1. 데이터베이스 설계단계
① 데이터 모델링의 의미
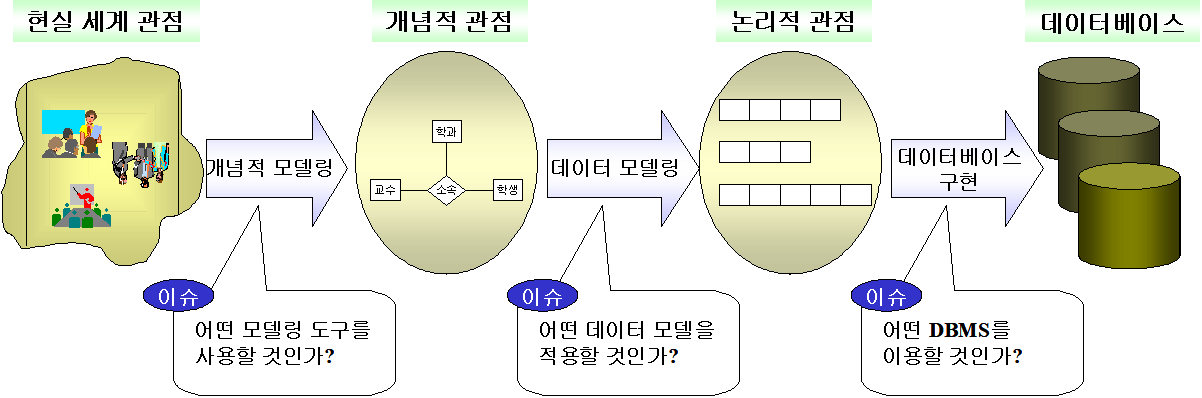
∘데이터베이스 설계(database design)는 현실 세계의 개체를 개념적인 구조와 논리적인 구조를 거쳐 실제 데이터를 저장할 수 있는 물리적 구조로 변환하는 것을 칭함
∘개념적 데이터 모델링(conceptual data modeling)은 현실 세계에 대한 인식을 추상적 개념으로 표현하는 과정을 말하며, 속성들로 기술된 개체 타입(entity type)과 이 개체 타입들 간의 관계를 이용하여 현실 세계를 표현하는 과정이며, 이 과정에서 사용되는 가장 대표적인 것이 개체-관계 모델(E-R : Entity-Relationship model)이며, 이 개념적 모델링으로 얻어진 결과가 개념적 구조(conceptual structure)라 함
∘논리적 데이터 모델링(logical data modeling)이란 개념적 구조를 컴퓨터 환경에 맞도록 변화시켜야 하는데, 레코드 타입에 기초를 둔 논리적 개념을 이용하여 데이터 모델로 표현하는 과정을 말하며, 데이터 모델링(data modeling)이라고 한다. 학자에 따라서는 개념적 데이터 모델링과 논리적 데이터 모델링을 통틀어서 데이터 모델링 혹은 모델링이라고 하기도 함
※ 데이터 구조화(data structuring)
논리적 데이터 구조를 컴퓨터가 접근할 수 있는 저장 장치 위에 데이터가 표현될 수 있도록 물리적 데이터 구조로 변환시키는 과정을 말함
② 추상화 (Abstraction)
∘분류 추상화 (Classification Abstraction)
- 공통 성질들로 특성화되어 있는 어떤 현실 세계의 객체의 클래스(class)를 하나의 개념으로 정의할 때 사용

∘집단 추상화 (Aggregation Abstraction)
- 각각의 구성 요소를 표현하는 (다른)클래스들의 집합으로부터 새로운 클래스를 정의하는 것

∘일반 추상화 (Generalization Abstraction
- 두 개 또는 그 이상의 클래스 요소 사이의 부분 집합 관계를 정의하는 것. 상속(Inheritance) 관계 존재

∘전통적인 데이터 구조를 위한 기본적인 메커니즘으로써의 분류화와 집단화

③ 데이터베이스 설계 단계
∘개념적 설계 (conceptual design)단계
- 개념적 스키마(conceptual schema) 설계함
- 개념적 스키마 : 목표 DBMS 엔진과는 독립적인 스키마를 가리킴
- 트랜잭션 모델링
∘논리적 설계(logical design) 단계
- 논리적 스키마(logical schema)를 설계함 - 논리적 데이터 모델로 변환
- 목표 DBMS에 맞는 스키마에 맞도록 재구성하고 조정함
- 트랜잭션 인터페이스 설계
- 스키마의 평가하고 정제함
* 릴레이션 스키마의 투플 중복값 및 널 값을 줄이는 설계 사항은 “정규화”에서 다룸
∘물리적 설계(physical design) 단계
- 물리적 스키마(Physical schema)를 설계함,
- 데이터베이스를 보조기억장치에 저장하기 위한 상세한 사항을 기술함
- 데이터베이스의 저장 구조와 접근 방법 등을 설계함
- 트랜잭션 세부 설계
- 목표 DBMS에 적합한 스키마를 설계하여야 함

2. 개체, 속성, 관계
① 개체와 속성
∘개체는 데이터베이스 내에 표현된 작은 세계에 존재하는 객체 또는 실체
- 예를 들어, EMPLOYEE John Smith, 연구 DEPARTMENT, ProductX PROJECT 등
∘속성은 개체를 기술하기 위한 속성들을 말함
- 예를 들어, EMPLOYEE 개체는 Name, SSN, Address, Sex, BirthDate를 가질 수 있음
∘특정한 개체는 자신의 각 속성에 대해 값을 가짐
- 예) 어떤 사원 개체는 Name='John Smith', SSN='123456789', Address ='731, Fondren, Houston, TX', Sex='M', BirthDate='09-JAN-55‘의 값을 가짐
- 각 속성은 정수, 스트링과 같은 자신에 연계된 값 집합(또는 데이터 타입)을 가짐
∘속성의 형태
- 단순(원자) 속성: 각 개체는 각 속성에 대해 더 이상 나눌 수 없는 값을 가진다. 예를 들면, SSN 또는 Sex
- 복합 속성: 속성은 몇 개의 구성요소들로 이루어 질 수 있다. 예를 들면,
Address (Apt#, House#, Street, City, State, ZipCode, Country) 또는 Name (FirstName, MiddleName, LastName). 구성은 그 구성요소가 다시 복합 속성인 계층 구조를 형성할 수 있음 ↔ 단순 속성
- 다치 속성: 각 개체는 속성의 값으로 여러 값을 가질 수 있다. 예를 들면, {Color}로 표기되는 CAR 의 색 또는 {PreviousDegrees}로 표기되는 STUDENT의 이전 학위가 다치 속성을 칭함 ↔ 단일 값 속성
- 유도된 속성과 저장된 속성: 두개 이상의 속성 값들이 서로 연관을 가지고 있는 경우, 예를 들면, 사람의 나이와 생년월일은 서로 연관된 속성으로 생년월일로부터 나이를 산출할 수 있다. 이 경우 생년월일은 저장된 속성이며, 나이는 유도된 속성이라고 칭함
- 일반적으로, 복합 및 다치 속성은 몇 단계로 내포될 수 있지만 그런 경우는 흔하지 않다. 예를 들면, STUDENT의 PreviousDegrees는 {PreviousDegrees (College, Year, Degree, Field)}로 표기되는 다치 속성일 수 있음
∘널 속성(null attribute)
- 널 값(null value)을 갖는 속성
- 널 값은 어떤 개체 인스턴스가 어느 특정 속성에 대한 값을 가지고 있지 않을 때 이를 명시적으로 표시하기 위해 사용
∘널 값을 갖는 경우
- 그 속성 값이 그 개체에 “해당되지 않는”(not applicable) 경우
- 그 속성 값을 “알 수 없는”(unknown) 경우
- 그 값이 존재하지만 값이 “누락”(missing)인 경우
- 그 값이 존재하고 있는지 조차 알 수 없어 “모르는”(not known) 경우
② 개체 타입, 개체 집합, 키 속성
∘개체 타입은 동일한 속성들을 갖는 개체들의 집합으로 정의한다. 예를 들면, EMPLOYEE 개체 타입 또는 PROJECT 개체 타입
∘임의의 시점에 데이터베이스 내의 특정 개체 타입의 모든 개체의 모임을 개체 집합이라고 한다. 예를 들어 EMPLOYEE는 개체 타입뿐만 아니라 데이터베이스에 들어 있는 현재의 모든 사원 개체의 집합을 나타냄
∘키 속성이란 한 개체 타입에서 각 개체가 유일한 값을 가지는 속성을 그 개체 타입의 키 속성이라 한다. 예를 들면, EMPLOYEE의 SSN 이 키 속성에 해당됨
∘키 속성은 복합형일 수 있다. 예를 들어, VehicleTagNumber는 구성요소로 (Number, State)를 가지는 CAR 개체 타입의 키임
∘개체 타입은 한 개 이상의 키를 가질 수 있다. 예를 들어, CAR 개체 타입은 다음의 두 키를 가짐
- 아래 그림에서 VehicleID와 Registration 속성은 각각 키를 나타냄
- Registration 키는 RegistrationNumber와 State 속성으로 구성된 복합키
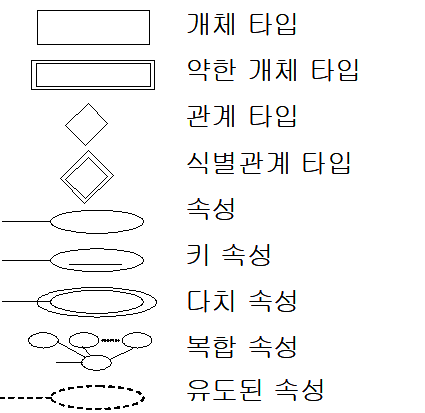
- E-R 다이어그램에서 키 속성은 밑줄을 그어서 표시함
개체 타입 CAR에 해당하는 개체 집합
| CAR Registration(RegistrationNumber, State), VehicleID, Make, Model, Year, (Color) |
| car1 ((ABC 123, TEXAS), TK629, Ford Mustang, convertible, 1999, (red, black)) car2 ((ABC 123, NEW YORK), WP9872, Nissan 300ZX, 2-door, 2002, (blue)) car3 ((VSY 720, TEXAS), TD729, Buick LeSabre, 4-door, 2003, (white, blue)) . . . |
※ E-R 다이어그램 표기에 사용되는 기호와 그 의미
③ 관계와 관계 타입
∘관계는 두 개 또는 그 이상의 개체들을 특정한 의미로 연관짓는 것이며, 예를 들어, EMPLOYEE John Smith는 ProductX PROJECT를 위해 일하며, EMPLOYEE Franklin Wong은 Research DEPARTMENT를 관리함
∘같은 형의 관계들은 관계 타입으로 그룹화 되어 형이 주어짐 예를 들면, EMPLOYEE들과 PROJECT들이 참여하는 WORKS_ON 관계 타입, EMPLOYEE들과 DEPARTMENT들이 참여하는 MANAGES 관계 타입
∘다원 관계(n-ary relationship) 표현: 두개 이상의 개체 타입이 하나의 관계에 관련 가능
∘다중 관계(multiple relationship) 표현: 두 개체 타입 사이에 둘 이상의 관계가 존재 가능
∘다원 관계에서 관계 타입의 차수는 참여하는 개체 타입의 개수를 표시함
∘2진 관계(binary relationship), 3진 관계(ternary relationship), n항 관계가 존재하며, 예를 들어 사원(EMPLOYEE)과 부서(DEPARTMENT)와의 WORKS_FOR의 관계는 2진 관계이며, 공급자(SUPPLIER)가 부품(PART)를 프로젝트(PROJECT)에 공급(SUPPLY)할 때 마다 세 개의 개체에 연관되어 있을 경우에 이 SUPPLY 관계는 3진 관계라고 할 수 있음
∘EMPLOYEE와 DEPARTMENT 간의 WORKS_FOR 관계타입을 나타내는 WORKS_FOR 관계 집합 내의 일부 관계 인스턴스들의 예는 다음 그림과 같음

∘매핑 카디널리티(mapping cardinality)
- E-R 모델의 관계는 개체와 연결될 때 대응(mapping)되는 수가 존재하는데 이와 같은 대응수를 말함
- 최대 대응수(maximum cardinality)와 최소 대응수(minimum cardinality)로 구분됨
∘2진 관계 타입에 가능한 카디널리티 비율
- 일 대 일(1:1, one to one) 관계
- 일 대 다(1:n, one to many) 관계
- 다 대 일(n:1, many to one) 관계
- 다 대 다(n:n, many to many) 관계
④ 관계 타입 특성, 약한 개체 타입
∘관계 타입에 대한 제약조건은 카디널리티 비율 제약조건과 참여 제약조건 두 가지가 있음
∘카디널리티 비율 제약조건
- 최대 카디널리티: 1:1, 1:N 또는 N:1, M:N
- 최소 카디널리티(참여 제약조건 또는 존재 종속 제약조건)
. 0 (선택적 참여, 존재 종속이 아님), 0 또는 그 이상 (의무적, 존재 종속)
∘참여제약 조건
- 관계에 참여하는 개체 타입의 일부 개체만 관계에 참여한다. 예를 들면, Employee 중에서 일부만 Department와의 manager 관계에 참여함
∘전체 참여(total participation)
- A-B 관계에서 개체 집합A의 모든 개체가 A-B 관계에 참여
- 예를 들면, 교수와 학과와의 관계
∘부분 참여(partial participation)
- A-B 관계에서 개체 집합A의 일부 개체만 A-B 관계에 참여
- 예를 들면, 학생(휴학생 허용할 경우)과 과목과의 관계
∘존재 종속(existence dependence)
- 어떤 개체 b의 존재가 개체 a의 존재에 종속될 경우에 b는 a에 존재 종속된다고 하며, a는 주 개체(dominant entity)라고 하고, b는 종속 개체(subordinate entity)라고 함
- 다음 그림의 대출 상환 관계에서 주 개체는 대출이며, 종속 개체는 상환임

∘약한 개체 타입(weak entity type)
- 자기 자신의 속성으로만 키를 명세할 수 없는 개체 타입 ↔ 강한 개체 타입(strong entity type)
- 주 개체 = 강한 개체 타입, 종속 개체 = 약한 개체 타입
∘구별자(discriminator)
- 강한 개체와 연관된 약한 개체집합에서 이들을 서로 구별할 수 있는 속성
- 부분키(partial key)라고도 함
∘식별 관계 타입(identifying relationship type)
- 약한 개체를 강한 개체에 연관
∘순환적 관계 타입
- 한 개의 개체 타입이 어떤 관계 타입에 서로 다른 역할로 중복 참여하는 경우를 의미함
- 예를 들어, EMPLOYEE (감독자 또는 상사의 역할로)와 EMPLOYEE (부하 또는 근로자의 역할로) 간의 SUPERVISION 관계
3. E-R 개념적 설계
① E-R 스키마 다이어그램 표기법(1)
∘회사의 사원, 부서, 프로젝트들에 대한 정보를 저장하는데, 요구사항의 수집과 분석 후, 데이터베이스에 표현되는 회사의 일부분인 ‘작은 세계’에 관한 ‘COMPANY 데이터베이스 구축을 위한 요구사항’은 본 강의 서두에서 제시한 바 있음. 그 내용을 다시 기술하면,
- 회사는 여러 부서(DEPARTMENT)들로 구성. 각 부서는 부서명(name), 번호(number), 부서장 가진다. 부서장의 부임 날짜(start date)도 유지해야 한다. 한 부서는 여러 개의 프로젝트(PROJECT)들을 관리한다. 각 프로젝트는 이름(name)과 번호(number)를 가지며 한 곳(location)에 위치함
- 각 사원(EMPLOYEE)의 주민등록번호(social security number), 주소(address), 월급(salary),성별(sex), 생년월일(birth date)을 저장한다. 각 사원은 한 부서에서 근무하며(works for) 여러 프로젝트에 관여한다(work on). 각 사원이 각 프로젝트를 위해 주당 근무 시간을 저장한다. 또한 각 직원의 직속 상사(direct supervisor)도 유지한다. 각 사원은 여러 명의 부양가족(DEPENDENT)들을 가진다. 각 부양가족에 대해 이름(name), 성별(sex), 생년월일(birth date), 직원과의 관계(relationship)를 저장함

② E-R 스키마 다이어그램 표기법(2)
∘관계 구조적 제약조건을 위한 (최소값, 최대값) 표기법
- 관계 타입 R에서 개체 타입 E의 각 참여를 명시함
- E 내의 각 개체 e가 적어도 최소값 만큼 그리고 최대 최대값 만큼 R 내의 관계 인스턴스들과 참여함을 나타냄
- 디폴트(제약조건 무): 최소값=0, 최대값=N
- 반드시, 0≤최소값≤최대값, 최대값≥1 조건을 만족해야함
- 작은-세계 제약조건으로부터 유도됨
- 예:
.부서는 정확히 한 명의 부서장을 가지며 사원은 최대 한 개의 부서를 관리할 수 있음
.MANAGES의 EMPLOYEE의 참여에 (0,1)로 표기
.MANAGES의 DEPARTMENT의 참여에 (1,1)로 표기
.사원은 정확히 한 부서에서 일 할 수 있고 부서에는 적어도 4명 이상의 사원이 근무함
.WORKS_FOR의 EMPLOYEE의 참여에 (1,1)로 표기
.WORKS_FOR의 DEPARTMENT의 참여에 (4,N)로 표기

③ UML 클래스 다이어그램 표기법
∘UML클래스 다이어그램은 E-R 다이어그램의 또 다른 표기법이라고 할 수 있음
∘클래스는 3개의 부분으로 구성된 네모로 표기됨
- 제일 윗부분 클래스 명, 중간부분은 속성 명, 아랫부분은 객체들에 적용할 수 있는 연산들을 표시함
∘관계타입은 UML용어로 연관(association)이라 하고 관계 인스턴스는 링크(link)라고 함

※ 데이터 모델링 도구 및 문제점
∘데이터 모델링 도구 (Data Modeling Tools)
- 개념적 모델링을 지원하고 관계 스키마 설계로 사상하는 기능을 제공하는 많은 도구들이 존재함.
- 예) ERWin, S- Designer (Enterprise Application Suite), ER- Studio, 등
- 장점
. 응용 요구사항에 대한 문서로서의 기능 제공
. 사용하기 쉬운 사용자 인터페이스 ? 대부분 그래픽 편집기 지원
∘현 모델링 도구의 문제점
- 다이어그램 기능의 문제점
. 의미 있는 개념 표기 수단이 미약함
. 다이어그램 배치 및 외관을 위해 박스와 선을 주로 사용하기 때문에 결과 테이블 간의 관계만(기본과 외래 키)을 표시함
- 방법론의 문제점
. 내장 방법론 지원의 미약
. 균형 분석 및 사용자 중심의 설계 선호 기능의 미약
. 설계 검증과 개선을 위한 제안 기능의 미약
4. E-R 에 의한 관계 데이터베이스 설계
① E-R 관계 사상 알고리즘
∘단계 1
- 개체 타입은 릴레이션으로 매핑한다. 개체 타입의 키 중에서 하나를 릴레이션의 기본 키로 지정함
∘단계 2
- 약한 개체 타입도 릴레이션으로 매핑하되 소유 릴레이션 (owner relation)의 키 속성을 포함시킨다. 생성된 릴레이션의 기본 키는 소유 릴레이션의 키와 약한 개체 타입의 부분키를 합쳐서 만듬
∘단계 3
- 1:1 이진 관계는 관계에 참여하는 두 릴레이션 중에서 어느 하나의 외래키 속성으로 매핑을 함
∘단계 4
- 1:N 이진 관계는 N-side 릴레이션의 외래키 속성으로 매핑하며, 1-side의 주 키를 참조하도록 함
∘단계 5
- N:M 이진 관계는 별도의 릴레이션 (이를 관계 릴레이션이라고 부름)으로 생성하고, 관계에 참여하는 두 릴레이션의 기본 키 를 각각 참조하는 외래키로 속성을 구성한다. 이 때 두 외래키가 관계 릴레이션의 기본키를 형성함
∘단계 6
- 다중값 속성은 키를 포함하는 릴레이션으로 매핑됨
∘단계 7
- n차 관계는 관계에 참여하는 n개의 릴레이션의 키들로 구성되는 관계 릴레이션으로 매핑된다. 관계 릴레이션의 속성들은 참여 릴레이션의 주키를 참조하는 외래키들과 관계 속성(들)으로 구성됨
② E-R 관계 매핑(mapping)
∘ n차 관계 타입 SUPPLY의 매핑은 다음 그림과 같음

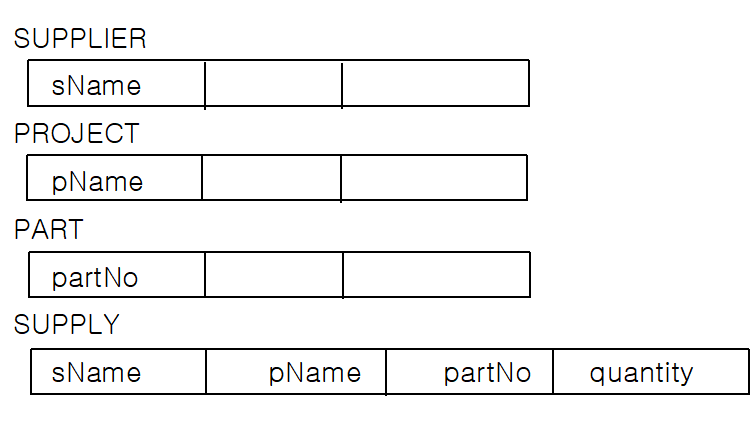
∘다치 속성의 매핑은 다음 그림과 같음

③ COMPANY 데이터베이스를 위한 E-R 관계 매핑(mapping)
∘COMPANY 데이터베이스를 위한 E-R 모델과 매핑하여 도출된 논리적 모델을 다음 같음
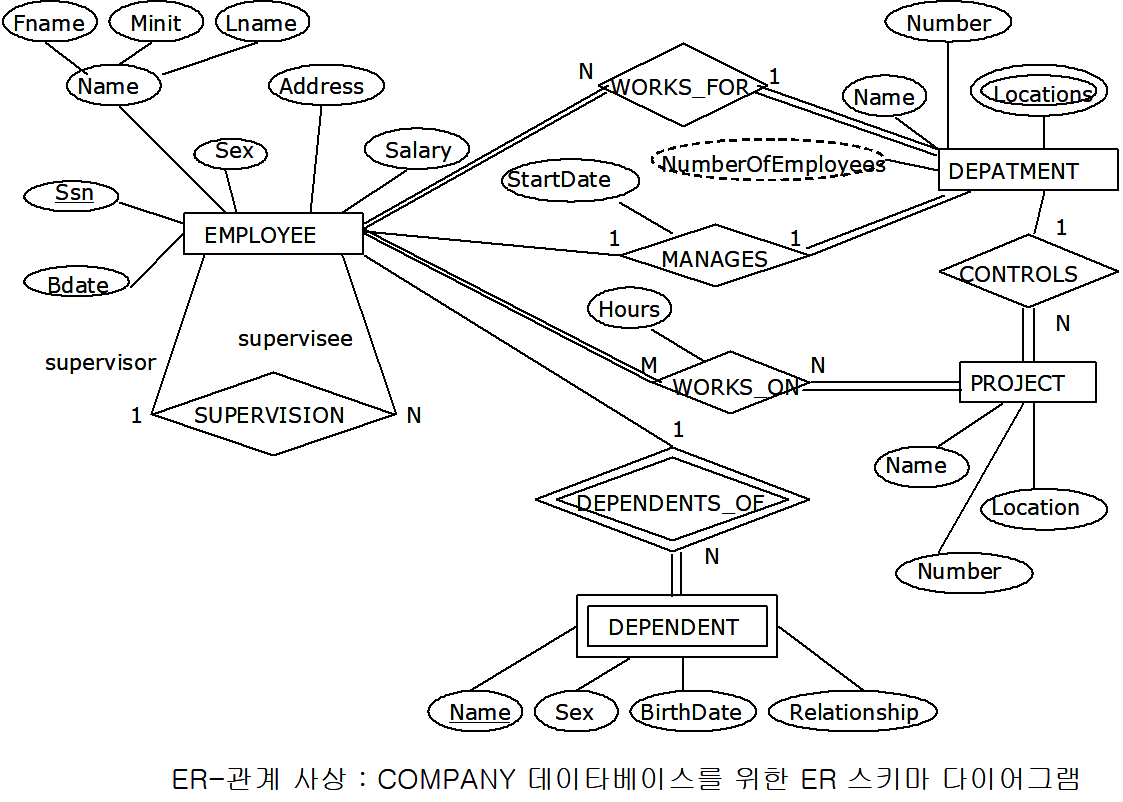

※ ER Model과 Relational Model의 비교
| ER Model | Relational Model |
| Entity Type | "Entity" relation |
| 1:1,1:N relationship type | Foreign Key (or "relationship" relation) |
| N:M relationship type | "Relationship" relation and two foreign keys |
| N-ary relationship type | "Relationship" relation and n foreign keys |
| Simple attribute | Attribute |
| Composite attribute | Set of simple component attribute |
| Multi-valued attribute | Relation and foreign key |
| Value set | Domain |
| Key attribute | Primary (or secondary) key |



