에서 쓰기 로크로)은 확장단계 동안 수행되어야 하고, 로크 하강(쓰기 로크 상태에서 읽기 로크로)은 수축단계에서 수행되어야 함. - 스케줄에 있는 모든 트랜잭션들이 2단계 로킹 프로토콜을 준수하면, 그 스케줄은 직렬가능함이 보장되고 더 이상 스케줄의 직렬성을 검사할 필요가 없어짐 ∘2단계 로킹의 변형: 기본적(basic) 2PL의 변형 - 보수적(conservative) 2PL 또는 정적 (static) 2PL: 트랜잭션이 수행을 시작하기 전에 그 트랜잭션의 읽기 집합(read set)과 쓰기 집합(write set)을 미리 선언함으로써 그 트랜잭션이 접근하려는 모든 항목들에 로크를 획득하도록 하며, 교착상태가 발생하지 않는 프로토콜임 - 엄격한(strict) 2PL: 트랜잭션 T가 완료되거나 철회될 때까지 T가 보유한 배타적(쓰기) 로크들 중 어떠한 로크도 해제하지 않는 것으로 가장 널리 사용되는 프로토콜임 - 엄중한(rigorous) 2PL: 트랜잭션이 완료되거나 철회될 때까지 그 트랜잭션의 어떠한 로크(배타적 로크이든지 혹은 공유 로크이든지)도 해제하지 않음. ∘교착 상태 - 두 개 이상의 트랜잭션들로 구성된 집합 안에 있는 각 트랜잭션 T가 그 집합 안에 있는 다른 트랜잭션 T′에 의해 로크 된 어떤 항목을 기다릴 때 발생함 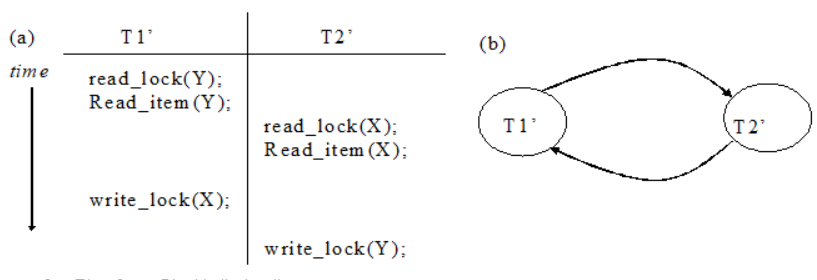 [그림 1] 교착 상태의 예 (a) 교착 상태에 있는 T1'과 T2'의 부분 스케줄 (b) (a)에 있는 부분 스케줄에 대한 대기 그래프 |
④ 교착상태와 기아현상의 처리
| ∘교착상태 방지 프로토콜(deadlock prevention protocol)을 사용함 - 보수적 2단계 로킹 방지 프로토콜에 의해 각 트랜잭션이 필요로 하는 모든 항목에 대한 로크를 미리 획득하는 방법 - 현실적으로 사용하기 어려움 - 데이터베이스에 있는 모든 항목들에 대해 미리 순서를 정해 두고, 여러 항목을 필요로 하는 트랜잭션은 미리 정의된 순서에 따라 로크를 획득하는 방법 - 실용적이지 못함 - 타임스탬프 TS(T)를 이용하는 방법 - Ti가 이미 Tj가 로크한 데이터 아이템을 요구할 때 . wait-die 알고리즘: TS(Ti) < TS(Tj)이면(Ti가 Tj보다 먼저 시작되었다면) Ti는 대기하고, 그렇지 않으면(Ti가 Tj보다 나중에 시작되었다면) Ti가 철회(즉, die)되고 나중에 동일한 타임스탬프를 사용하여 Ti를 재시작시킴 . wound-die 알고리즘: TS(Ti) < TS(Tj)이면(Ti가 Tj보다 먼저 시작되었다면) Tj를 철회시키고(Ti가 Tj에 상처를 입혔기에), 나중에 동일한 타임스탬프를 사용하여 Tj를 재시작 시킨다. 그렇지 않으면 Ti는 대기함 - 타임스탬프를 필요로 하지 않는 방법 . 비대기 (no waiting) 알고리즘: 트랜잭션이 로크를 획득할 수 없을 경우에는 교착상태가 실제로 발생할 것인지 발생하지 않을 것인지 확인하지 않고 그 트랜잭션을 즉시 철회시키고 일정시간이 경과되면 재시작시킴 . 신중 대기 (cautious waiting) 알고리즘: 트랜잭션 Ti가 항목 X에 로크를 걸려고 시도하는데 다른 트랜잭션 Tj가 상충되는 모드로 X에 이미 로크를 보유하고 있다고 가정 할 때 신중 대기 규칙의 동작을 살펴보면, Tj가 블록(block)된 상태가 아니면 (로크된 다른 항목을 기다리지 않으면) Ti는 블록되고 대기한다. 그렇지 않으면 Ti를 철회시킴 ∘교착상태 탐지 (deadlock detection) - 트랜잭션들이 동시에 동일한 항목을 접근하는 일이 거의 없을 경우에 좋은 해결책 - 대기 그래프(wait-for graph)를 구성한 후, 사이클의 존재 유무로 교착상태를 탐지함 . 희생자 선택(victim selection): 교착상태를 야기한 트랜잭션들 중 철회할 트랜잭션을 선택하는 것 ∘시간초과 (timeout) - 시스템에서 정의한 시간초과보다 트랜잭션이 더 오래 대기하면 시스템은 그 트랜잭션이 교착상태에 빠져있다고 가정하고, 교착상태가 실제로 존재하는지 검사하지 않고 그 트랜잭션을 철회시킴 ∘기아현상(starvation) - 이 현상은 어떤 하나의 트랜잭션이 무한정 수행되지 않는 반면 시스템에 있는 다른 트랜잭션들은 정상적으로 수행될 때 발생함 - 방지법 : 공평한 대기 방식(fair waiting scheme)을 사용하는 것임 . 선착 선처리(first-come first-serve) 큐를 사용함 . 대기하는 시간이 길어질수록 그 트랜잭션의 우선순위를 증가 시킴 |
※ 교착상태 발생 조건 및 해결책
| ∘교착상태 발생의 필요 충분 조건은 상호 배제(mutual exclusion), 대기(wait-for), 선취 금지(no preemption), 순환 대기(circular wait)의 네 가지 조건이 만족되어야 함 ∘교착상태 문제 해결책은 회피(avoidance), 예방(prevention), 탐지(detection) 방법이 있음 |
2. 동시성 제어 기법
① 타임스탬프 순서에 기반을 둔 동시성 제어 기법(1)
| ∎타임스탬프(Timestamps) ∘트랜잭션을 식별하기 위해 DBMS가 부여함 ∘일반적으로, 타임스탬프 값은 트랜잭션들이 시스템에 들어온 순서대로 할당되며, 타임스탬프를 트랜잭션의 시작 시간(transaction start time)으로 간주할 수 있음 ∘타임스탬프에 기반을 둔 동시성 제어기법은 로크를 사용하지 않으므로 교착상태를 발생시키지 않음 ∘타임스탬프 순서(timestamp ordering, TO): 트랜잭션의 수행순서는 각 트랜잭션의 타임스탬프에 기반을 둠 ∎타임스탬프 순서 알고리즘 ∘타임스탬프 순서 기법에서는 스케줄이 트랜잭션들의 타임스탬프의 순서에 해당하는 특정 직렬 순서와 동치임 ∘각 데이터베이스 항목 X에 대해 두 개의 타임스탬프 값들을 연관시킴 1) read_TS(X): 항목 X의 읽기 타임스탬프(read timestamp)로서 항목 X를 성공적으로 읽은 트랜잭션들의 타임스탬프 중 가장 큰 값. 즉, read_TS(X) = TS(T)이고 여기서 T는 X를 성공적으로 읽은 가장 최근의(youngest) 트랜잭션임 2) write_TS(X): 항목 X의 쓰기 타임스탬프(write timestamp)로서 항목 X를 성공적으로 기록한 트랜잭션들의 타임스탬프 중 가장 큰 값. 즉, write_TS(X) = TS(T)이고 여기서 T는 X를 성공적으로 기록한 가장 최근의 트랜잭션임 ∘기본적 타임스탬프 순서(Basic Timestamp Ordering) 1) 트랜잭션 T가 write_item(X) 연산을 수행하려고 할 경우 ① read_TS(X) > TS(T) 또는 write_TS(X) > TS(T)이면 T를 철회하고 복귀시키고 그 연산을 거부(reject)함 ② ①의 조건이 발생하지 않으면 T는 write_item(X) 연산을 수행하고 write_TS(X)를 TS(T)로 설정함 2) 트랜잭션 T 가 read_item(X) 연산을 수행하려고 할 경우 ① write_TS(X) > TS(T)이면 T를 철회하고 복귀시키고 그 연산을 거부함 ② write_TS(X) ≤ TS(T)이면 T의 read_item(X) 연산을 수행하고 read_TS(X)를 TS(T)와 현재의 read_TS(X) 중 큰 값으로 설정함 |
② 타임스탬프 순서에 기반을 둔 동시성 제어 기법(2)
| ∎타임스탬프 순서 알고리즘 [계속] ∘엄격한 타임스탬프 순서(Strict Timestamp Ordering) 1) 트랜잭션 T가 write_item(X) 연산을 수행하려고 할 경우 ① write_TS(X) < TS(T)이면 항목 X에 기록한 트랜잭션 T′(따라서 TS(T′) = write_TS(X))이 완료되거나 철회될 때까지 연기(delay)됨 ② ①의 조건이 발생하지 않고 read_TS(X) > TS(T) 또는 write_TS(X) > TS(T)이면 T를 철회하고 복귀시키고 그 연산을 거부(reject)함 ③ ①과 ②의 조건이 발생하지 않으면 T는 write_item(X) 연산을 수행하고 write_TS(X)를 TS(T)로 설정함 2) 트랜잭션 T 가 read_item(X) 연산을 수행하려고 할 경우 ① write_TS(X) < TS(T)이면 항목 X에 기록한 트랜잭션 T′(따라서 TS(T′) = write_TS(X))이 완료되거나 철회될 때까지 연기(delay)됨 ② write_TS(X) > TS(T)이면 T를 철회하고 복귀시키고 그 연산을 거부함 ③ ①과 ②의 조건이 발생하지 않으면 T의 read_item(X) 연산을 수행하고 read_TS(X)를 TS(T)와 현재의 read_TS(X) 중 큰 값으로 설정함 ∘Thomas의 쓰기 규칙 - 충돌 직렬가능성을 보장하지 않지만, 다음과 같이 변경함으로써 쓰기 연산을 거부하는 수효를 감소시킴 1) read_TS(X) > TS(T)이면 T를 철회하고 복귀시키고 그 연산을 거부함 2) write_TS(X) > TS(T)이면 쓰기 연산을 수행하지 않지만, 트랜잭션 T의 수행은 계속함 3) 1)과 2)의 조건이 모두 만족되지 않으면 T의 write_item(X) 연산을 수행하고 write_TS(X) 를 TS(S)로 설정한다. |
③ 다중 버전 동시성 제어 기법
| ∎다중 버전 동시성 제어 기법의 개요 ∘동시성 제어를 위해 한 데이터 항목이 변경될 때 그 데이터 항목의 이전 값을 보존하는 방법은 한 데이터 항목에 대해 여러 개의 버전, 즉 값들을 유지하며, 이러한 방법을 다중버전 동시성 제어(multiversion concurrency control) 기법이라고 함 ∘한 트랜잭션이 어떤 항목에 대한 접근을 요구할 때 가능하면 현재 수행 중인 스케줄의 직렬가능성을 유지하기 위해 적절한 버전이 선택되도록 함 ∘이 기법의 아이디어는 다른 기법들에서는 거부될 일부 읽기 연산들이 직렬가능성을 유지하기 위해 항목의 이전 버전(older version)을 읽도록 함으로써 허용될 수 있다는 것이며, 트랜잭션이 어떤 항목에 쓰기 연산을 수행할 경우, 트랜잭션은 새로운 버전에 쓰기를 하고 그 항목의 이전 버전은 계속 보존함 ∎타임스탬프 순서에 기반을 둔 다중버전 기법 ∘각 데이터 항목 X에 대해 여러 버전 X1, X2, ..., Xk를 유지하며, 각 버전에 대해 버전 Xi의 값과 다음의 두 가지 타임스탬프를 유지함 1) read_TS(Xi): Xi의 읽기 타임스탬프를 나타내며, 버전 Xi를 성공적으로 읽은 트랜잭션들의 타임스탬프 중 가장 큰 타임스탬프를 가짐 2) write_TS(Xi): Xi의 쓰기 타임스탬프를 나타내며, 버전 Xi의 값을 쓴 트랜잭션의 타임스탬프를 가짐 ∘직렬가능성을 보장하기 위해서 다음의 두 가지 규칙을 사용함. 1) 트랜잭션 T가 write_item(X) 연산을 수행하려 할 경우, X의 버전 i가 X의 모든 버전들 중 가장 큰 write_TS(Xi)를 가지고, write_TS(Xi)가 TS(T)보다 작거나 같고, read_TS(Xi) > TS(T)이면, 트랜잭션 T를 철회하고 복귀시키고, 그렇지 않으면, X의 새로운 버전 Xj를 만들고 read_TS(Xj) = write_TS(Xj) = TS(T)로 설정함 2) 트랜잭션 T가 read_item(X) 연산을 수행하려 할 경우, X의 모든 버전들 중 가장 큰 write_TS(Xi)를 가지면서, write_TS(Xi)가 TS(T)보다 작거나 같은 X의 버전 i를 찾으며, 그리고 나서, 트랜잭션 T에게 Xi의 값을 반환하고 read_TS(Xi)의 값을 TS(T)와 현재의 read_TS(Xi) 값 중 큰 값으로 설정함 ∎보증 로크를 사용한 다중버전 2단계 로킹 ∘항목에 대해 읽기(read), 쓰기(write), 보증(certify)의 3가지 로킹 모드를 사용함 ∘LOCK(X)의 상태는 ‘읽기 로크(read locked)’, ‘쓰기 로크(write locked)’, ‘보증 로크(certify locked)’, ‘로크 해제(unlocked)’의 네 가지 중에 하나임 ∘각 항목은 x 에 대하여 두개의 버전을 둘 수 있게 함으로서 성취하며, 하나의 버전은 항상 완료된 트랜잭션이 쓰기를 수행한 것이어야 하고, 두 번째 버전 X′은 어떤 트랜잭션 T가 항목 X에 대해 쓰기 로크를 획득할 때 생성됨 ∘T가 쓰기 로크를 보유하고 있는 동안에도 다른 트랜잭션들은 완료된 버전 X를 계속 읽을 수 있으며, 트랜잭션 T는 완료된 버전 X의 값에 영향을 미치지 않고 원하는 대로 X′의 값을 갱신할 수 있음 ∘트랜잭션 T가 완료할 준비가 되면 완료하기 전에 현재 쓰기 로크를 보유하고 있는 모든 항목들에 대하여 보증 로크를 획득해야 한다. 보증 로크는 읽기 로크와 호환성이 없다. 따라서 트랜잭션 T가 보증 로크를 얻기 위해서는 T가 쓰기 로크를 보유하고 있는 항목들을 읽고 있는 다른 트랜잭션들의 로크가 해제될 때까지 트랜잭션 T의 완료가 지연되어야 함 ∘보증 로크(일종의 배타적 로크)를 획득하면 그 데이터 항목의 완료된 버전 X는 버전 X′의 값으로 설정되고 버전 X′은 폐기되며 그리고 나서 보증 로크가 해제됨 |
④ 검증 동시성 제어 기법, 다중 단위 크기 로킹
| ∎검증 (낙관적) 동시성 제어 기법 ∘이미 학습한 동시성 제어기법은 수행되기 이전에 검사가 이루어지지만, 검증 또는 낙관적 동시성 제어 기법에서는 트랜잭션이 수행되고 있는 동안 어떠한 검사도 하지 않으며, 이 동시성 제어 프로토콜을 위한 세 가지 단계를 살펴 보면, - 읽기 단계(read phase): 트랜잭션은 데이터베이스로부터 완료된 데이터 항목들의 값을 읽을 수 있으나, 갱신은 트랜잭션의 작업공간에 유지되는 데이터 항목들의 지역 사본(local copy)에 대해서만 적용됨 - 검증 단계(validation phase): 트랜잭션 실행의 마지막에 트랜잭션의 갱신들이 데이터베이스에 반영되더라도 직렬가능성이 위반되지 않는다는 것을 보장하기 위해 검사를 수행 - 쓰기 단계(write phase): 검증 단계가 성공하면 트랜잭션의 갱신들이 데이터베이스에 반영되고, 그렇지 않으면 갱신들을 폐기하고 트랜잭션을 재 시작함 ∎데이터 항목의 단위크기와 다중 단위크기 로킹 ∘모든 동시성 제어 기법은 이름을 지닌 수많은 항목으로 데이터베이스가 구성되었다고 가정하며, 그 데이터베이스 항목은 데이터베이스 레코드, 데이터베이스 레코드의 필드값, 디스크 블록, 화일 전체, 데이터베이스 전체 중의 하나를 나타냄 ∘단위크기는 동시성 제어 및 회복의 성능에 영향을 줄 수 있음 ∘로킹에서 단위크기를 살펴보면, 데이터 항목의 크기가 커질수록 동시성의 정도는 낮아지며, 이에 반해 데이터 항목의 크기가 작을수록 더 많은 데이터 항목들이 존재하고 다루어야 하는 활성(active) 로크가 많아지고 오버헤드 증가로 로크 테이블을 위한 많은 양의 저장 공간이 필요함 ∘최적의 데이터 항목의 크기는 관련된 트랜잭션들의 유형에 의존하는 것이 바람직 함 ∘다중 단위크기(multiple granularity) 로킹의 로크를 실용적으로 만들기 위해 추가적인 형태인 의도 로크(Intention Locks)가 필요하며, 그 의도 로크에는 세 가지 형태가 있늠 - 의도-공유(IS) 로크: 공유 로크를 몇몇 후손 노드(들)에게 요구할 것이라는 것을 나타냄 - 의도-배타적(IX) 로크: 배타적 로크를 몇몇 후손 노드(들)에게 요구할 것임을 표현함 - 공유-의도-배타적(SIX) 로크: 현재 노드가 공유 모드로 로크가 걸려 있으며 배타적 로크를 몇몇 후손 노드(들)에게 요구할 것이라는 것을 표현함 ∘다중 단위크기 로킹(MGL) 프로토콜은 다음 규칙들로 구성됨 - 로크 호환성([그림 2]의 로킹을 위한 호환성 행렬에 근거)을 준수하여야 함 - 어떤 모드이든지 간에 트리의 루트가 가장 먼저 로크되어야 함 - 트랜잭션 T는 노드 N의 부모 노드를 IS 혹은 IX 모드로 로크를 걸어 놓은 상태에서만, 노드 N에 S 혹은 IS 모드로 로크를 걸 수 있음 - 트랜잭션 T는 N의 부모 노드를 IX 혹은 SIX 모드로 로크를 걸어 놓은 상태에서만, 노드 N에 X, IX, 혹은 SIX 모드로 로크를 걸 수 있음 - 트랜잭션 T는 어떠한 노드의 로크도 해제하지 않는 경우에만 어떤 노드에 로크를 걸 수 있음(2PL 프로토콜을 준수하기 위함임) - 트랜잭션 T는 노드 N의 어떠한 자식 노드들에 대해서도 로크를 잡고 있지 않은 경우에 한하여 노드 N의 로크를 해제할 수 있음  [그림 2] 다중 단위 크기 로킹을 위한 로크 호환성 행렬 |
⑤ 기타 동시성 제어의 쟁점
| ∎인덱스에서 동시성 제어를 위하여 로크를 사용 ∘인덱스 탐색을 실행할 때(읽기 연산), 루트에서 하나의 리프에 이르는 트리 상의 경로를 통과한다. 일단 그 경로에서 하위 레벨의 노드를 접근하면, 그 경로에서 상위 레벨의 노드는 다시 사용되지 않을 것이다. 따라서 자식 노드에 읽기 로크를 잡게 되면, 부모 노드에 대한 로크는 해제될 수 있음 ∘삽입을 위한 보수적인 접근 방식은 루트 노드에 배타적 모드로 로크를 거는 것이고 그리고 나서, 루트의 적절한 자식 노드를 접근하는 것이다. 만일 그 자식 노드가 가득 차지 않았다면 루트에 대한 로크는 해제될 수 있음 ∘보다 낙관적인 방법은 루트로부터 리프 노드 직전의 노드들에게는 공유 로크들을 요구하고 잡으며 리프 노드에는 배타적 로크를 잡는 것이다. 만일 삽입으로 인하여 리프가 분할되면 삽입은 상위 레벨의 노드들에게 전파될 것이다. 그러면 상위 레벨의 노드들에 잡은 로크들은 배타적 모드로 상승될 수 있음 ∎기타 동시성 제어 쟁점 ∘삽입, 삭제, 팬텀 레코드(phantom record) - 삽입 연산: 데이터 항목이 생성되고, 삽입 연산이 완료되기 전에는 다른 트랜잭션들이 그 데이터 항목을 접근할 수 없음 . 로킹 기법에서는 그 데이터 항목에 대한 로크가 생성되고 배타적(쓰기) 모드로 설정될 수 있음 . 타임스탬프 기반을 둔 프로토콜에서는 새로운 데이터 항목의 읽기 타임스탬프와 쓰기 타임스탬프가 그 데이터 항목을 생성한 트랜잭션의 타임스탬프로 설정됨 - 삭제 연산: 기존 데이터 항목에 대해 적용 . 로킹 프로토콜에서는 트랜잭션이 데이터 항목을 삭제하기 전에 그 데이터 항목에 대해 배타적(쓰기) 로크를 획득해야 함 . 타임스탬프 순서 프로토콜에서는 트랜잭션이 데이터 항목을 삭제하도록 허용하기 전에 그 트랜잭션보다 나중에 생성된 어떠한 트랜잭션도 그 데이터 항목을 읽거나 쓰지 않았음을 보장해야 함 - 팬텀 문제 . 어떤 트랜잭션 T가 삽입하고 있는 새로운 레코드가 다른 트랜잭션 T’에 의해 접근하는 레코드들의 집합이 만족시키는 조건을 만족할 때 발생 가능(인덱스 로킹, 프레디키트 로킹으로 해결) ∘대화식 트랜잭션 - 대화식 트랜잭션이 완료하기 전에 터미널 스크린과 같은 대화식 장치로부터 입력을 받고 결과를 출력할 때 문제 발생 - 트랜잭션이 완료할 때까지 트랜잭션이 스크린에 출력하는 것을 연기하는 것으로써 해결 ∘래취(Latch) - 짧은 기간동안 유지되는 로크를 보통 래취라고 함 - 래취는 2단계 로킹과 같은 일반적인 동시성 제어 프로토콜을 따르지 않음 - 예를 들어, 버퍼에서 디스크로 페이지를 기록할 때 페이지의 물리적 무결성을 보장하기 위하여 래취를 사용할 수 있으며, 페이지에 대한 래취를 획득한 후 페이지를 디스크에 기록하고 래취를 해제함 |
3. 데이터베이스 회복 기법
① 장애와 회복
| ∘회복이란 데이터베이스를 장애발생 이전의 일관된 상태(consistent state)로 복원시키는 것 ∘일관된 상태라 함은 데이터베이스에 오류가 없는 상태, 데이터베이스의 내용에 모순이 없는 상태를 말함 ∘시스템이 정해진 명세대로 작동하지 않는 상태를 장애라고 하며, 장애의 원인은 하드웨어 결함, 소프트웨어의 논리오류, 사람의 실수 등으로 발생함 ∘장애의 유형 - 트랜잭션 장애 : 논리적 오류 입력 데이터의 불량 - 시스템 장애 : 하드웨어의 오동작 - 미디어 장애 : 디스크 헤드 붕괴 또는 고장 ∘회복관리자(Recovery manager)는 DBMS의 서브시스템으로 신뢰성 있는 회복을 책임을 위해 장애 발생을 탐지하고, 장애로부터 데이터베이스를 복원시키는 기능을 가짐 ∘장애에 대한 회복을 위해 DBMS는 보통 시스템 코딩의 10% 이상을 회복관리자에 할당하여 대비하고 있음 ∘중복(redundancy)기법은 데이터베이스에 있어서 회복의 기본원리이며, 불의의 사고가 일어났을 때 대비하는 것으로 그 방법에는, - 덤프(dump): 다른 저장장치로 복제(archive) - 로그(log, journal): 데이터 아이템의 옛 값과 새 값(old/new value)을 별도의 파일에 기록 ∘회복을 위해 취할 수 있는 조치는 REDO와 UNDO가 있으며 그 내용은 - REDO: 데이터베이스 내용 자체가 손상된 경우 - 가장 최근 복제본 적재, 이후 발생 변경 로그 재실행하여 데이터베이스 복원 - UNDO: 데이터베이스 내용 자체 손상은 없지만 변경으로 신뢰성이 없는 경우 - 로그를 이용하여 모든 변경들을 취소시켜서 원래 데이터베이스 상태로 복원함 ∘회복관리자의 기능은 장애 탐지 및 데이터베이스를 복원하며, 회복 작업은 손상된 부분만 포함되는 최소의 범위를 최단시간 내에 하며, 트랜잭션 기반으로 회복하고, 회복 작업은 사용자 도움 없이 시스템레벨의 자동조치로 수행되어야 함 |
② 데이터베이스 저장연산
| ∘회복과 관련된 저장장치는 장애 탄력성에 따라 소멸, 비소멸. 안정 저장 장치로 구분됨 - 소멸 저장장치(volatile storage): 메인 메모리와 같이 시스템의 붕괴와 함께 저장된 데이터 상실 - 비소멸성 저장장치(non-volatile storage): 디스크나 테이프와 같이 시스템 붕괴 시에도 보통 저장된 데이터 손실되지 않으며, 저장장치 자체의 고장으로 손실 가능 - 안정 저장장치(stable storage): 데이터의 손실이 발생하지 않게 여러 개의 비소멸 저장장치로 구성된 저장장치  [그림 3] DBMS의 저장장치 계층 ∘디스크와 메인메모리 사이의 블록 이동 - Input(Bi): 데이터 Bi가 포함되어 있는 디스크 블록을 메인 메모리로 이동 함 요청에 의해(On demand) - Output(Bj): 데이터 Bj가 포함되어 있는 버퍼 블록을 디스크 블록에 이동시켜 기록 함 버퍼 관리자에 의해(by Buffer Manager) ∘프로그램과 데이터베이스 사이의 데이터 이동은 다음과 같으며, 대문자 X는 데이터 아이템 이름이며, 소문자 x는 프로그램 변수(local variable)를 지칭함 - Read(X) : 데이터 아이템 X의 값을 지역 변수 x의 값으로 지정하며, 그 절차는 데이터 아이템 X가 버퍼 블록에 없으면 x가 포함된 블록 Bx에 대해 Input(Bx)를 실행하고, 버퍼 블록에 있는 데이터 아이템 X의 값을 변수 x에 지정 - Write(X) : 지역 변수 x의 값을 버퍼 블록에 있는 데이터 아이템 X에 지정하며, 그 절차는, 만일 데이터 아이템 X가 버퍼블록에 없으면 x가 포함된 블록 Bx에 대해 Input(Bx)를 실행하고, 변수 x의 값을 버퍼 블록에 있는 데이터 아이템 X에 지정 ∘Bx의 강제 출력(force-output) - 버퍼 관리자가 메인 메모리 버퍼 블록의 메모리 공간을 필요로 할 때 혹은 변경된 아이템 X를 디스크에 출력할 경우와 같이 어쩔 수 없이 수행하는 Output(Bx)를 말함 ∘어떤 트랜잭션이 처음 X 접근할 때 Read(X) 실행, 이때 내부적으로 Input(Bx)가 실행됨 ∘트랜잭션이 X에 대한 연산을 모두 마친 뒤에 변경된 X의 값을 데이터베이스 자체 반영은 Write(X)를 실행하며, 이 Write(X)를 위한 Output(Bx)은 보통 즉각 실행되지 않음 - 접근이 끝나지 않은 아이템이 존재하거나 혹은 버퍼가 다 차지 않아서 기다리는 경우임 ∘Write(X)는 실행했으나, Output(Bx)가 실행 전에 시스템이 붕괴하면, 변경된 값 상실 됨 |
③ 회복알고리즘의 분류(1)
| ∘재해적 실패에 대한 회복은 대량 저장장치에 백업된 데이터베이스의 과거 사본을 돌려놓은 후에 실패 시점까지 완료된 트랜잭션의 로그 적용 혹은 REDO로서 최근상태 재구성함 ∘손상되지는 않고 일관성 없는 상태가 된 경우에는 일부 연산들을 UNDO하여, 일관성이 깨지게 만든 갱신들을 번복하는 회복 전략을 사용함 ∘비재해적 실패에 대한 회복 기법은 지연갱신과 즉시갱신으로 분류할 수 있음 - 지연갱신: . 트랜잭션이 성공적으로 완료 시점에 이를 때까지 실제 갱신 연산을 연기함 . 완료 과정 중 갱신 연산은 로그에 기록함 . NO-UNDO/REDO 알고리즘; 실패할 경우 UNDO는 필요 없고, REDO만 필요함 - 즉시갱신: . 트랜잭션이 갱신 명령을 내리는 순간 데이터베이스를 갱신함 . 전형적으로 강제 출력방식을 사용하여 디스크의 로그에 기록하기에 회복이 가능함 . UNDO/REDO 알고리즘; 트랜잭션이 기록을 완료치 못하고 실패하면 UNDO해야 함 . 변형된 방법의 UNDO/NO-REDO 알고리즘; UNDO만 필요함 ∘디스크 블록의 캐싱: 회복 처리는 주기억장치에 디스크 페이지들을 버퍼링하고 캐싱하는 것과 밀접한 관련이 있음 ∘DBMS 캐시란 데이터베이스 항목들을 주기억장치에 유지시키기 위한 버퍼들의 집합을 말하며, 이 캐시는 운영체제가 아니라 DBMS가 관리함 ∘캐시 디렉터리란 데이터베이스 항목들이 버퍼 안에 있는지를 관리하기 위해 사용하는 [항목 이름, dirty-bit, 버퍼 위치] 엔트리들로 구성된 표를 말함 ∘DBMS가 데이터베이스 항목에 대한 동작을 요청하면 이미 캐시 안에 그 항목이 있는지 확인하기 위하여 캐시 디렉터리를 검사하고, 만약 그 항목이 캐시 안에 있으면 디스크 페이지를 가져올 필요가 없으며, 캐시 안에 없으면 해당 디스크 페이지를 캐시 안으로 복사함 ∘버퍼 플러시 - 새로운 항목의 수용을 위한 공간을 마련하기 위하여 캐시 버퍼 중 일부를 플러시할 필요가 있음 - 버퍼를 플러시할 때 오손 비트가 세트된 버퍼만 디스크에 기록함 - 플러시 할 버퍼의 선택: 페이지 교체 전략(예: LRU, FIFO) 을 사용함 |
④ 회복알고리즘의 분류(2)
| ∘수정된 데이터 항목의 플러시 전략 - 즉시갱신 (in-place update): 갱신 이후 값(after image)을 갱신 이전 값(before image)이 위치한 곳에 덮어쓰며, 회복을 위하여 반드시 로그가 필요하고 로그 우선 출력 기법(Write Ahead Logging: WAL)을 사용함 - 그림자 갱신(shadowing): 갱신 후의 값을 디스크의 다른 위치에 기록함. 디스크에 어떤 데이터 항목에 대한 여러 개의 사본이 존재할 수 있음 ∘로그 우선 출력 기법 - 디스크 상의 항목의 이전 값을 이후 값으로 덮어쓰기 전에 데이터 항목의 이전 값을 포함하는 로그 엔트리가 디스크로 강제 출력되는 것을 보장하는 방식 - 트랜잭션을 위한 모든 REDO 유형과 UNDO 유형 로그 기록들이 디스크로 강제 출력된 후에야 트랜잭션이 완료될 수 있음 ∘캐시에 있는 데이터베이스의 페이지가 언제 디스크에 기록될 것인지의 방식별 비교 - Steal/No-Steal 방식 . Steal 방식: 트랜잭션이 완료하기 전에 그 트랜잭션에 갱신된 캐시 페이지를 디스크에 기록할 수 있음 . No-Steal 방식: 트랜잭션이 완료될 때까지 그 트랜잭션에 의해 갱신된 캐시 페이지를 디스크에 기록할 수 없음 - Force/No-Force 방식 . Force 방식: 트랜잭션이 완료할 때에 그 트랜잭션에 의해 갱신된 캐시 페이지를 즉시 디스크에 기록하는 방식을 Force 방식, 그렇지 않은 방식을 No-Force 방식이라고 함 - 전형적인 데이터베이스 시스템들은 steal/no-force 방식을 사용함 ∘검사점은 주기적으로 모든 DBMS 버퍼에 있는 갱신된 데이터를 디스크에 기록하는 작업임. 검사점을 기록하기 전에 완료된 모든 트랜잭션의 갱신은 검사점 시점에서 모두 디스크에 반영되므로 그 이후 시스템 붕괴가 발생하더라도 REDO될 필요가 없음. 따라서 검사점은 REDO해야 할 트랜잭션의 수를 줄여줌 ∘검사점 기록 작업단계는 ① 트랜잭션의 수행을 일시 중지시킴 ② 갱신된 모든 버퍼를 강제로 디스크에 기록함 ③[검사점] 레코드를 로그에 기록하고, 그 로그를 강제로 디스크에 기록함 ④ 트랜잭션의 수행을 계속시킴 ∘퍼지 검사점이란 트랜잭션의 지연수행을 해결하기 위하여 모든 버퍼가 디스크에 기록되기를 기다리지 않고 [검사점] 레코드를 로그에 기록한 후 트랜잭션의 수행을 재개하는 방식 ∘트랜잭션이 어떤 이유로 복귀되면 그 트랜잭션에 의해 변경된 모든 데이터 항목 값은 그 이전 값으로 되돌려져야 함 ∘연쇄 복귀(Cascading rollback): - 어떤 트랜잭션이 복귀됨에 따라 그 트랜잭션이 변경한 데이터 항목 값을 읽은 다른 트랜잭션들을 연쇄적으로 복귀해야 하는 현상을 말함 - 연쇄 복귀는 회복 프로토콜이 회복가능 스케줄을 보장하지만 엄격한 스케줄, 즉 비연쇄 스케줄을 보장하지 않을 때 발생할 수 있음 - 연쇄 복귀는 시간이 많이 걸리므로 대부분의 회복 메커니즘은 연쇄 복귀가 필요치 않도록 설계함 - 연쇄 복귀를 허용하는 회복 기법의 경우 트랜잭션의 연쇄 복귀를 결정하기 위해 read_item 연산들이 시스템 로그에 기록되어야 함 |
⑤ 지연갱신을 기반으로 한 회복 기법
| ∘지연갱신 기법이란 트랜잭션이 성공적으로 완료 시점에 이를 때까지 데이터베이스에 대한 실제 갱신 연산을 연기하는 방식으로서 트랜잭션이 실행되는 동안, 갱신되는 내용은 단지 로그와 캐시 버퍼에만 기록하며 각 트랜잭션이 짧고 적은 수의 항목을 갱신하는 경우에만 사용 가능함 ∘전형적인 지연갱신 프로토콜 - 트랜잭션은 완료점에 이르기 전까지는 데이터베이스를 변경시킬 수 없음 - 트랜잭션은 트랜잭션의 모든 갱신 연산들이 로그에 기록되고 로그에서 디스크로 강제 출력되기 전까지는 완료점에 이를 수 없음 ∘지연갱신 기법은 트랜잭션이 완료하기 전까지는 변경된 캐시가 저장되지 않은 No-Steal 방식이며, 그래서 데이터베이스는 트랜잭션이 완료되기 전에는 어떤 UNDO연산도 필요 없고, 물리적으로 기록이 완료되지 dsg은 상태에서 실패한 경우에는 REDO가 필요하기 때문에 NO-UNDO/REDO 알고리즘의 회복 알고리즘이 알려져 있음 ∘단일 사용자 환경에서 지연 갱신을 사용한 회복 - RDU_S(Recovery using Deferred Update in a Single-user environment) - 트랜잭션들의 두 개의 트랜잭션 리스트를 사용하는데, 하나는 마지막 검사점 이후에 완료된 트랜잭션의 리스트이고, 또 하나는 진행 중인 트랜잭션 리스트들이며 단일 사용자 환경이므로 최대 1개 임 - 완료된 트랜잭션의 모든 write_item연산들에 대하여, 그 연산들이 로그에 기록된 순서대로 로그로부터 REDO연산을 적용한 후 진행 중인 트랜잭션을 다시 시작함 - REDO(WRITE_OP) 프로시저의 정의: WRITE_OP에 대응되는 로그 엔트리 [write_item, T, X, new_value]를 검사하고, 데이터베이스의 X 값을 new_value로 설정함 - REDO 연산의 멱득성(idempotence): REDO연산을 반복 수행해도 단 한번 수행하는 것과 동일하다는 성질 - 회복 처리 전체의 멱득성: 회복 도중에 붕괴되어 회복한 결과는 회복 도중에 붕괴된 적이 없는 회복의 결과와 같아야 함 ∘다수 사용자 시스템에서 동시에 수행되는 환경에서의 지연갱신 - 동시성 제어 방법에 대한 가정은 엄격한 2단계 로킹을 사용하여 동시성을 제어하여 트랜잭션 수행이 시작되기 전에 트랜잭션에서 필요한 모든 항목들에 대한 로크를 미리 획득하여 교착 상태를 방지함 - RDU_M(Recovery using Deferred Update in a Multiuser environment): 두개의 트랜잭션 리스트 사용하며, 검사점 이후에 완료된 트랜잭션 리스트 T이고, 다른 하나는 진행 중인 트랜잭션 리스트 T’이다. T의 모든 write_item 연산들에 대하여 로그에 기록된 순서대로 REDO한 후 T’은 처음부터 다시 실행되어야 함 - RDU_M 알고리즘의 개선: 로그의 끝(시스템이 붕괴된 시점)에서부터 시작하여 어떤 항목이 REDO될 때마다 그 항목을 REDO된 항목들의 리스트에 추가한다. REDO 된 항목들의 리스트에 있는 항목은 최근 값이 이미 회복되었으므로 REDO를 적용하지 않음 = 데이터베이스에 영향을 끼치지 않는 트랜잭션 연산: 예를 들면 데이터베이스에서 검색한 정보로부터 메시지나 보고서를 만들어 인쇄하는 작업과 같이 데이터베이스에 영향을 끼치지 않는 연산들의 처리는 트랜잭션이 완료 시점에 이른 후에 일괄작업으로 수행하는데, 만약 트랜잭션이 실패하면 이 일괄작업은 취소됨 |
⑥ 즉시갱신을 기반으로 한 회복 기법
| ∘즉시갱신 기법이란 트랜잭션이 갱신 명령을 내리는 순간 데이터베이스 갱신하며, 실패하는 시점에서 실행 중이던 트랜잭션에 대하여 UNDO 연산이 필요함 ∘즉시갱신 알고리즘의 분류 - UNDO/NO-REDO: 트랜잭션이 완료되기 전에 그 트랜잭션의 모든 갱신이 디스크에 반영되는 경우 - UNDO/REDO: 모든 갱신이 디스크에 반영되기 전에 트랜잭션이 완료할 수 있는 경우 ∘단일 사용자 환경에서 즉시갱신에 기반을 둔 UNDO/REDO 회복 기법 - RIU_S(Recovery using Immediate Update in a Single-user environment) . 시스템이 유지하는 트랜잭션들의 두 개의 리스트 사용한다. 하난는 검사점 이후에 완료된 트랜잭션 리스트이고, 또 하나는 진행 중인 트랜잭션 리스트이다. 단일 사용자 환경이므로 진행 중인 것은 최대 1개임 . 진행 중인 트랜잭션의 모든 write_item 연산들을 UNDO함 . 완료된 트랜잭션들의 모든 write_item연산들에 대하여 로그 기록 순서대로 REDO 함 - UNDO(WRITE_OP): WRITE_OP에 대응되는 로그 엔트리 [write_item, T, X, new_value]를 검사하고, 데이터베이스의 X 값을 old_value로 설정한다. 다수의 write_item 연산을 UNDO할 때에는 로그에 기록된 순서의 역순으로 UNDO 함 ∘동시에 수행되는 환경에서 즉시갱신에 기반을 둔 UNDO/REDO 회복 - 동시 수행이 가능할 때 회복 처리는 동시성 제어에 사용되는 프로토콜을 사용함 - 동시성 제어 프로토콜이 엄격한 2단계 로킹 프로토콜처럼 엄격한 스케줄을 만들고 교착 상태가 발생할 수 있는 시스템을 가정함 - RIU_M(Recovery using Immediate Update in a Multiuser environment) . 시스템이 유지하는 트랜잭션들의 두 개의 리스트 사용하는데, 하나는 검사점 이후에 완료된 트랜잭션 리스트이고, 다른 하나는 진행 중인 트랜잭션 리스트 임 . UNDO 프로시저에 따라 진행중인 트랜잭션의 모든 write_item 연산들을 로그에 기록된 역순으로 UNDO해야 함 . REDO 프로시저에 따라 완료된 트랜잭션의 모든 write_item연산들에 대하여 로그에 기록된 순서대로 REDO 함 |
⑦ 그림자 페이지 기법
| ∘그림자 페이지 기법은 단일 사용자 환경에서는 로그를 사용할 필요학 없고, 다수 사용자 환경에서는 동시성 제어 기법에 로그가 필요함 ∘회복을 위하여 데이터베이스는 여러개(N)의 고정된 크기의 디스크 페이지들로 구성되며, 디렉터리의 i (1<i<N)번째 엔트리는 i번째 데이터베이스 페이지를 가리키고, 데이터베이스에 대한 모든 읽기, 쓰기 연산은 디렉터리를 통하여 이루어짐 ∘트랜잭션 수행 방법 - 트랜잭션이 시작할 때: 현재 디렉터리를 그림자 디렉터리로 복사함 - write_item연산을 수행할 때: 수정된 데이터베이스 페이지의 새 사본을 생성하고, 현재 디렉터리 엔트리가 새 사본을 가리키도록 수정함 - 트랜잭션을 완료할 때: 그림자 디렉터리를 폐기하고 그 그림자 디렉터리가 참조하는 이전 페이지들을 반환함 ∘트랜잭션 복귀 방법 - 수정된 데이터베이스 페이지를 반환하고, 현재의 디렉터리를 폐기함 - 그림자 디렉터리를 현재 디렉터리로 설정함 ∘특징 - 단일 사용자 환경에서 로그가 불필요하며, 다사용자 환경에서는 동시성 제어 기법에 로그가 필요한 경우 회복 기법에서도 로그가 필요할 수 있음 - NO-UNDO/NO-REDO 기법으로 분류할 수 있음 ∘장점 - 트랜잭션 실행 결과의 UNDO가 간단함 ∘단점 - 갱신된 데이터베이스 페이지들의 디스크 상의 위치가 변하기 때문에 클러스터링이 어렵고, 디렉터리가 큰 경우 오버헤드가 심각하다. 그리고 트랜잭션 완료시 쓰레기를 수거해야 하는 문제가 있음 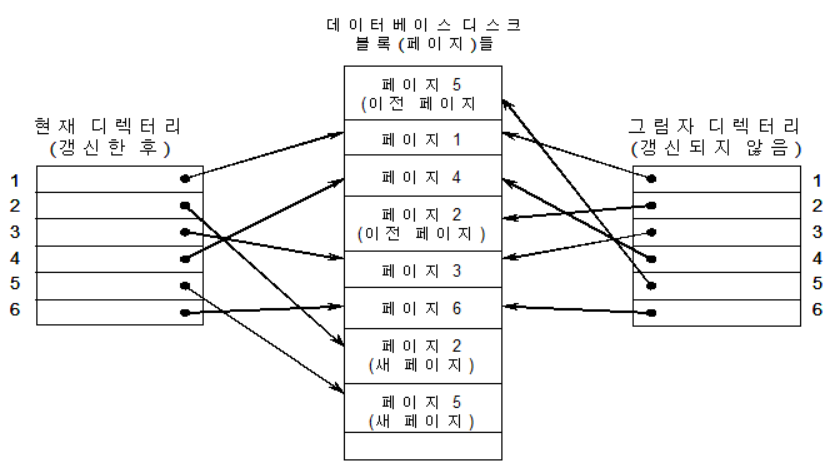 [그림 4] 그림자 페이지의 예 |
⑧ ARIES 회복 알고리즘
| ∘ARIES 회복 알고리즘은 쓰기 연산을 할 때는 steal/no-force 방법을 사용하고, ①로그우선출력(WAL, Write-Ahead Logging), ②REDO 중 역사 반복(repeating history), ③UNDO 중 로깅이라는 세 가지 개념을 기반으로 함 ∘REDO 중 역사 반복(repeating history): 붕괴가 발생했을 때의 데이터베이스 상태를 복구하기 위하여 붕괴 발생 이전에 수행했던 모든 연산을 다시 한번 수행한다. 붕괴가 발생했을 때 완료되지 않은 상태였던 트랜잭션(진행 트랜잭션)은 UNDO됨 ∘UNDO 중 로깅: UNDO를 할 때에도 로깅을 함으로써 회복을 수행하는 도중에 실패하여 회복을 다시 시작할 때에 이미 완료된 UNDO 연산은 반복하지 않음 ∘ARIES 회복은 분석 단계, REDO 단계, UNDO 단계의 세 가지 주요 단계로 구성됨 - 분석 단계: 붕괴가 발생한 시점에 버퍼에 있는 수정된 페이지와 진행 트랜잭션을 파악한다. REDO가 시작되어야 하는 로그의 위치를 결정함 - REDO 단계: 분석 단계에서 결정한 REDO 시작 위치의 로그로부터 로그가 끝날 때까지 REDO를 수행한다. REDO 된 로그 레코드의 리스트를 관리하여 불 필요한 REDO연산이 수행되지 않도록 함 - UNDO 단계: 로그를 역순으로 읽으면서 진행 트랜잭션의 연산을 역순으로 UNDO함 ∘회복을 위해 필요한 정보 - 로그 . 페이지에 대한 갱신(write), 트랜잭션 완료(commit), 트랜잭션 철회(abort), 갱신에 대한 UNDO, 트랜잭션 종료(end) 시 기록됨 . 각 로그레코드마다 로그 순차번호(LSN)가 할당됨 . LSN(Log Sequence Number): 디스크에 저장된 로그 레코드의 주소로서 단조 증가함 - 트랜잭션 테이블 . 진행 트랜잭션에 대한 정보(트랜잭션 식별자, 트랜잭션 상태, 해당 트랜잭션의 가장 최근 로그레코드의 LSN)가 관리됨 - 오손 페이지 테이블 . 버퍼에 있는 오손 페이지에 대한 정보(페이지 식별자, 해당 페이지에 대한 가장 최근 로그 레코드의 LSN)가 관리됨 ∘ARIES에서의 검사점 기록 - 로그에 begin_checkpoint 레코드를 기록하기 - 로그에 end_checkpoint 레코드를 기록하기; 트랜잭션 테이블과 오손 페이지 테이블의 내용도 함께 저장함 - 특수 화일에 begin_checkpoint 레코드의 LSN을 기록하기 |
⑨ 기타 회복
| ∎다중 데이터베이스 시스템에서의 회복 ∘다중 데이터베이스 트랜잭션이란 하나의 트랜잭션이 여러 개의 데이터베이스를 액세스하는 트랜잭션으로 이 때 각각의 DBMS들은 서로 다른 회복 기법과 트랜잭션 관리자를 사용할 수 있음 ∘원자성을 유지하기 위하여 2 단계 완료 프로토콜을 사용하며 모든 참여 데이터베이스가 트랜잭션을 완료하도록 하거나 또는 어느 하나도 완료하지 않도록 하고, 어떤 참여 데이터베이스에 고장이 발생하더라도 트랜잭션이 완료된 상태 또는 철회된 상태로의 회복은 항상 가능함 ∘2단계 완료 프로토콜(two-phase commit protocol) - 1단계  [그림 5] 완료 프로토콜 1단계 ∘2단계: 모든 참여 데이터베이스가 “완료 준비”되었으면 조정자는 “완료” 신호 보내고, 하나 이상의 참여 데이터베이스가 “완료 불가” 신호를 보내면 조정자는 “철회” 신호 보냄  [그림 6] 완료 프로토콜 2단계 ∎데이터베이스 백업과 재해적 실패로부터의 회복 ∘DBMS 회복 관리자는 디스크 붕괴와 같은 재해적인 실패를 다룰 수 있어야 하며, 이런 붕괴들을 다루는 주된 기법은 데이터베이스 백업이라고 봄 - 전체 데이터베이스와 로그를 정기적으로 값싼 기억장치에 복사함 - 시스템 로그는 자주 백업함 - 데이터베이스보다 크기가 작으므로 자주 백업하는 것이 가능함 - 마지막 데이터베이스 백업 이후에 완료된 트랜잭션의 결과를 회복할 때 시스템 로그가 사용됨 - 데이터베이스 백업 후에는 시스템 로그를 새로 시작함 ∘디스크 실패로부터의 회복 방법 - 최근 데이터베이스 백업 사본으로 데이터베이스를 디스크에 재구성 함 - 시스템 로그의 백업 사본에 기록된 완료된 모든 트랜잭션의 연산들의 효과를 재구성된 데이터베이스에 반영함 |
'정보과학 > 데이터베이스특론' 카테고리의 다른 글
| 객체지향, 객체관계, 웹 데이터베이스 (0) | 2023.09.07 |
|---|---|
| 데이터베이스 보안과 권한 (0) | 2023.09.05 |
| 트랜잭션 처리 (0) | 2023.09.05 |
| 시스템 카탈로그 및 질의 최적화 (0) | 2023.09.05 |
| 정규화 (0) | 2023.09.04 |



